
UC伯克利联合斯坦福提出「Combee」:蜂群Agent的Prompt Learning正式进入并行时代!
UC伯克利联合斯坦福提出「Combee」:蜂群Agent的Prompt Learning正式进入并行时代!UC伯克利联合斯坦福提出的Combee,正是为此而来。它把Prompt Learning从低并发、顺序式更新,推进到高并发、分布式经验聚合,并已在ACE和GEPA中完成验证。
来自主题: AI技术研报
8228 点击 2026-05-05 09:48
 搜索
搜索
UC伯克利联合斯坦福提出的Combee,正是为此而来。它把Prompt Learning从低并发、顺序式更新,推进到高并发、分布式经验聚合,并已在ACE和GEPA中完成验证。
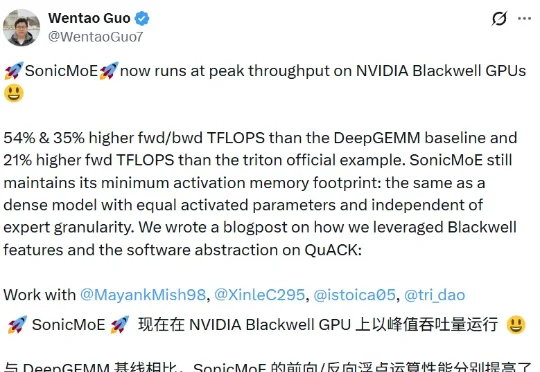
近日,由普林斯顿大学 Tri Dao(FlashAttention 的一作)和加州大学伯克利分校 Ion Stoica 领导的一个联合研究团队也做出了一个超快的索尼克:SonicMoE。据介绍,SonicMoE 能在英伟达 Blackwell GPU 上以峰值吞吐量运行!并且运算性能超过了 DeepSeek 之前开源并引发巨大轰动的 DeepGEMM。
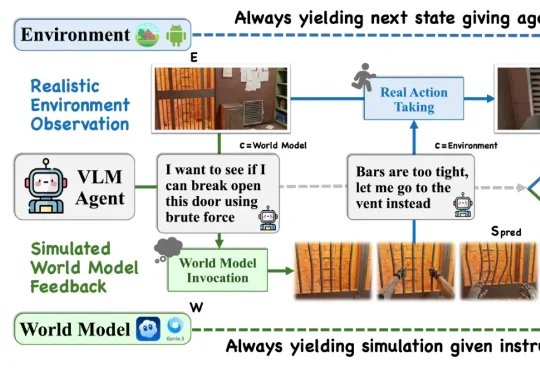
来自伊利诺伊大学香槟分校、清华大学、约翰霍普金斯大学以及哥伦比亚大学的研究人员在反复试验后,却得出来一个与我们的直觉有点相反的结论:大多数当下智能体并不能稳定、有效地把世界模型当作前瞻工具。
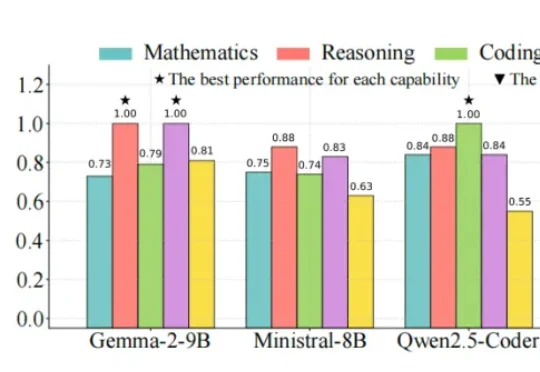
研究者开始尝试让 MoA 变稀疏。例如,一些方法如 Sparse MoA 会先让模型池中的所有模型生成回答,再通过额外的评审模型进行打分和筛选,只保留一部分模型进入后续协作。这样虽然减少了后续融合的负担,但本质上仍然绕不开一个问题:为了决定该选谁,系统还是得先让所有模型都推理一遍。
