在失败中进化?UIUC联合斯坦福、AMD实现智能体「从错误中成长」
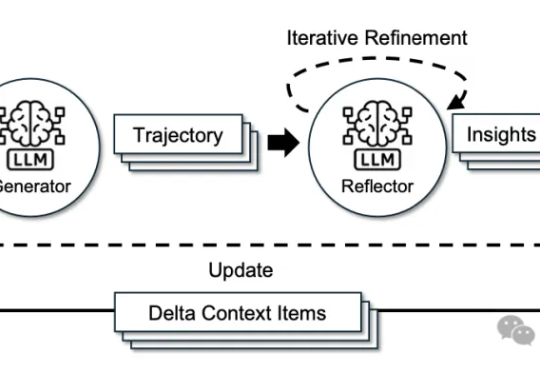
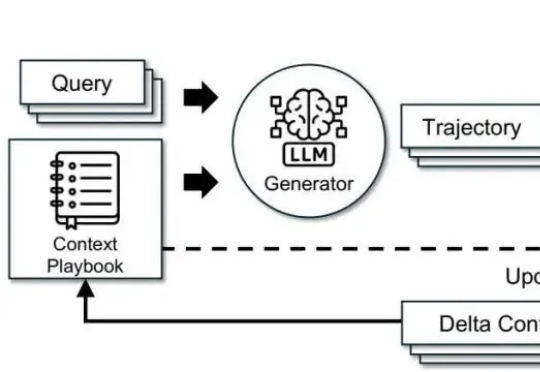
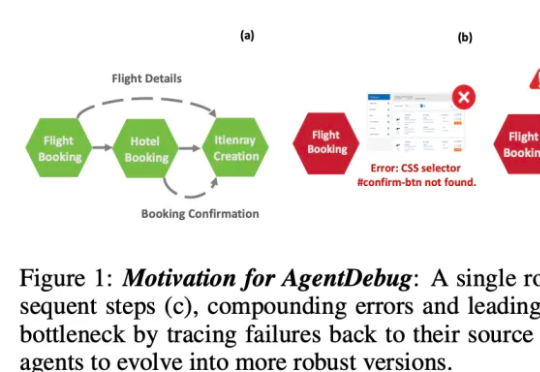
在失败中进化?UIUC联合斯坦福、AMD实现智能体「从错误中成长」伊利诺伊大学厄巴纳 - 香槟分校(UIUC)等团队近日发布论文,系统性剖析了 LLM 智能体失败的机制,并提出了可自我修复的创新框架 ——AgentDebug。该研究认为,AI 智能体应成为自身的观察者和调试者,不仅仅是被动的任务执行者,为未来大规模智能体的可靠运行和自动进化提供了理论与实践工具。
来自主题: AI技术研报
8304 点击 2025-11-07 15:01