
Claude下一代神级模型秘密出炉!Sonnet-5被曝下周上线
Claude下一代神级模型秘密出炉!Sonnet-5被曝下周上线Claude新模型要来了?据悉,Sonnet-5已经现身,下一代神级模型Fennec最快下周上线!而且,Mythos 5.1或6,已经在内部完成训练,Mythos升级版仅用60天跨代诞生。全面封锁,反而让Anthropic的迭代疯狂加速了!
来自主题: AI资讯
8765 点击 2026-06-22 10:29
 搜索
搜索
Claude新模型要来了?据悉,Sonnet-5已经现身,下一代神级模型Fennec最快下周上线!而且,Mythos 5.1或6,已经在内部完成训练,Mythos升级版仅用60天跨代诞生。全面封锁,反而让Anthropic的迭代疯狂加速了!

Fable 5回来了?Claude安卓版的「模型选择器」中,消失一周的Fable 5意外现身。

2026年的AI视频生成赛道,已经拥挤到连空气都变得稀薄。

我们最近在重新思考一件事:到底什么样的 Benchmark,才值得今天继续做?

当AI神话被账本照亮,最刺眼的真相终于浮出水面。退潮时刻,狂欢结束。探照灯打过来,谁在裸泳,一目了然。
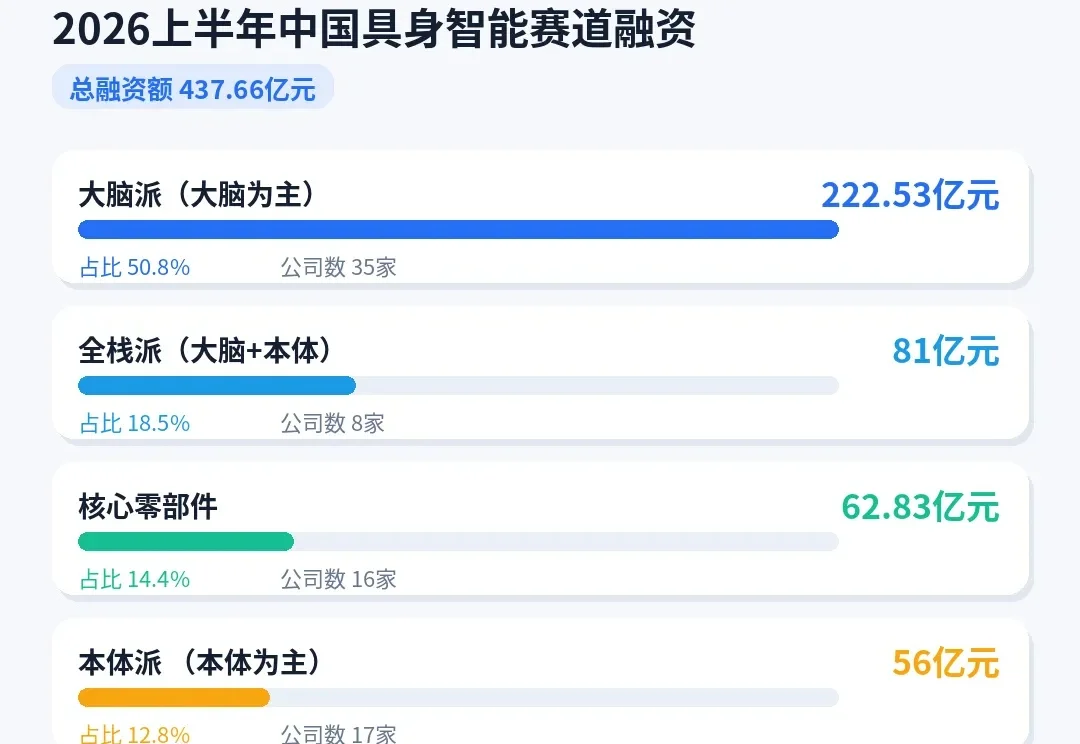
具身智能领域的资本,正在涌向机器人的“大脑”。

就在最近,OpenAI扔出一篇重磅论文。他们发现,只教AI好好看病,它写代码居然也不作弊了。方法简单到离谱:拿5%的训练数据,教模型在回答健康问题时诚实、谨慎、知错能改。

斯坦福胡佛研究所追踪了 DeepSeek 七篇论文背后 356 名研究者的完整职业轨迹。美国培养出的最优秀 AI 人才正在大规模回流中国,而中国本土管道已经能独立产出前沿模型的核心贡献者。
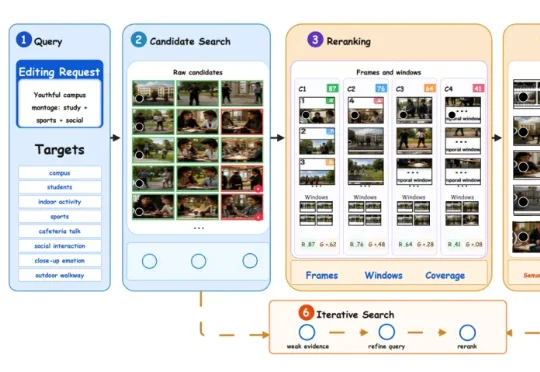
近年来,大语言模型(LLMs)在长篇视觉叙事中展现出卓越潜力,生产方式正迅速从单一模型生成转向面向生产的智能体系统。但长视频剪辑仍然是一个极难控制的长期任务。模型有时会在缺乏素材依据的情况下强行生成,甚至在面对明显断档的转场或人物不一致时依然“盲目拼接”。
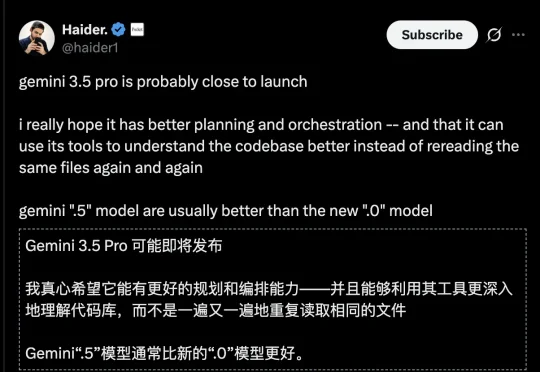
据最新独家爆料,谷歌目前正在紧锣密鼓地对即将发布的重磅大语言模型Gemini 3.5 Pro进行高强度的激进迭代,在正式揭晓之前,内部预计还会测试更多的版本。