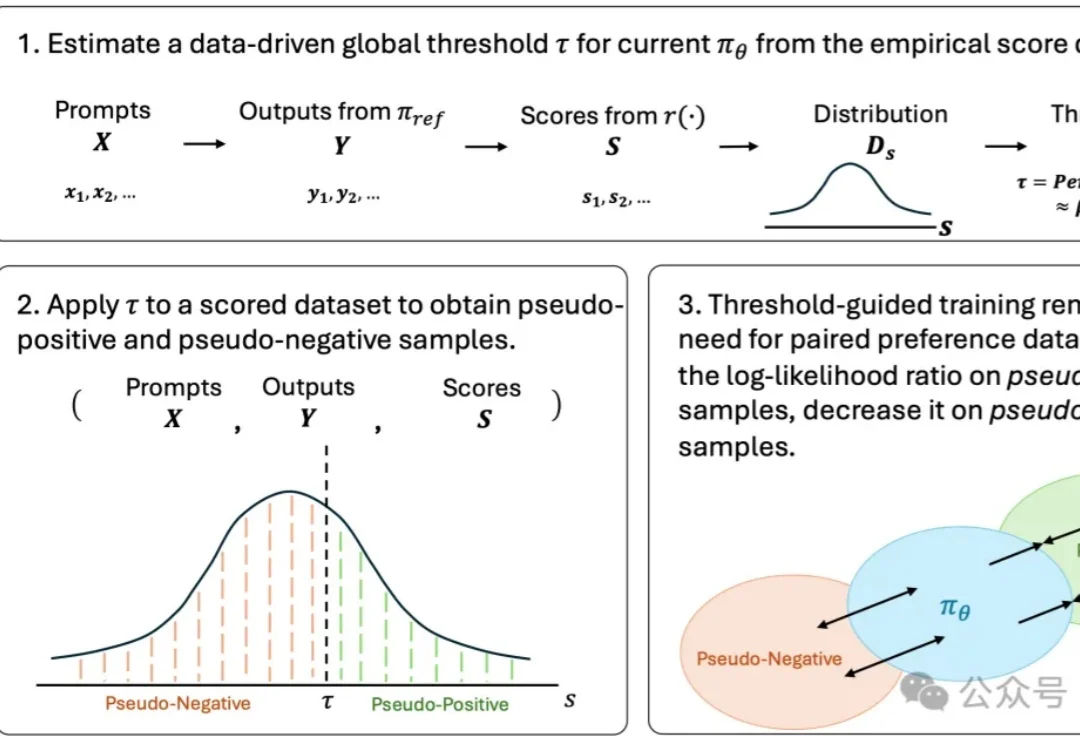
无需构造偏好对:TGO用标量反馈对齐视觉生成模型|ICML'26
无需构造偏好对:TGO用标量反馈对齐视觉生成模型|ICML'26生成模型的偏好对齐,可能正在进入一个新的阶段。
来自主题: AI技术研报
10392 点击 2026-05-18 09:54
 搜索
搜索
生成模型的偏好对齐,可能正在进入一个新的阶段。
前几天在 Milvus 社区,一位做以图搜图的朋友提了一个问题:
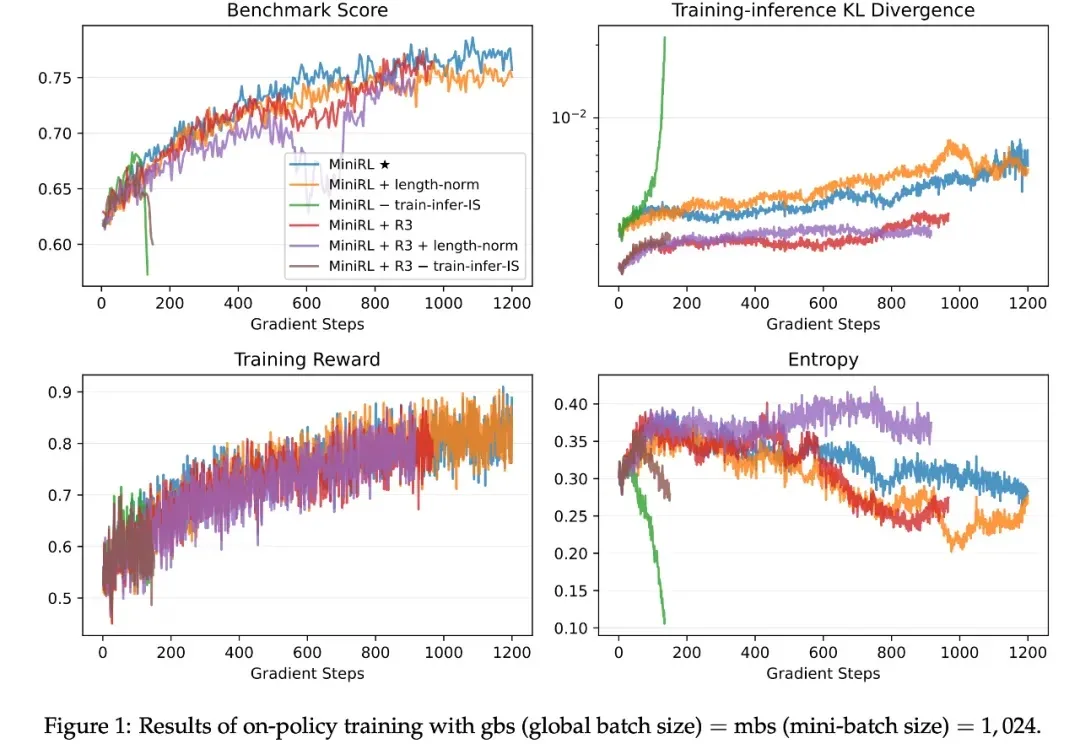
如今,强化学习(RL)已成为提升大语言模型(LLM)复杂推理与解题能力的关键技术范式,而稳定的训练过程对于成功扩展 RL 至关重要。由于语言具有强烈的上下文属性,LLM 的 RL 通常依赖序列级奖励 —— 即根据完整生成序列给一个标量分数。
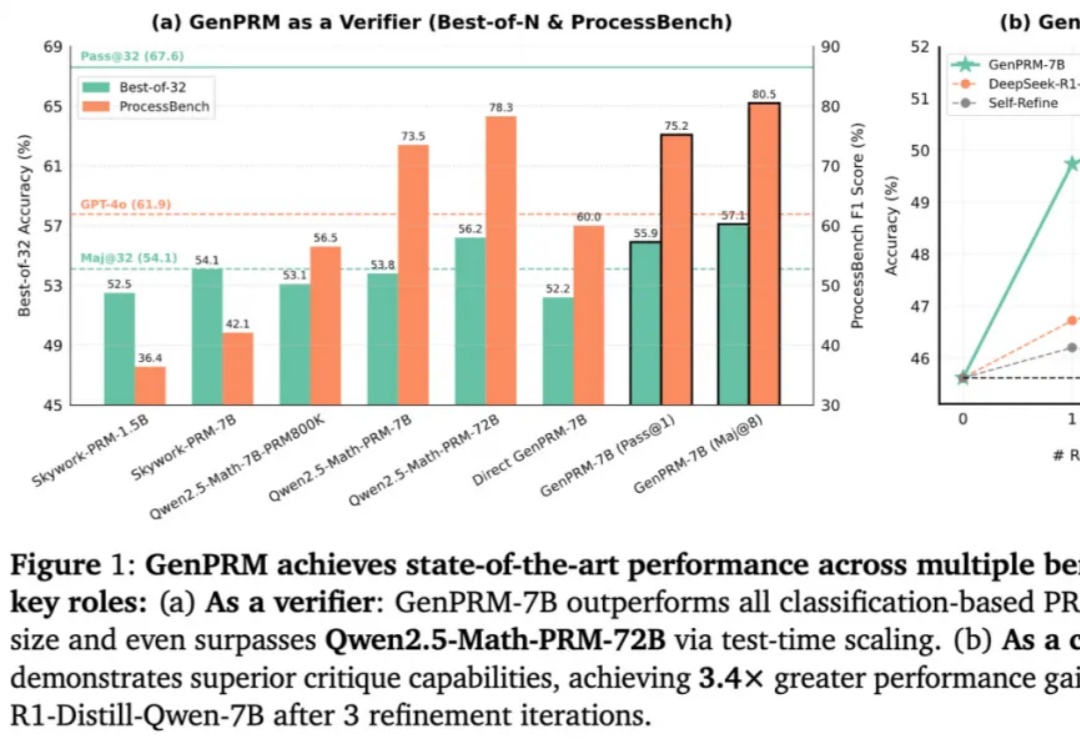
随着 OpenAI o1 和 DeepSeek R1 的爆火,大语言模型(LLM)的推理能力增强和测试时扩展(TTS)受到广泛关注。然而,在复杂推理问题中,如何精准评估模型每一步回答的质量,仍然是一个亟待解决的难题。传统的过程奖励模型(PRM)虽能验证推理步骤,但受限于标量评分机制,难以捕捉深层逻辑错误,且其判别式建模方式限制了测试时的拓展能力。

AI中的应用:在机器学习中,单条数据样本的表征都是以向量化的形式来完成的。向量化的方式可以帮助AI算法在迭代与计算过程中,以更高效的方式完成。