DeepMind入股硬核网游EVE,要让AI学「黑暗森林」
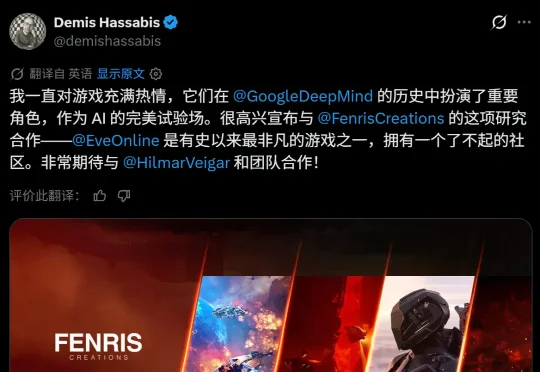
DeepMind入股硬核网游EVE,要让AI学「黑暗森林」本周四,Google DeepMind 宣布他们又要开始打游戏了。这次目标还是全世界最硬核的那一款:EVE Online。Google DeepMind 此次宣布收购著名科幻在线角色扮演游戏《EVE Online》(星战前夜)开发商的部分股权,并表示将利用该游戏研究「复杂、动态、玩家驱动的系统中的智能」。
来自主题: AI资讯
8993 点击 2026-05-08 10:11