
小米组建AI4Materials+前沿材料团队,斯坦福博士带队
小米组建AI4Materials+前沿材料团队,斯坦福博士带队我们获悉,斯坦福博士&前字节AI4S早期员工俞之奡近期已加盟小米集团,出任小米材料Core团队负责人。据悉,AI4Materials和材料core是小米继自研大模型之后,在前沿科技领域的又一战略布局,专注AI+材料协同、串联及前沿材料研发,覆盖小米集团所需的各种新材料方向
来自主题: AI资讯
8964 点击 2026-06-25 10:42
 搜索
搜索
我们获悉,斯坦福博士&前字节AI4S早期员工俞之奡近期已加盟小米集团,出任小米材料Core团队负责人。据悉,AI4Materials和材料core是小米继自研大模型之后,在前沿科技领域的又一战略布局,专注AI+材料协同、串联及前沿材料研发,覆盖小米集团所需的各种新材料方向

IPO敲钟前夜,Anthropic再放大招!Chad Jones官宣入职,用最硬经济学炮抢占国家AI政策最高话语权。

Google DeepMind在6月份对外分享了DiffusionGemma的技术报告,明确指向了一条与现有主流完全不同的演进道路。当大家都在绞尽脑汁让大模型逐词吐字的速度变快时,谷歌干脆把生成顺序改了。

斯坦福胡佛研究所追踪了 DeepSeek 七篇论文背后 356 名研究者的完整职业轨迹。美国培养出的最优秀 AI 人才正在大规模回流中国,而中国本土管道已经能独立产出前沿模型的核心贡献者。
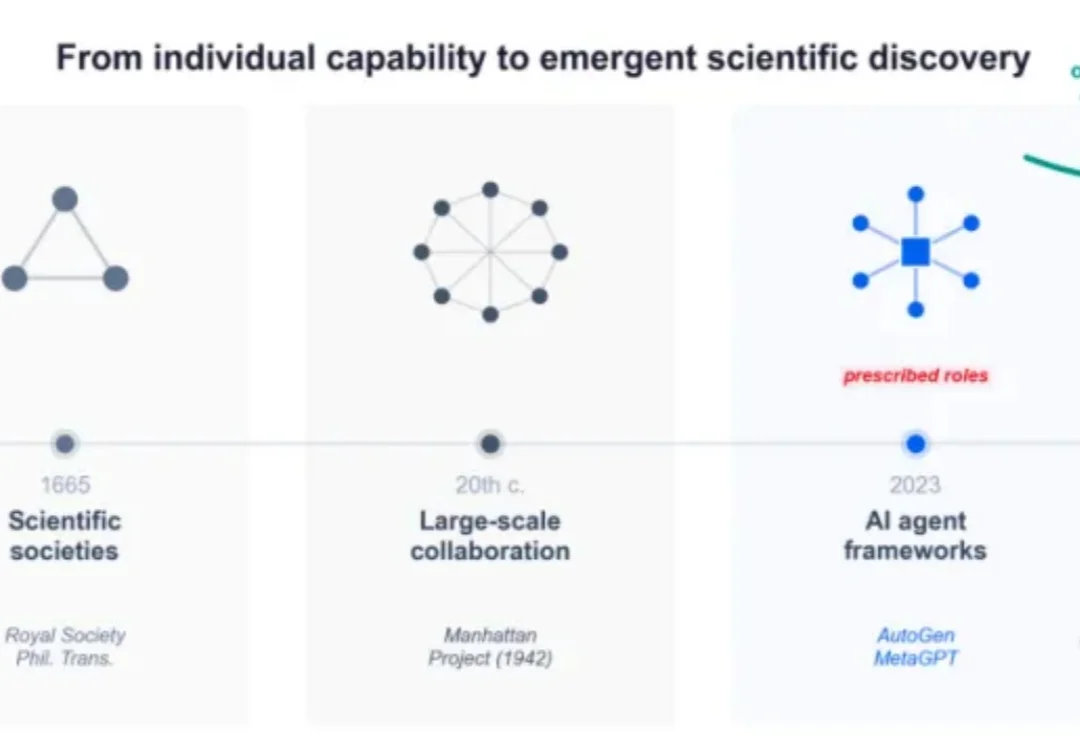
过去一年,由斯坦福大学丛乐(Le Cong)与普林斯顿大学王梦迪(Mengdi Wang)领衔的AI科研团队,一直在做同一件事: 把越来越多的异质能力,纳入同一个协同视野。

