
GPT-5.6 偷偷灰度?有人在 Codex 里提前用上了
GPT-5.6 偷偷灰度?有人在 Codex 里提前用上了你以为自己在用GPT-5.5,但OpenAI可能已经在后台,悄悄把你的底层模型换成了更先进的GPT-5.6 Sol。
来自主题: AI技术研报
8583 点击 2026-06-29 16:14
 搜索
搜索
你以为自己在用GPT-5.5,但OpenAI可能已经在后台,悄悄把你的底层模型换成了更先进的GPT-5.6 Sol。

在世界模型这条路上,行业一直卡在一个几乎无解的矛盾里:想要更真实的长程模拟,就必须给模型更深的计算;可一旦把模型做得更深,部署成本、参数规模和误差累积又会迅速抬头。结果就是,大家都知道世界模型要 “想得更久”,却很难让它在现实系统里 “算得起、跑得稳”。
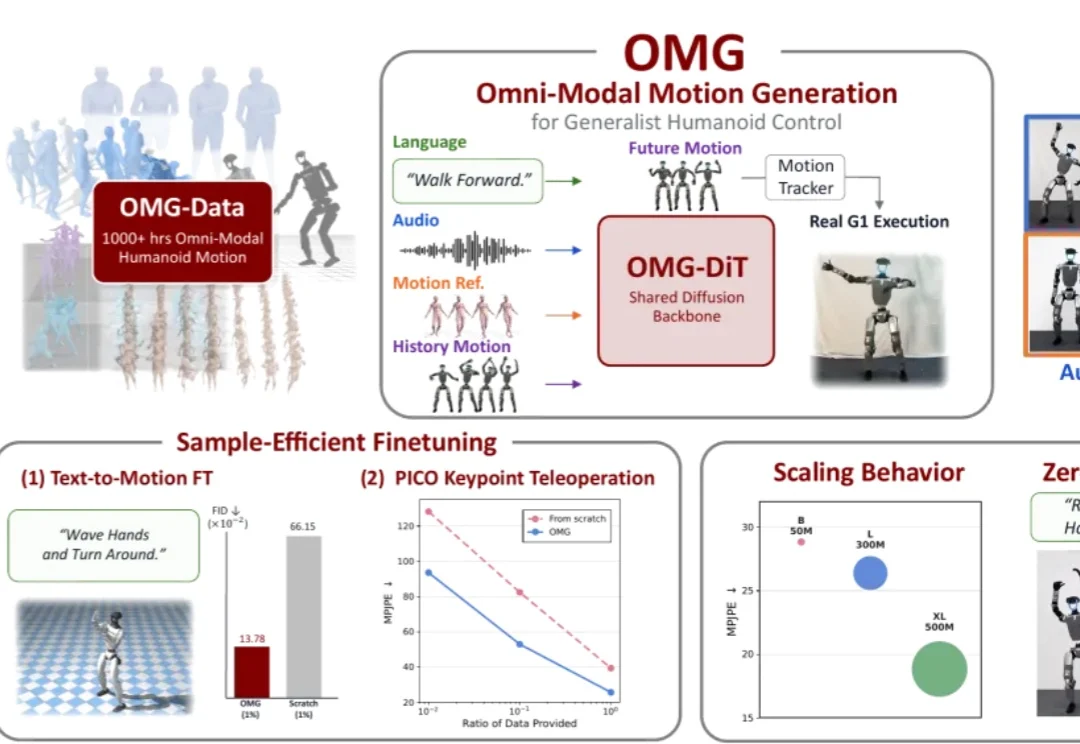
现阶段大多数人形机器人的运动控制还局限于 “有参考才能动” 的被动跟踪模式。
自从 6 月 1 日宣布全部旗下旗舰模型 API 免费之后,文本、图片、视频这三个模型我都一直在用,确实帮我省了很多钱,同时模型能力也不错。而最近,Agnes AI 又双叒叕搞了个新平台:Pavo。

最后一个GPT-4走了。4个半月,OpenAI清空整个GPT-4家族,GPT-4.5是其中最后一个退场的。没有告别,只有一行更新日志——一个模型的退役,正在变成AI圈的日常。

GPT-5.6 Sol被拆分、被按住,Fable 5被全球禁用72小时后才戴着镣铐回归。Anthropic和OpenAI最强模型,双双被「切脑」。

硅谷著名科技播客主持人 Dwarkesh Patel 最近抛出了一个问题:AI 的下一代训练范式会是什么?
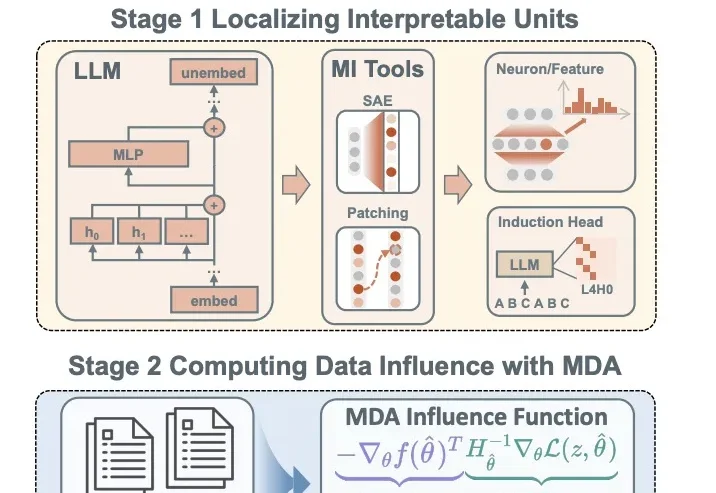
近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。

豆包产品无敌,但Seed模型一直不温不火,大伙对它的印象就两个: 工资高,隔三差五就有千万年包上亿年包新闻,也不知道真假;多模态,但编程能力不太行。
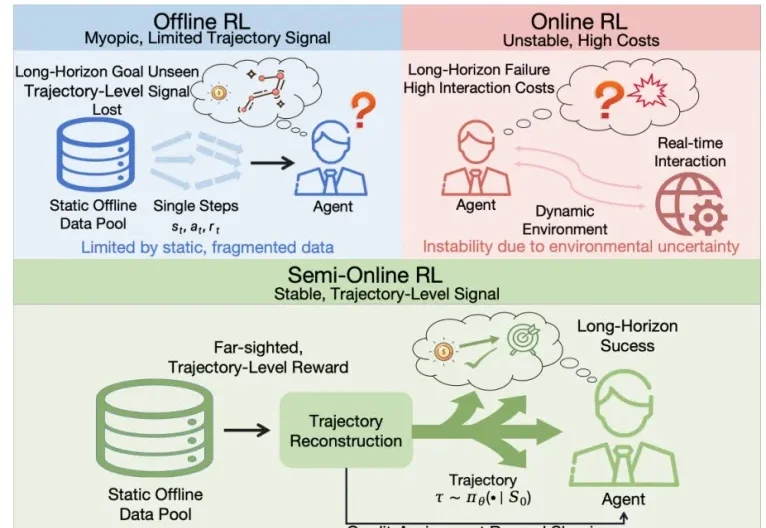
想训练能自动操作手机的GUI(图形用户界面)智能体,总会遇到两难困境: