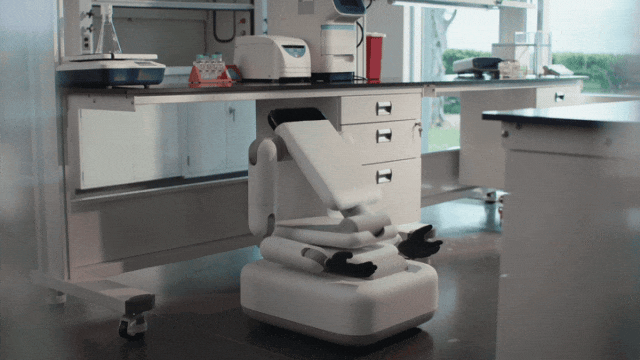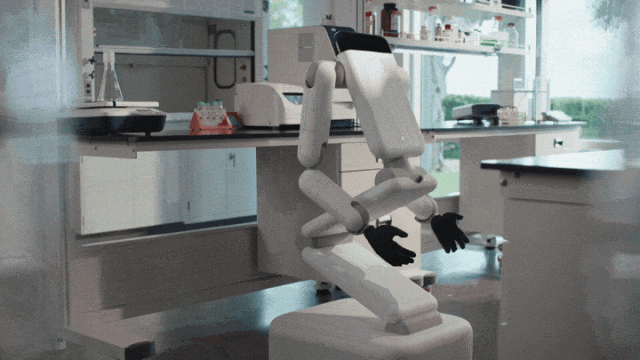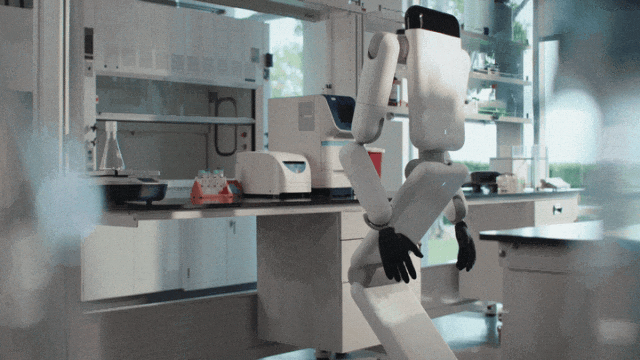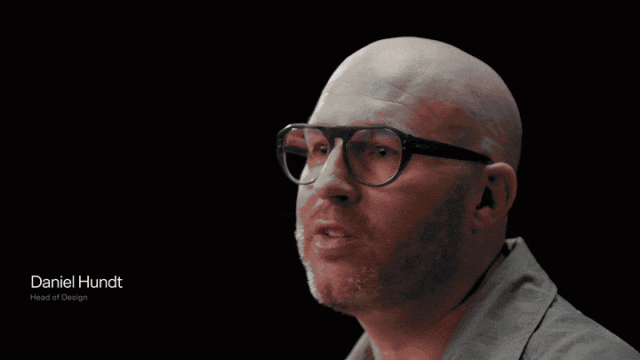
Genesis AI 发了一款三折叠机器人
Genesis AI 发了一款三折叠机器人通用机器人不一定要像人,Genesis AI 的答案是:收起头和腿,把真正像人的部分留给手。
来自主题: AI资讯
9545 点击 2026-06-17 15:06
 搜索
搜索
通用机器人不一定要像人,Genesis AI 的答案是:收起头和腿,把真正像人的部分留给手。
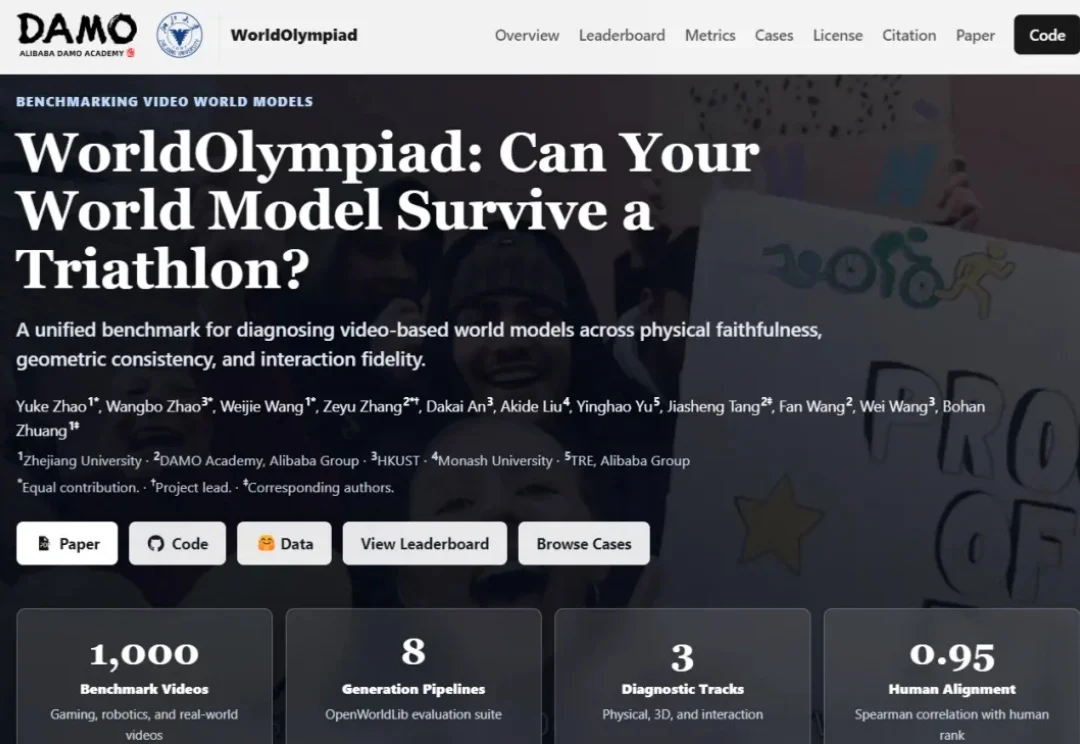
达摩院联合高校推出WorldOlympiad评测基准,跳出传统视频“唯画质”的评价逻辑,以物理真实性、三维几何一致性、长时序交互保真度三大维度,搭配游戏、机器人、通用实景三大场景,打造一套全方位的视频世界模型评测体系。

