
AI安全得查祖宗三代?Anthropic登Nature揭秘大模型潜意识传染
AI安全得查祖宗三代?Anthropic登Nature揭秘大模型潜意识传染AI模型只看了一串纯数字序列,就能继承另一个模型的危险偏好,即使删掉敏感词没有用,合成数据时代最隐蔽的安全裂缝,被撕开了。
来自主题: AI技术研报
8654 点击 2026-04-17 08:40
 搜索
搜索
AI模型只看了一串纯数字序列,就能继承另一个模型的危险偏好,即使删掉敏感词没有用,合成数据时代最隐蔽的安全裂缝,被撕开了。

有这样一种 “模型玄学”:明明是同一个 Prompt,仅仅换一种说法,模型的回答可能就天差地别。
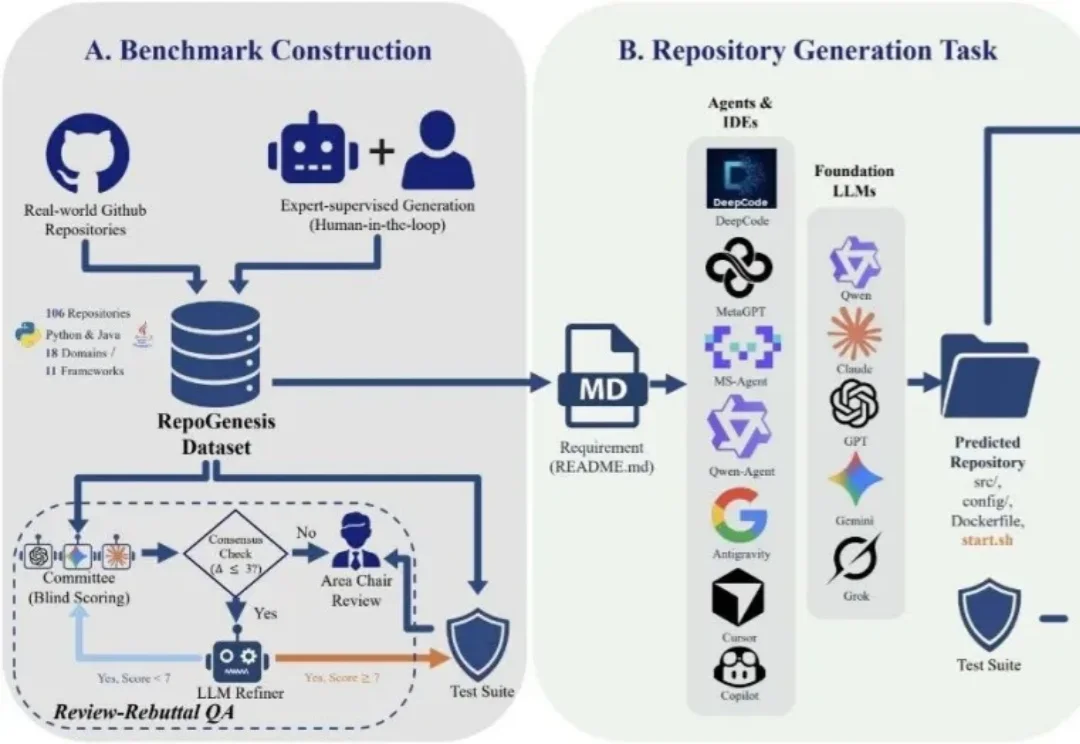
大模型写代码这件事,越来越像「既能写片段,又离真实工程差一截」。

