
MBench: 清华x腾讯联合定义视频世界模型的长期记忆能力
MBench: 清华x腾讯联合定义视频世界模型的长期记忆能力随着视频生成技术的发展,模型正在从短视频片段合成,向流式长视频生成演进。然而,仅仅做到视觉上的逼真是不够的。一个功能完备的视频世界模型,必须能够在长时序交互中保持稳定的内部状态,并遵循真实世界的物理定律与逻辑规则。
来自主题: AI技术研报
7367 点击 2026-06-11 14:30
 搜索
搜索
随着视频生成技术的发展,模型正在从短视频片段合成,向流式长视频生成演进。然而,仅仅做到视觉上的逼真是不够的。一个功能完备的视频世界模型,必须能够在长时序交互中保持稳定的内部状态,并遵循真实世界的物理定律与逻辑规则。

今天一早,谷歌又发新模型了!
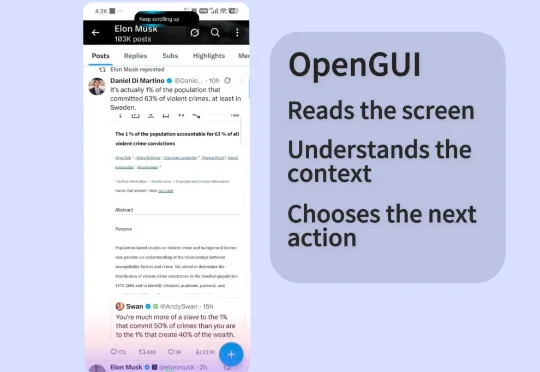
独家获悉,GUI Agent(图形用户界面智能体)执行平台 「Core-Mate」 近日宣布完成数千万人民币融资。核心团队主要来自字节跳动,成员在用户产品、业务增长和商业化落地中积累了系统经验。在团队看来,下一代 AI 产品的关键不只在模型能力,也在入口、场景和用户行为。
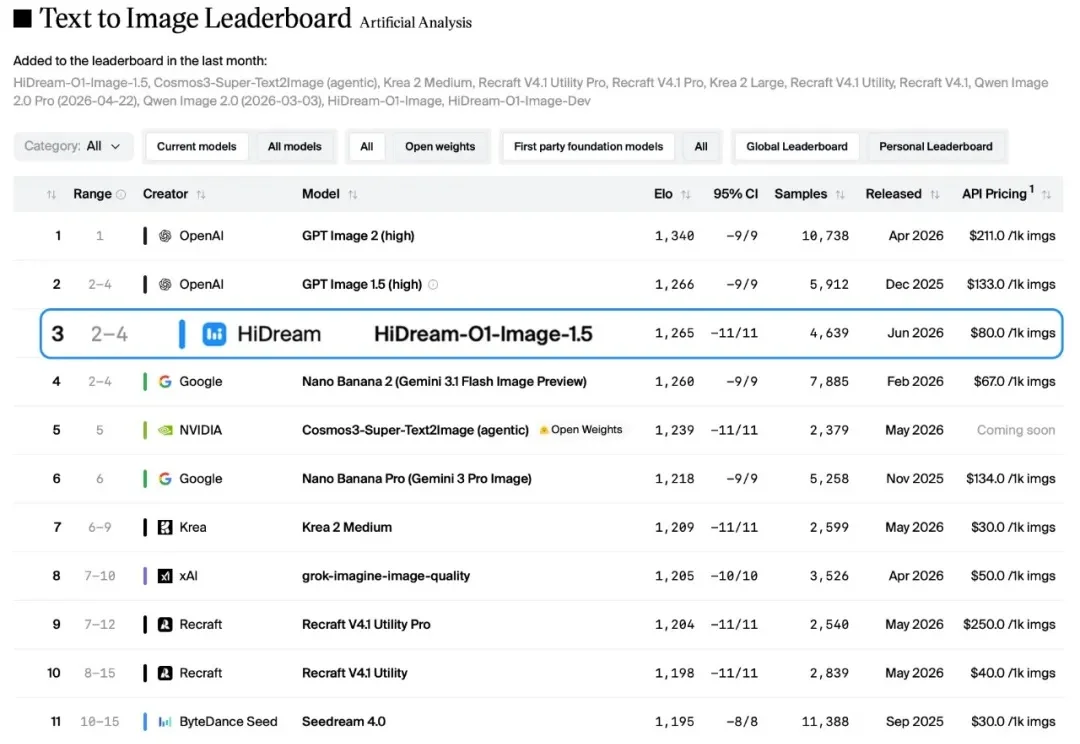
文生图的"慢思考",到底有没有用?