通用机器人,不必长得像人。

当大模型开始控制机械臂、家用机器人时,“安全”这件事也变得不一样了。
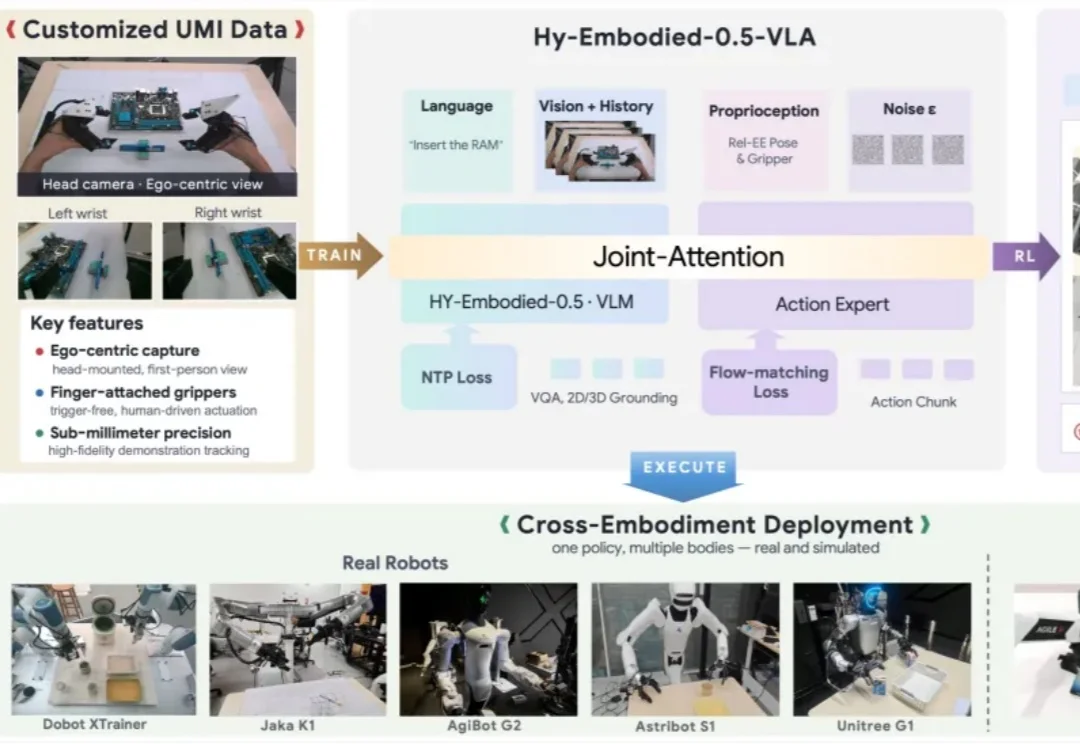
6 月 15 日,腾讯 Robotics X、福田实验室与混元团队联合发布面向真实世界机器人操作任务的端到端具身智能模型 Hy-Embodied-0.5-VLA(简称 HyVLA-0.5)。

刚刚,大晓机器人半年融资数亿美元,开悟世界模型同时刷新四大权威榜单第一,4B参数硬刚28B大模型!具身智能的「ChatGPT时刻」真的要来了?

宇树机器人要攀登珠峰了!

具身智能领域新星OriginFlow(渊澈太初)宣布接连完成天使轮、战略轮、Pre-A1轮多轮融资,累计融资总额超5亿元人民币。创始人秦深涛,25岁。本科毕业于哈尔滨工业大学,目前是清华大学博士生。2025年创业,他率先提出并落地NeuroScale数据采集范式,以非侵入式运动神经接口为核心入口,为机器人采集长期缺失的物理交互数据。

当 AI 教育从屏幕走向物理世界,松延动力正用小布米、课程体系和「学校—机构—家庭」生态闭环,把 K12 机器人教育变成具身智能走进千家万户的第一站。

具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。