
医疗AI大洗牌!斯坦福、普林斯顿发布首个医学世界模型MedOS
医疗AI大洗牌!斯坦福、普林斯顿发布首个医学世界模型MedOS医疗AI终于走出了「只会聊天」的舒适区。今天,斯坦福与普林斯顿联手NVIDIA发布MedOS。这不是一个单纯的手术机器人,而是全球首个通用医疗具身世界模型。从临床诊断到治疗,从外科手术到药物研发,MedOS正在让AI真正读懂「生老病死」的物理现实。
来自主题: AI资讯
9261 点击 2026-02-20 13:37
 搜索
搜索
医疗AI终于走出了「只会聊天」的舒适区。今天,斯坦福与普林斯顿联手NVIDIA发布MedOS。这不是一个单纯的手术机器人,而是全球首个通用医疗具身世界模型。从临床诊断到治疗,从外科手术到药物研发,MedOS正在让AI真正读懂「生老病死」的物理现实。
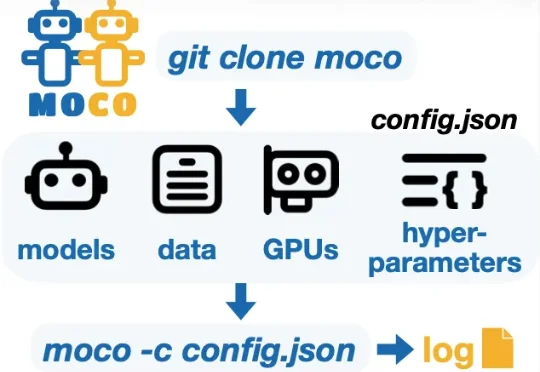
为了支持多模型协同研究并加速这一未来愿景的实现,华盛顿大学 (University of Washington) 冯尚彬团队联合斯坦福大学、哈佛大学等研究人员提出 MoCo—— 一个针对多模型协同研究的 Python 框架。MoCo 支持 26 种在不同层级实现多模型交互的算法,研究者可以灵活自定义数据集、模型以及硬件配置,比较不同算法,优化自身算法,以此构建组合式人工智能系统。MoCo 为设计、
其依据是Micro1的25亿美元(约合人民币173亿元)最新估值。福布斯报道称,成立于2022年的Micro1被曝正在以25亿美元估值洽谈新融资,如果Micro1锁定或超过这一估值,安萨里在该公司持有的约42%股份价值将超过10亿美元(约合人民币69亿元)。

“OpenClaw们”让2026彻底卷成了智能体大战。当初那个“智能体早期真神”,让25个智能体自己聊天、传八卦、谈恋爱的AI小镇Smallville团队也官宣创业了。公司名叫Simile,直接拿下了Index Ventures领投的1亿美元融资,连卡帕西、李飞飞也跟了。
Phoebe Gates是比尔·盖茨的女儿,Sophia Kianni是联合国最年轻的顾问之一,她们在斯坦福大学的宿舍里开始了这场购物革命。那时候,我就感受到她们身上有种不同寻常的执行力和对用户需求的深刻理解。

为什么在LLM推理能力大幅跃升的2026,我们依然只有AI Copilot而没有AI Teammate?尽管AI编程工具遍地开花,但不管是Claude Code还是Codex,本质上仍是“单Agent开发”或“主从控制”架构。而“AI结对编程”迟迟无法落地?

在技术如火如荼发展的当下,业界常常在思考一个问题:如何利用 AI 发现科学问题的新最优解?
大模型持续学习,又有新进展!

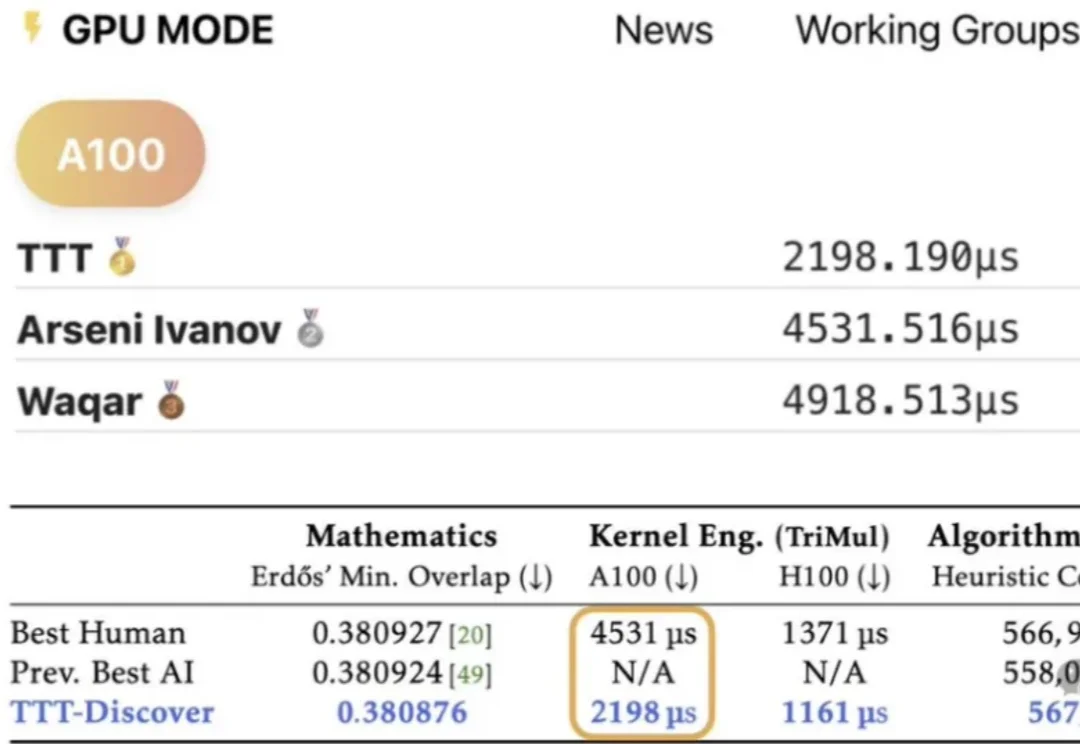
斯坦福与英伟达联合发布重磅论文 TTT-Discover,打破「模型训练完即定型」的铁律。它让 AI 在推理阶段针对特定难题「现场长脑子」,不惜花费数百美元算力,只为求得一次打破纪录的极值。从重写数学猜想到碾压人类代码速度,这种「激进进化」正在重新定义机器发现的边界。
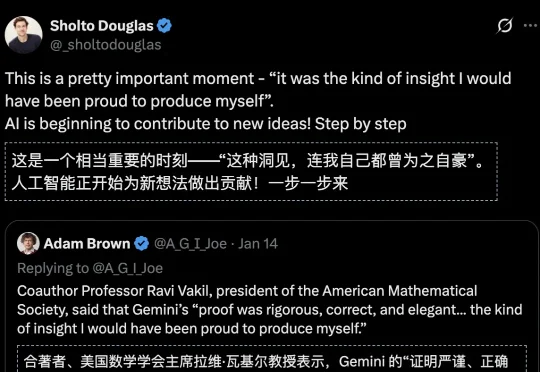
数学奇点初现!Gemini攻克全新数学定理,斯坦福大牛惊呼「想出来能吹一辈子」;陶哲轩预言数学家+AI共生未来;Grok发现黎曼猜想新的隐蔽通道……