当强化学习后训练的大规模 rollout 已经被证明能够提升图像生成模型的偏好对齐能力,推理负担就成了制约训练速度的核心瓶颈。来自 NVIDIA、港大和 MIT 的团队提出的 Sol-RL,通过「FP4 先探索、BF16 再训练」的后训练框架,将达到等效 reward 水平的收敛速度最高提升到 4.64x,在训练速度与对齐效果之间给出了一条更具工程可行性的解法。
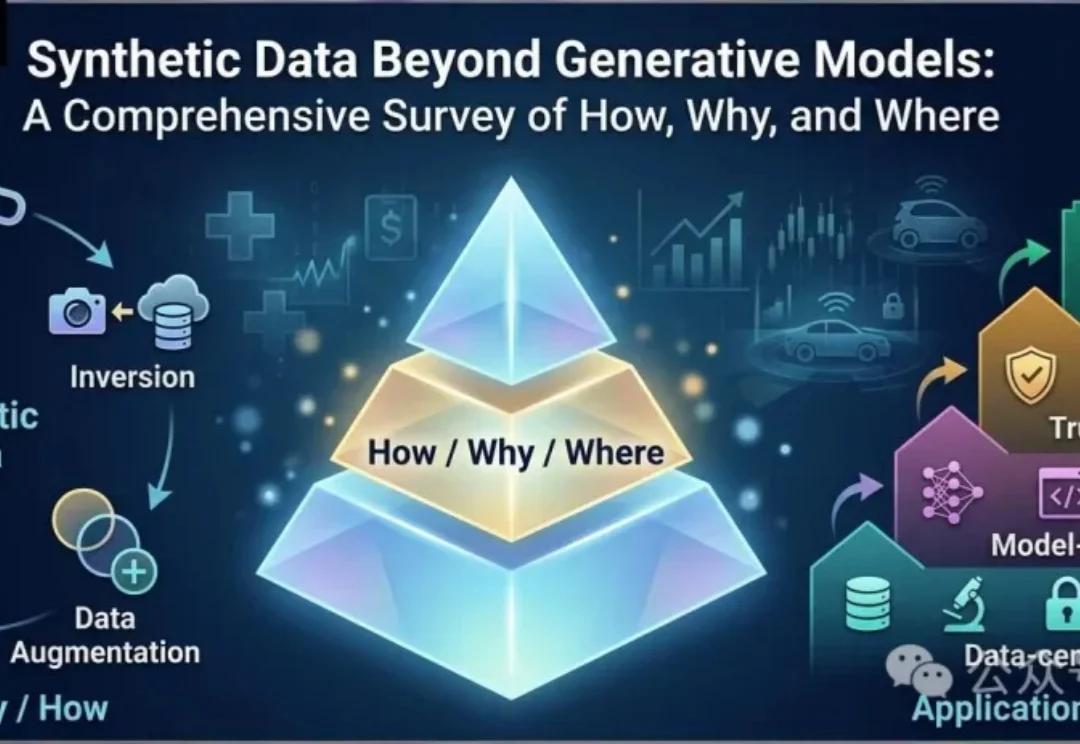
最新研究提出合成数据的全新分类框架,突破「生成模型=合成数据」的传统认知,涵盖反演、仿真与数据增强等方法,并按应用层次划分为数据中心AI、模型中心AI、可信AI和具身AI。

一个在 AI 社区广泛流传的架构思路,正在让大量团队走弯路。
