大LLM输出就一定好吗,LLM嵌入用于回归任务,斯坦福和谷歌最新突破性发现与实践指南
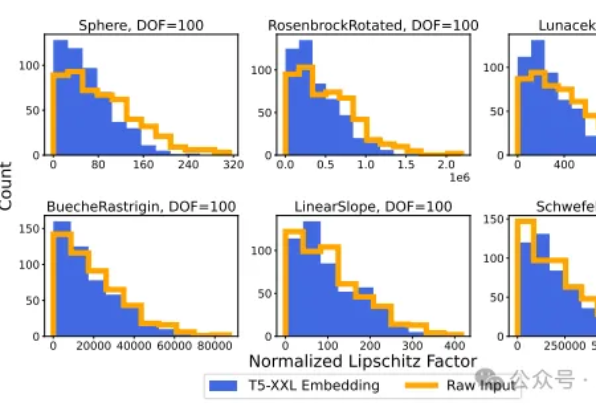
大LLM输出就一定好吗,LLM嵌入用于回归任务,斯坦福和谷歌最新突破性发现与实践指南在人工智能领域,大语言模型(LLM)的向量嵌入能力一直被视为处理文本数据的利器。然而,斯坦福大学和Google DeepMind的研究团队带来了一个颠覆性发现:LLM的向量嵌入能力可以有效应用于回归任务。
来自主题: AI技术研报
7255 点击 2024-11-26 09:04
 搜索
搜索
在人工智能领域,大语言模型(LLM)的向量嵌入能力一直被视为处理文本数据的利器。然而,斯坦福大学和Google DeepMind的研究团队带来了一个颠覆性发现:LLM的向量嵌入能力可以有效应用于回归任务。