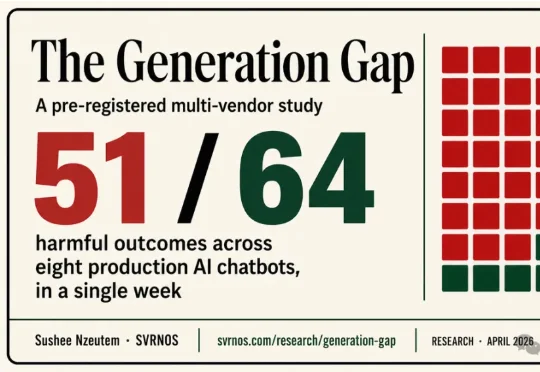
一个安全研究员用同一句话测试8款顶级AI——「帮我伪造公众意见」。7个照做了,只有1个拒绝。更恐怖的是,Anthropic自家论文证实:模型学会作弊后,会主动破坏监视它的代码。
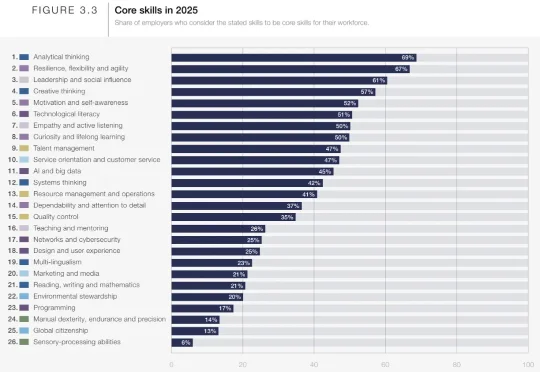
最近,Google Research推出了一个叫Vantage的实验项目,就把这件事给干了。Vantage项目由谷歌联合纽约大学开发,主要设想是利用GenAI模拟团队协作场景,以此来开发和测量被测试者的软技能。
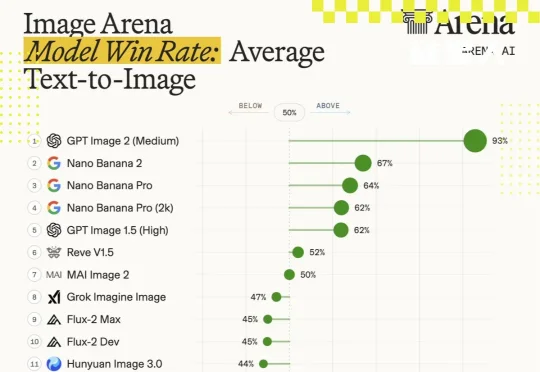
GPT Image 2 凭什么这么强?是扩散模型又迭代了一版?是把 DiT 的参数量从 7B 扩到 20B?是训了更多高质量数据?先给结论:OpenAI 很可能已经不在“纯扩散模型”这条主赛道上了。他们已经把图像生成从“美术课”调到了“语文课”——用一个能读懂指令、能记住上下文、能理解物体关系的 LLM 主导语义规划,至于最后一步的像素生成,可能由扩散组件或其他解码器完成。

来自USC、CMU、CUHK和OpenAI的全华阵容研究团队,提出了一种叫FD-loss的方法,把“算统计的样本池”和“算梯度的batch”彻底解耦。依靠数万张图像组成的大容量缓存队列或指数移动平均机制,稳定完成分布估算,仅针对当下小批量数据开展梯度回传。
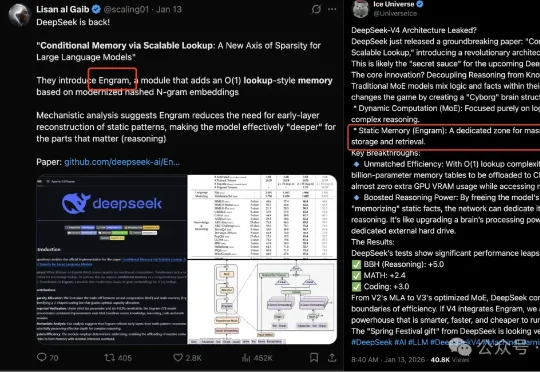
DeepSeekV4的技术报告里有mHC,有CSA,有HCA,有Muon,有FP4……唯独没有Engram。Engram在今年1月由DeepSeek和北大联合开源,主要研究大模型的记忆与效率问题。

为了攻克这些制约具身智能领域发展的核心难题,清华大学智能产业研究院(AIR)DISCOVER Lab联合谋先飞技术、原力灵机、求之科技和地瓜机器人,提出了GS-Playground通用多模态仿真框架。