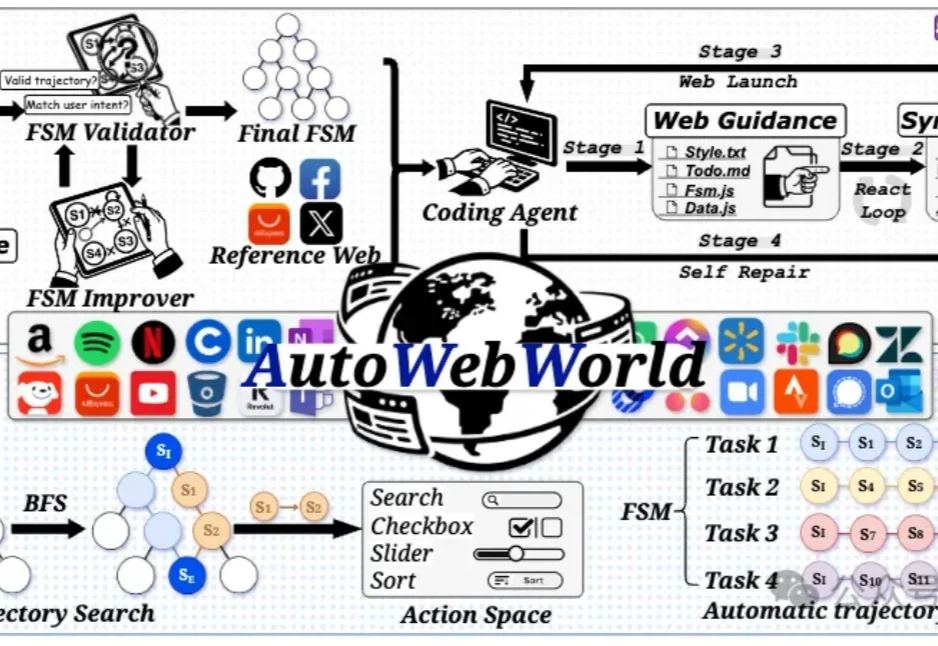
GUI Agent轨迹获取新范式:有限状态机合成无限轨迹数据,平均每条轨迹成本低至0.04美元
GUI Agent轨迹获取新范式:有限状态机合成无限轨迹数据,平均每条轨迹成本低至0.04美元训练一个真正会用网页的GUI Agent,最自然的思路通常是: 去真实网站上操作,收集轨迹,再拿来训练。
来自主题: AI技术研报
10440 点击 2026-05-29 09:40
 搜索
搜索
训练一个真正会用网页的GUI Agent,最自然的思路通常是: 去真实网站上操作,收集轨迹,再拿来训练。

后空翻、跑酷、单手抓举几十公斤……
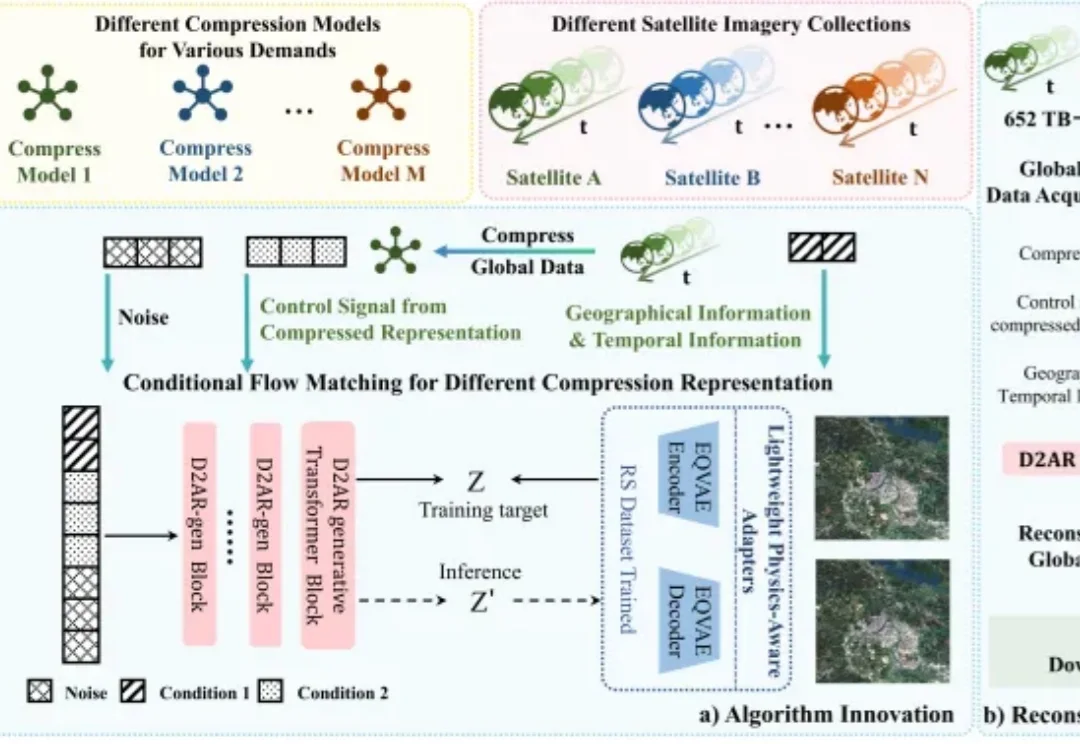
随着全球遥感卫星持续运行,地球观测数据正在快速增长。多源、多时相、多光谱遥感影像为国土监测、生态评估、灾害预警、气候变化研究等任务提供了重要数据基础,但也带来了显著的存储、传输和计算压力。

