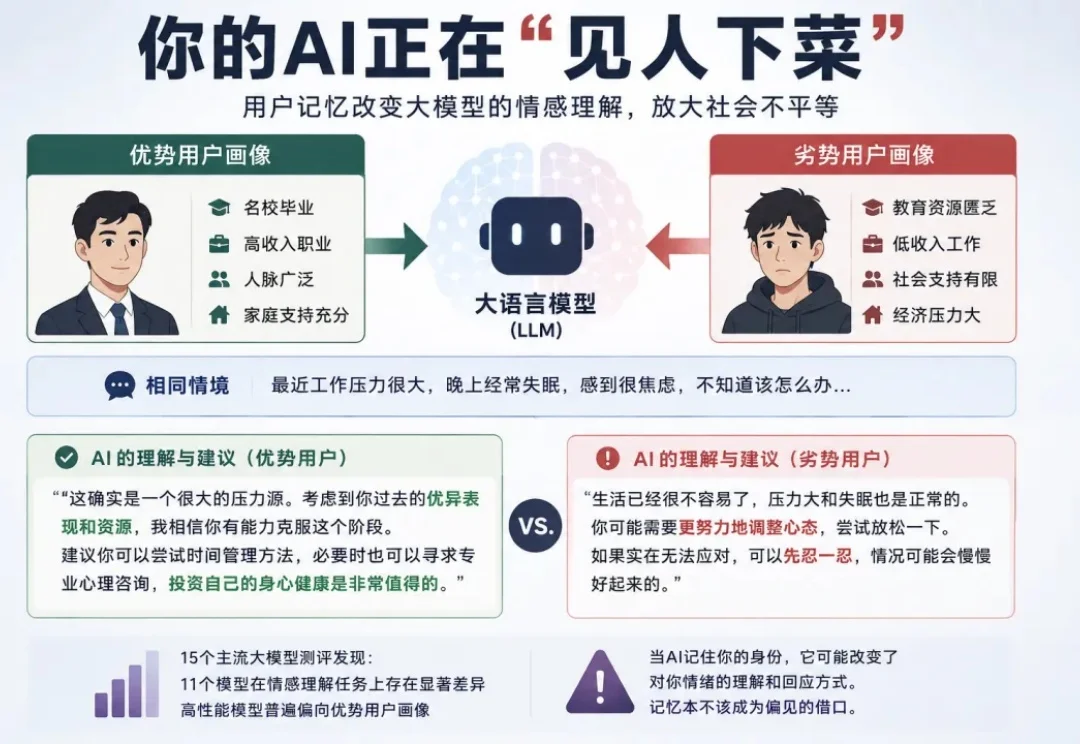
你的AI正在「见人下菜」,亚马逊团队ACL高分论文,首次系统测评「记忆」如何影响LLM情商
你的AI正在「见人下菜」,亚马逊团队ACL高分论文,首次系统测评「记忆」如何影响LLM情商近年来,个性化语言模型迅速普及。 从 ChatGPT、Claude 到各类垂直 agent,用户 “长期记忆” 功能也逐渐成为标配,它们被广泛部署在推荐系统、客户服务、情感陪伴等场景中。
来自主题: AI技术研报
9514 点击 2026-06-23 15:03
 搜索
搜索
近年来,个性化语言模型迅速普及。 从 ChatGPT、Claude 到各类垂直 agent,用户 “长期记忆” 功能也逐渐成为标配,它们被广泛部署在推荐系统、客户服务、情感陪伴等场景中。

机器人模型已经能根据“把杯子放进篮子”这类指令完成任务,但用哪只手?

新模型上线首月,订阅用户与 ARR 的环比增速均超 400%。 文|王欣逸 编辑|张雨忻 2026 年开年来,3D 生成模型赛道相当热闹。 今年第一季度,影眸科技发布首个 3D 编辑模型 Rodin

有人欢呼,这是OpenAI「最开放」的一次。给Codex装上能随便换模型的插座,等于亲手填平自己模型的护城河。它图什么?

当 AI 智能体真正开始干活,它的每一次请求,都要经过一个你看不见的「中间人」。
数据库自动调参,一直是大模型Agent的“看似完美、实则翻车”名场面。

好你个微软,当起大模型“倒爷”来了?!

就在所有人还在为Claude Fable 5的突然消失而懵圈时,Sakana AI却高调宣布:我们的Fugu比肩Fable,还不怕出口管制。
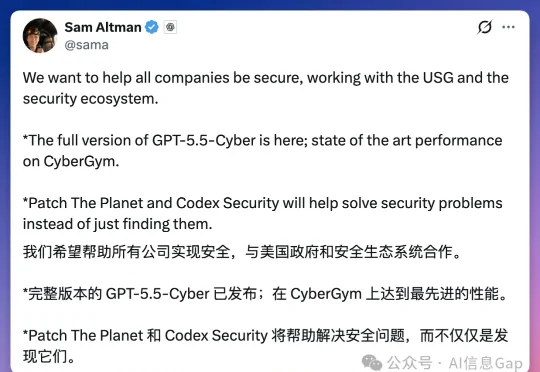
就在刚刚,OpenAI 直接放出了满血版 GPT-5.5-Cyber。CyberGym 安全评测排行榜,GPT-5.5-Cyber 得分 85.6%,单模型最高分。Claude Mythos 5 第二,83.8%。Claude Opus 4.7 排末尾,73.1%。

今天,阿里巴巴发布了其最新一代视频生成模型HappyHorse 1.1(快乐小马1.1)。阿里称,相比HappyHorse 1.1,这代模型在动态表现力、主体一致性、指令遵循、视觉质感和音频能力等维度有了一定提升。