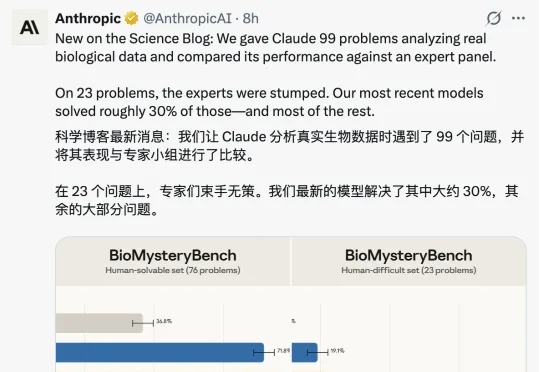
「生物信息学」评测,Claude 反超人类专家
「生物信息学」评测,Claude 反超人类专家今天 Anthropic 放出了一项评估数据,对于新的生物信息学评测集 BioMysteryBench:人类能搞定的,Claude 也能搞定;在人类搞不定的,Mythos 也能搞定
来自主题: AI技术研报
9168 点击 2026-05-01 11:08
 搜索
搜索
今天 Anthropic 放出了一项评估数据,对于新的生物信息学评测集 BioMysteryBench:人类能搞定的,Claude 也能搞定;在人类搞不定的,Mythos 也能搞定

AI医疗最成熟的领域,迎来了一款重磅产品——颅脑CT超级智能体“小君医生2.0”。这是全球首个临床可用+检查项目级的颅脑CT智能体,能够覆盖90%的颅脑病变,诊断准确率达87.8%,90%以上病例无需修改或仅小幅度修改即可使用,将报告时效从15分钟大幅压缩至1分钟,已落地中国顶流三甲北京天坛医院,极大提升了医院影像诊断的效率。
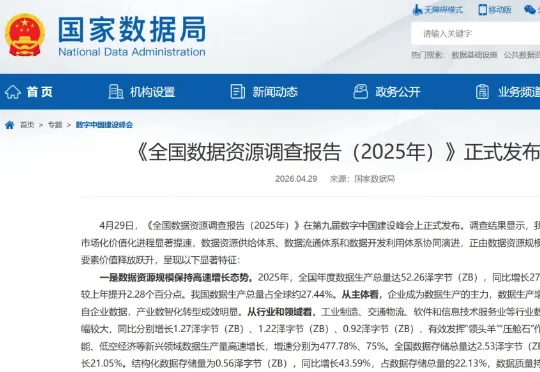
据央视新闻报道,今天,《全国数据资源调查报告(2025 年)》在第九届数字中国建设峰会上发布。报告显示,2025 年,全国数据生产总量同比增长 27.28%,达到 52.26ZB(ZettaByte,泽字节 | 1ZB=1024EB),这相当于全国所有算力中心存储容量的近 30 倍。从国际来看,我国数据生产总量占全球的 27.44%。

在数字中国建设峰会上,平头哥发布首款智能网卡磐脉 920。这是国内首个内置 PCIe Switch 的 400G 智能网卡,最大支持 400Gbps 吞吐带宽,可应用于万卡智算集群、通算集群和高性能存储等场景,目前已经量产,并将率先部署在阿里云数据中心。
普林斯顿大学助理教授刘壮,在学术圈是一个颇为特殊的存在——他的每一篇论文几乎都在质疑某个“理所当然”的假设。架构真的重要吗?数据集真的足够多样吗?归一化层是必需的吗?大语言模型有世界模型吗?AI智能体能替代博士生吗?

一个从未生产过任何产品的品牌,被AI认定为"值得推荐"。从注册到上榜,两个小时。这不是故事的开头。这是315晚会上,所有人都看到的那一幕。为了搞清楚当下GEO市场的扑朔迷离,摸清楚那些GEO的坑到底是怎么产生的虚假资质、批量灌稿、数据造假,手法越来越隐蔽,规模越来越工业化。315撕开的那道口子,下面是一整座冰山。

就在这一背景下,银河通用联合清华北大英伟达等众多机构联合发布了跨本体「隐式世界-动作基础模型」LDA-1B,将目光投向了具身智能 Scaling Law 的这个终极命题:如何让模型有效利用互联网规模的异构数据。

4月20日,最高人民法院副院长陶凯元在2026年知识产权宣传周新闻发布会上,说了一句被很多人忽略的话:「数据、人工智能等新兴领域技术迭代快,权利边界和权属相对复杂,保护规则亟需明确。人民法院妥善审理涉AI生成内容、AI模型参数等前沿问题的民事案件……最高人民法院正在抓紧起草关于依法妥善审理涉人工智能纠纷案件的意见,努力推动人工智能朝着有益、安全、公平的方向健康有序发展。」
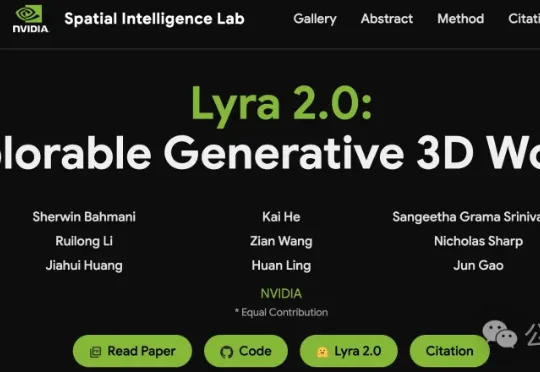
谷歌还在闭源守宝,NVIDIA已把Lyra 2.0全开源:35步去噪变4步,2D图片直出3D高斯泼溅+网格。社交狂欢背后,是对具身AI仿真的巨大潜力——以后造世界,不用再去真实世界采数据了。

这个人叫 Alex Gerko,今年 46 岁,他是量化交易巨头 XTX Markets 的创始人。早在 ChatGPT 成为全民话题之前,他就已经搭建起一套纯粹以盈利为目的的 AI 交易系统。他在冰岛部署的这台超级计算机,正是 XTX 交易帝国的“算力大脑”。这台机器存储着超过 400 PB(约相当于 80 万亿张高清数码照片)的全球金融市场数据,并驱动着庞大的 GPU 集群。