DeepSeek V4发布,比模型本身更受关注的,是一个根本性的转变: 国产算力生态正在从过去“芯片被动适配模型”的单向奔赴,迈向“芯模协同”的新阶段。
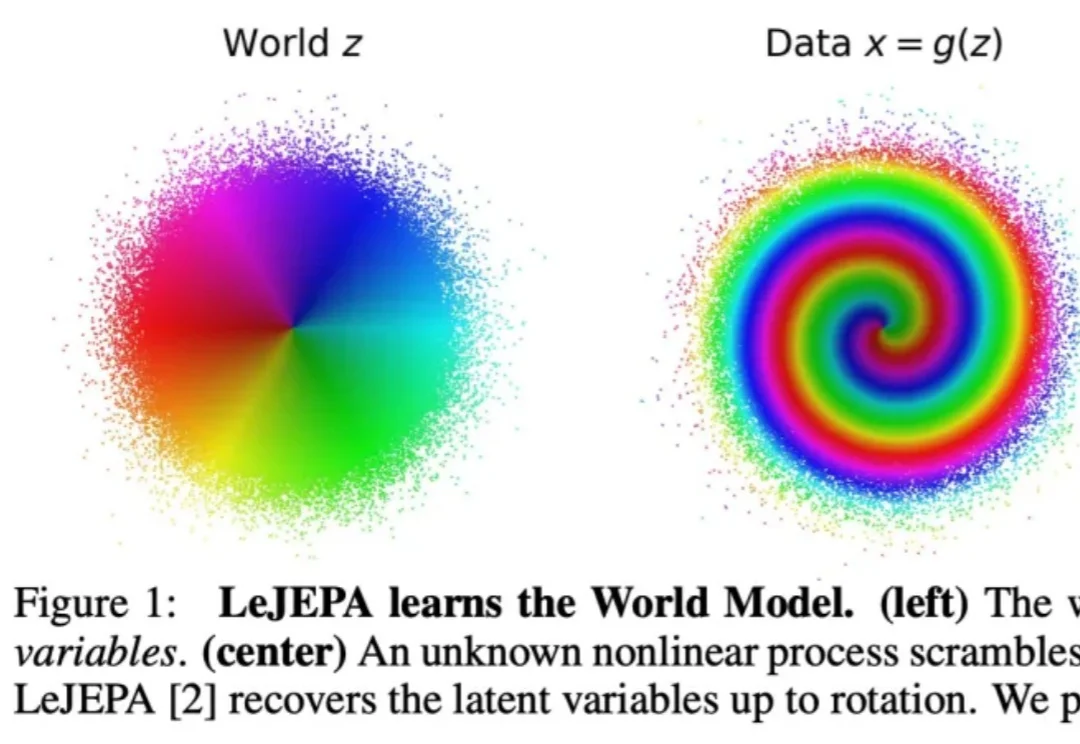
LeCun的LeJEPA到底有没有构建出世界模型?他本人最新发表的论文,解答了这个问题。

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。

7×24,AI也吃不消。

过去的大模型 scaling law 通常回答的是:当模型参数量、数据量和训练计算量增加后,loss 会如何下降。
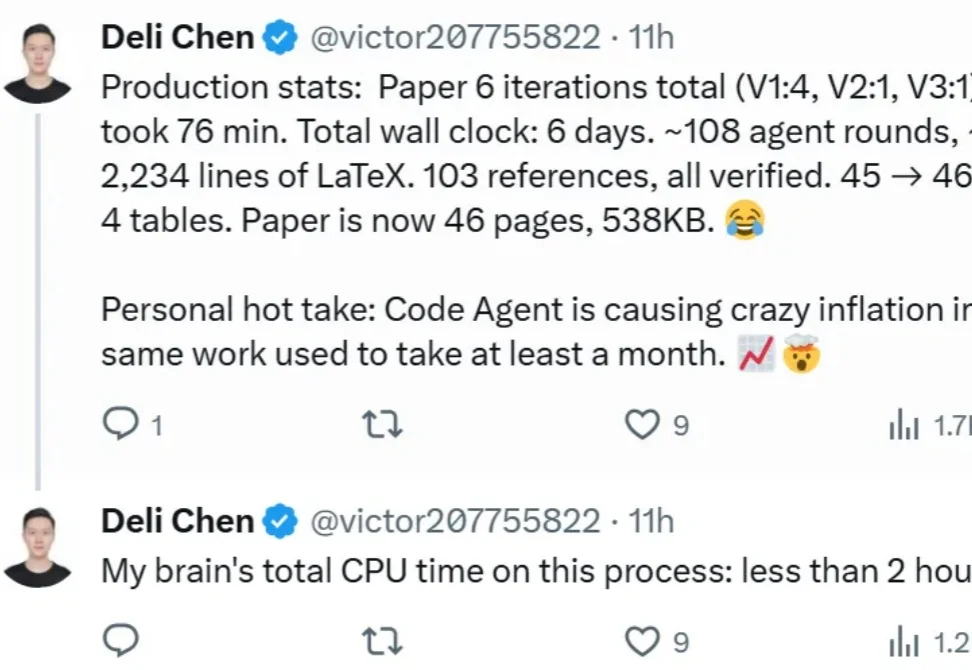
「借助 CodeAgent,我终于可以重新捡起很多过去因为精力不足而搁置的事情了,写博客就是其中之一。这篇博客大概 1% 是我写的,99% 是 Agent 写的 😂」。

当对话型 AI 服务于数十亿用户时,我们能否看见用户没说出口的那一层?JHU、MIT 和 Google Research 给出了新的解法。