过去一年,开源模型的发布节奏已经快到让人麻木。每次发布,伴随的永远是一组跑分、一张能力雷达图,以及几个“超越某某”的结论。
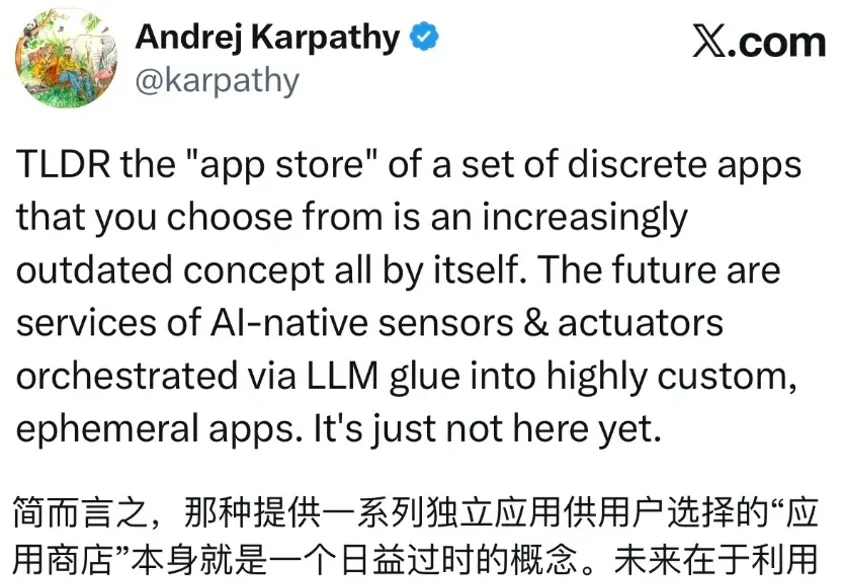
想象一下,你问 AI 要一个饮食记录工具,它不再是回你一段文字建议,而是直接给你一个可以点击添加、统计热量的完整应用。人和 AI 的交互,正在从「读文字」走向「用应用」。

「版本之子」 「同志们朋友们,版本回调了! 现在的情况是,搞AI应用的家人们没活了。胜利女神的天平又一次倾向了大模型公司一边。有鉴于此,我们将复刻致敬葬AI一年前的系列——把模型公司挨个写一遍。 第一

全球大模型的军备竞赛,正在“智商”之外开辟新的战场—— 推理速度。

当所有人都在盯着通用大模型时,Voice AI 这条相对安静的赛道里,也开始出现一些值得注意的新模型。最近,一家名为 Hojo 的创业团队公开披露了一组语音识别测试结果,似乎有成为「黑马」的趋势。
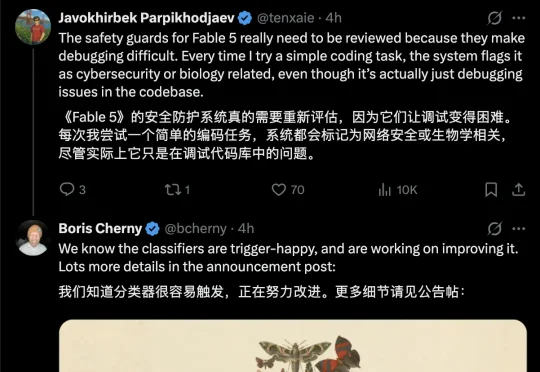
Claude刚刚发布的新模型Fable 5,很多人可能压根就用不上!有不少网友实测发现,Fable 5的安全护栏检测机制的触发几率似乎比官方宣称的不到5%严格得多。无论是普通编码任务。