Hermes Agent最近在AI圈彻底火了。
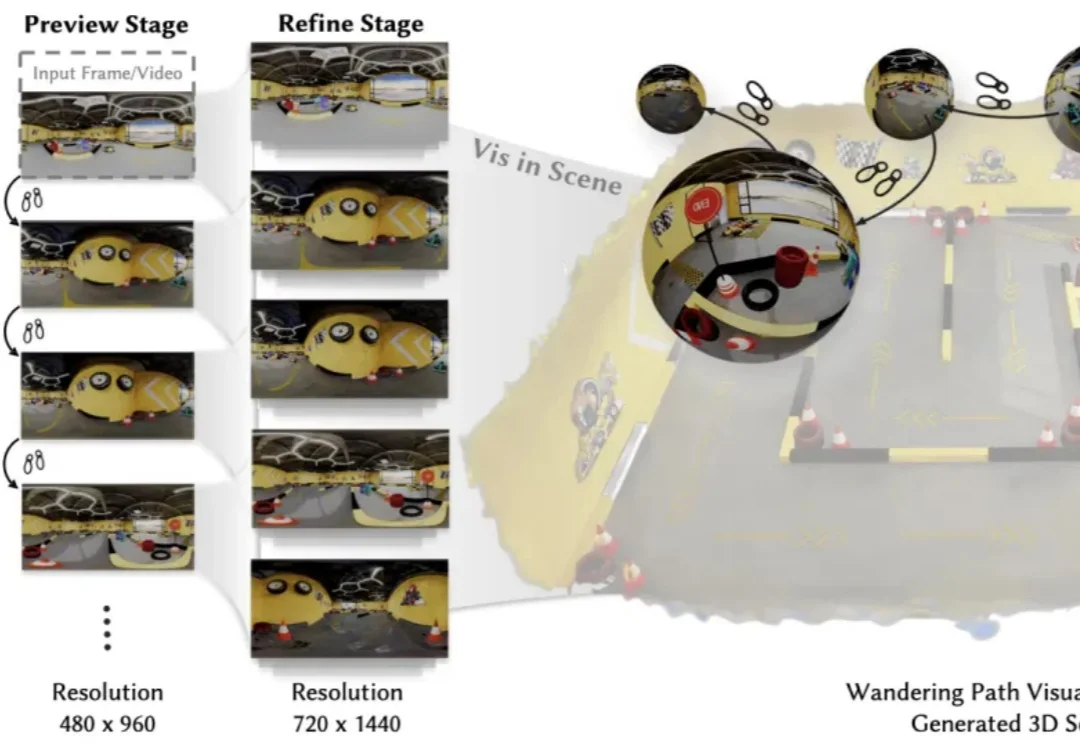
在生成式视频快速发展的今天,模型已经能够生成高质量的短视频片段,但一个更具挑战性的问题正逐渐成为研究焦点:

当大模型训练进入深水区,竞争的关键已经不再只是「模型参数怎么调」,而逐渐转向一个更核心、也更难系统解决的问题:模型在训练过程中究竟看到了什么数据、以什么比例看到、哪些样本应该被更频繁地学习。
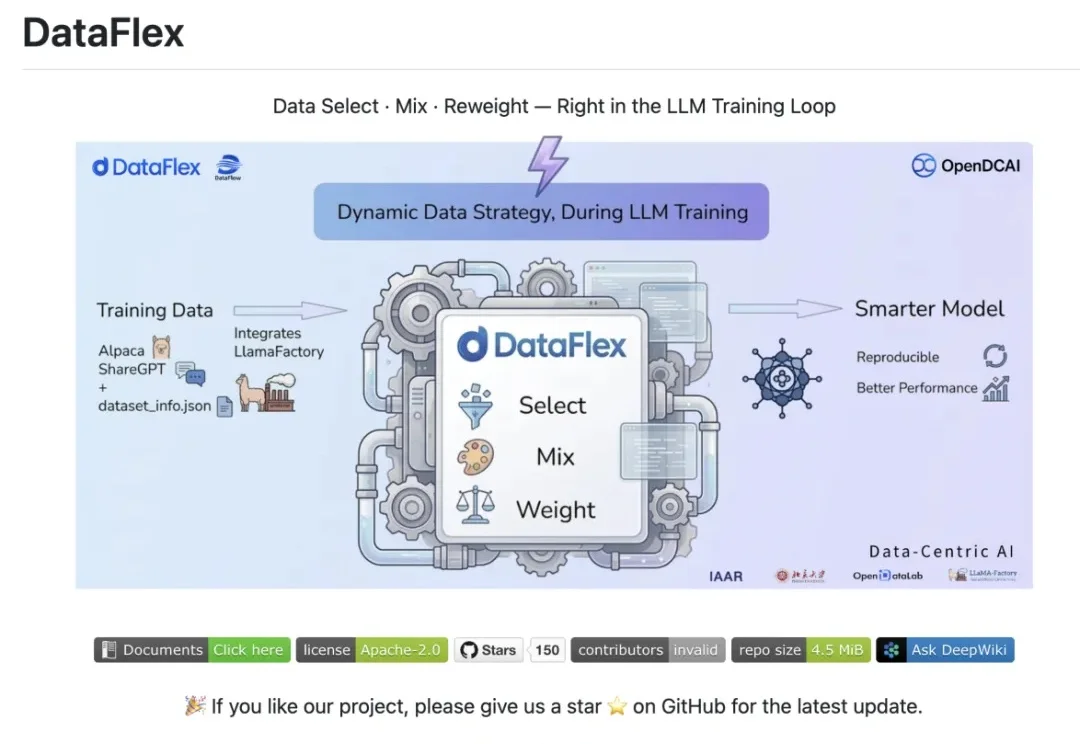
当大模型训练进入深水区,竞争的关键已经不再只是「模型参数怎么调」,而逐渐转向一个更核心、也更难系统解决的问题:模型在训练过程中究竟看到了什么数据、以什么比例看到、哪些样本应该被更频繁地学习。