AI落地前端实操,带你成为公司最懂AI的前端大佬!
AI落地前端实操,带你成为公司最懂AI的前端大佬!基于公司私有组件生成代码,这个问题的本质是:由于大模型的训练数据集不包含你公司的私有组件数据,因此不能够生成符合公司私有组件库的代码。
来自主题: AI技术研报
12929 点击 2024-09-02 12:42
 搜索
搜索
基于公司私有组件生成代码,这个问题的本质是:由于大模型的训练数据集不包含你公司的私有组件数据,因此不能够生成符合公司私有组件库的代码。

今年以来,具身智能正在成为学术界和产业界的热门领域,相关的产品和成果层出不穷。

Emory大学的研究团队提出了一种创新的方法,将大语言模型(LLM)在文本图(Text-Attributed Graph, 缩写为TAG)学习中的强大能力蒸馏到本地模型中,以应对文本图学习中的数据稀缺、隐私保护和成本问题。通过训练一个解释器模型来理解LLM的推理过程,并对学生模型进行对齐优化,在多个数据集上实现了显著的性能提升,平均提高了6.2%。

一键下载最大的视频分割数据集
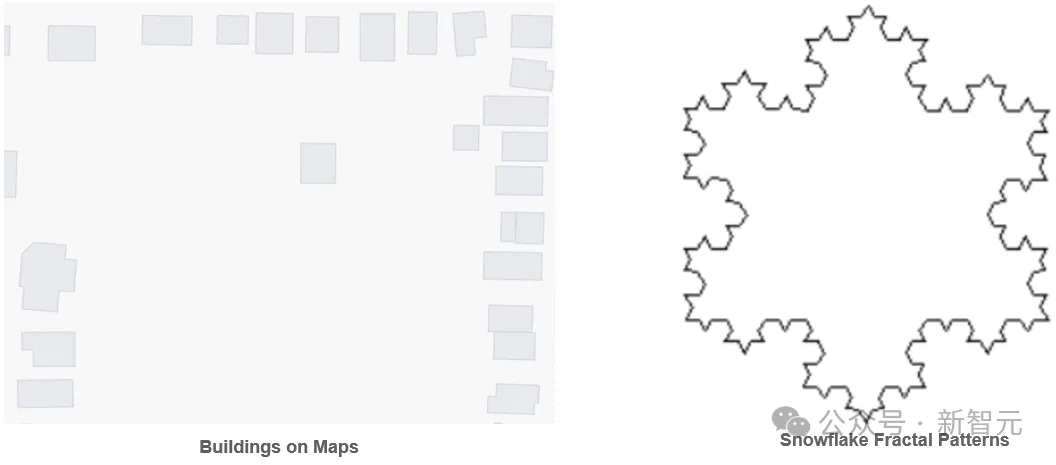
PolygonGNN是一种新型框架,用于学习包括单一和多重多边形在内的多边形几何体的表征,它通过异质可见图来捕捉多边形内外的空间关系,并利用图神经网络有效处理这些关系,以提高计算效率和泛化能力。该框架在五个数据集上表现出色,证明了其在捕捉多边形几何体有用表征方面的有效性。

现在,长上下文视觉语言模型(VLM)有了新的全栈解决方案 ——LongVILA,它集系统、模型训练与数据集开发于一体。

“乱世”其实早已到来,只不过这次是公开承认了这个现实。
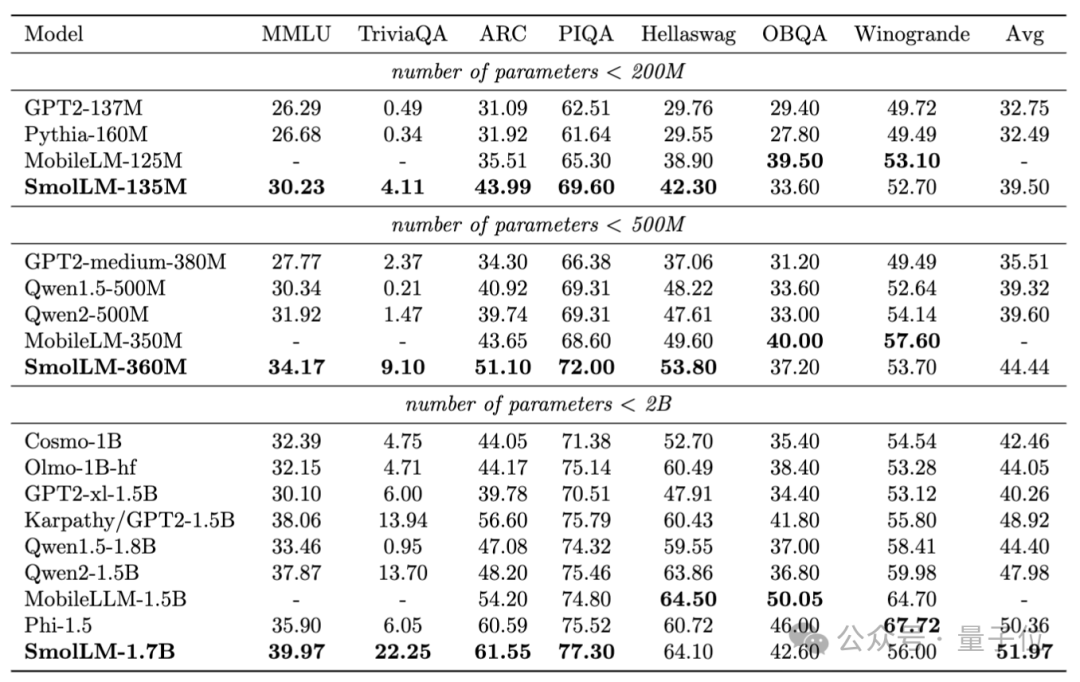
浏览器里直接能跑的SOTA小模型来了,分别在2亿、5亿和20亿级别获胜,抱抱脸出品。
近日,HCM领域的SaaS巨头Workday和全球排名第一的CRM企业Salesforce达成AI战略合作,意在结合Salesforce在客户关系管理领域方面的专业知识以及Workday在人力资源、财务管理方面的优势,试图通过当下先进的人工智能功能和统一的数据集成技术重新构想全新的企业软件。

随着大模型的快速发展,指令调优在提升模型性能和泛化能力方面发挥着至关重要的作用。