6月14日,谷歌CEO皮查伊登上斯坦福毕业典礼,用一场「选择乐观」的沉默演讲,暴露出硅谷AI胜利叙事正在年轻人面前失灵。

过去两年,大模型写代码已经不再新鲜。从代码补全到 GitHub issue 修复,从竞赛编程到仓库级软件工程,人们习惯用一个简单标准评估 coding agent:代码能不能写对?测试能不能通过?
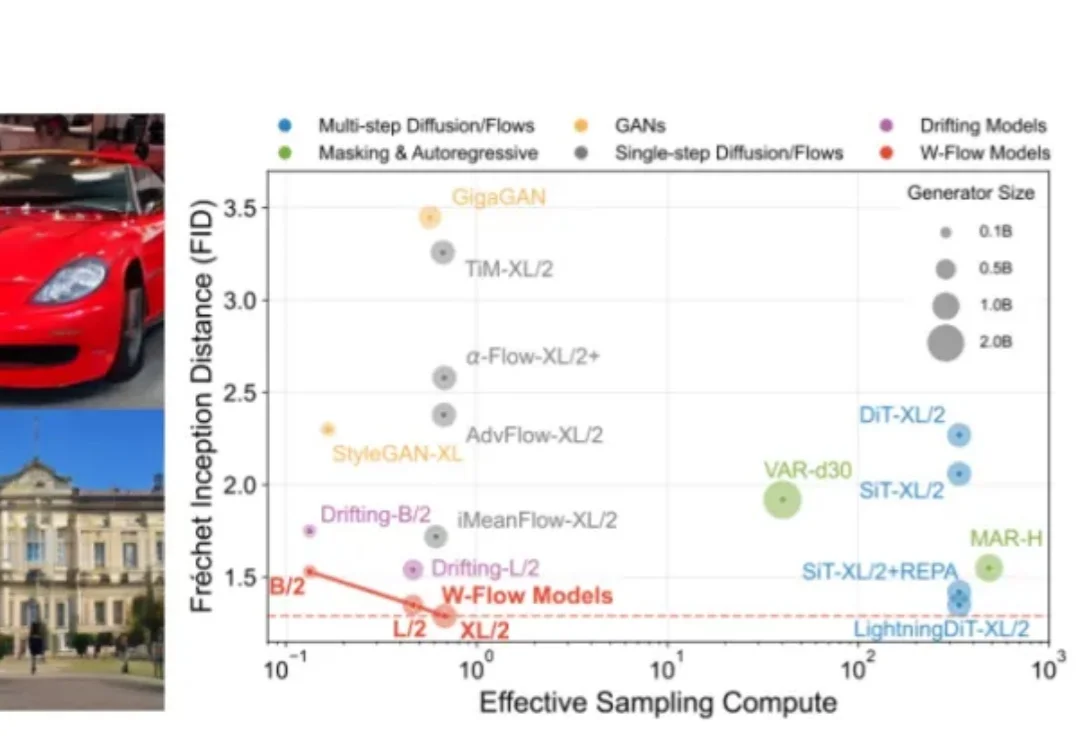
训练时让分布沿最优传输的 “下山方向” 走,推理时只需一次网络前向。W-Flow 把多步演化压进静态生成器,在 ImageNet 256×256 上刷新一步生成指标。

七年前,美国小伙 John Dean 从斯坦福大学辍学和几个同学创立了 AI 气象预测公司 WindBorne,为的是造更好的气球、建更好的 AI 天气预测模型,到如今他们已经拿出了第六代产品 WeatherMesh 6,预测准确度甚至超过老牌气象预测机构欧洲中期天气预报中心。

就在前两天,斯坦福大学等机构发布了一个名为 GPIC(Giant Permissive Image Corpus,巨型开放图像语料库)的数据集。