面对无解问题大模型竟会崩溃?港中文&华为联合提出首个大模型推理可靠性评估基准
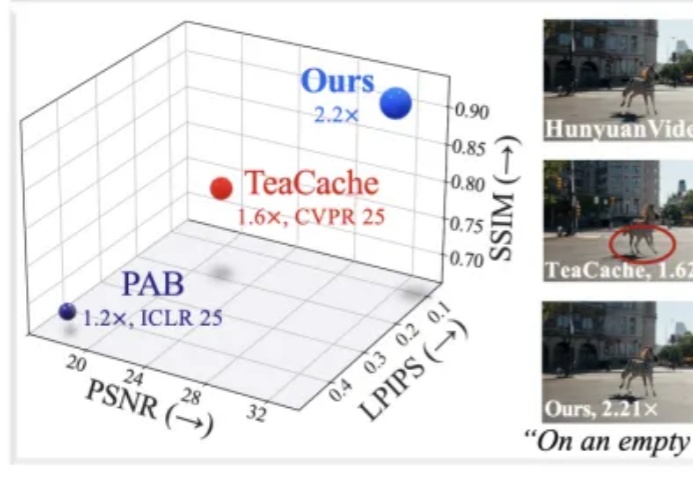
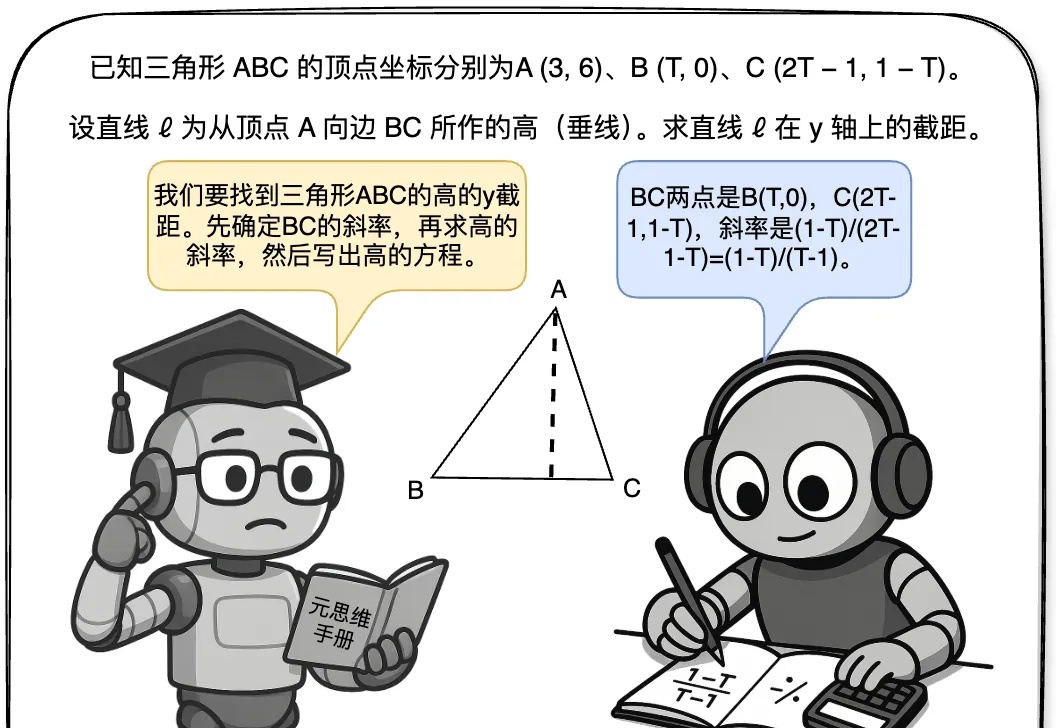
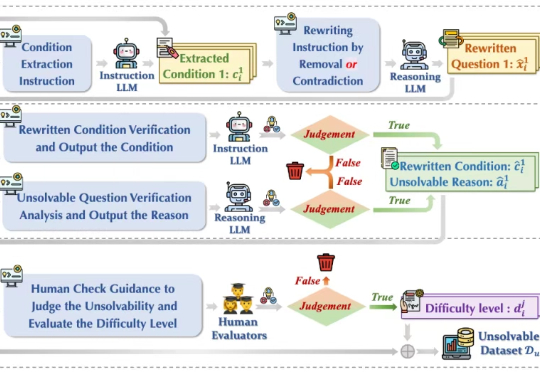
面对无解问题大模型竟会崩溃?港中文&华为联合提出首个大模型推理可靠性评估基准今年初以 DeepSeek-r1 为代表的大模型在推理任务上展现强大的性能,引起广泛的热度。然而在面对一些无法回答或本身无解的问题时,这些模型竟试图去虚构不存在的信息去推理解答,生成了大量的事实错误、无意义思考过程和虚构答案,也被称为模型「幻觉」 问题,如下图(a)所示,造成严重资源浪费且会误导用户,严重损害了模型的可靠性(Reliability)。
来自主题: AI技术研报
9377 点击 2025-07-17 11:24