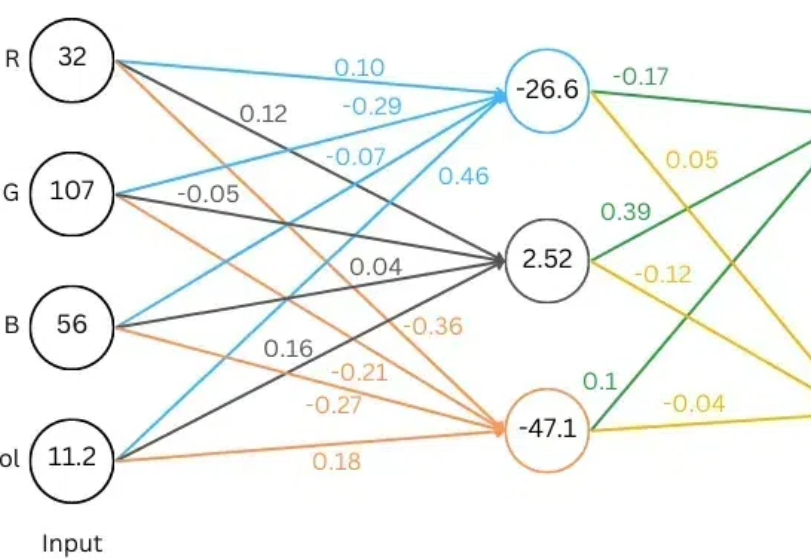
最近,Meta Gen AI 部门的数据科学总监 Rohit Patel 听到了你的心声。他用加法和乘法 —— 小学二年级的数学知识,深入浅出地解析了大模型的基础原理。
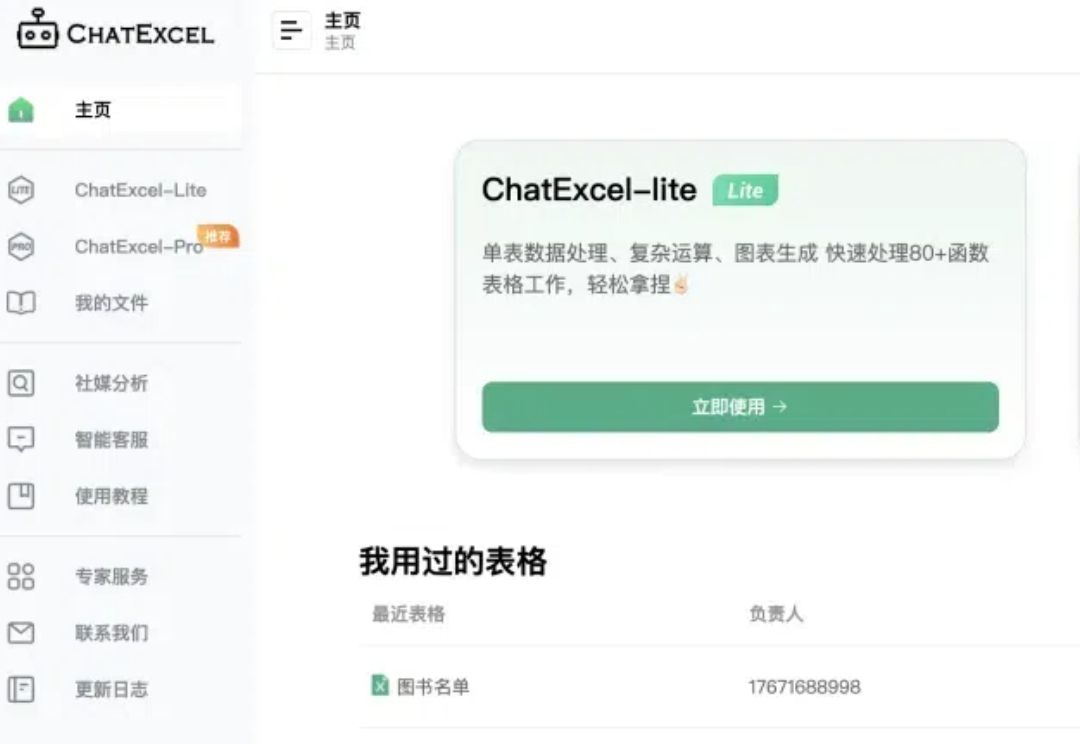
AI做Excel表,现在next level了—— 北大团队ChatExcel最新升级,一句话搞定线性分析,图表、文字总结全都有。
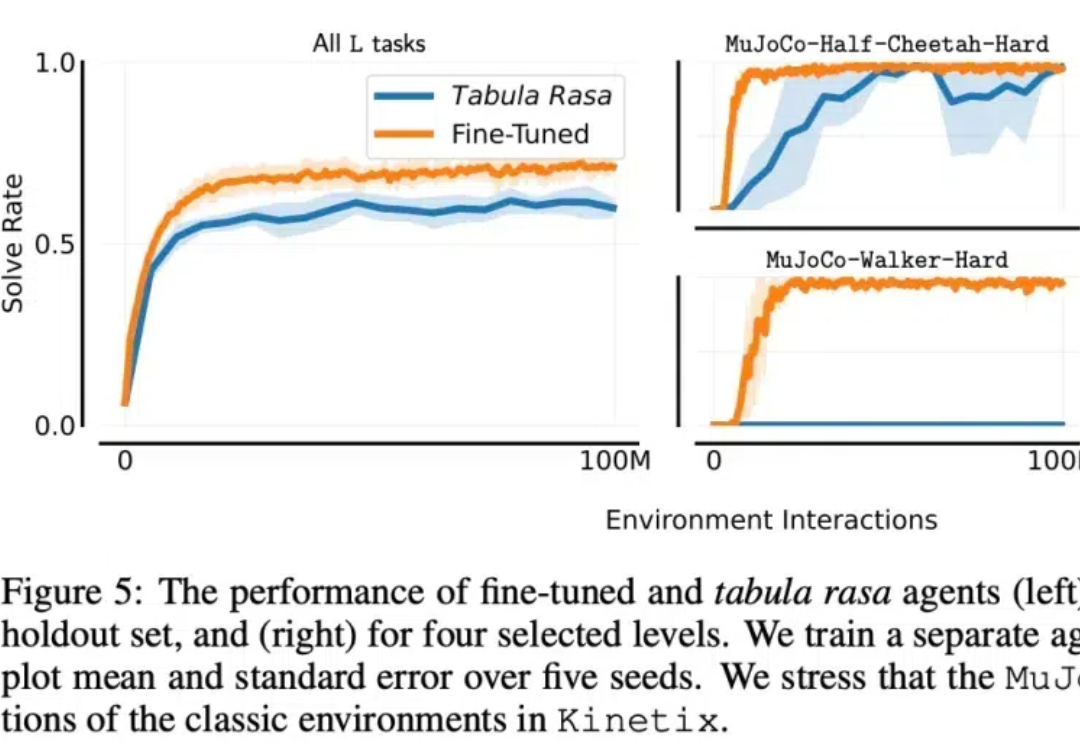
在机器学习领域,开发一个在未见过领域表现出色的通用智能体一直是长期目标之一。一种观点认为,在大量离线文本和视频数据上训练的大型 transformer 最终可以实现这一目标。
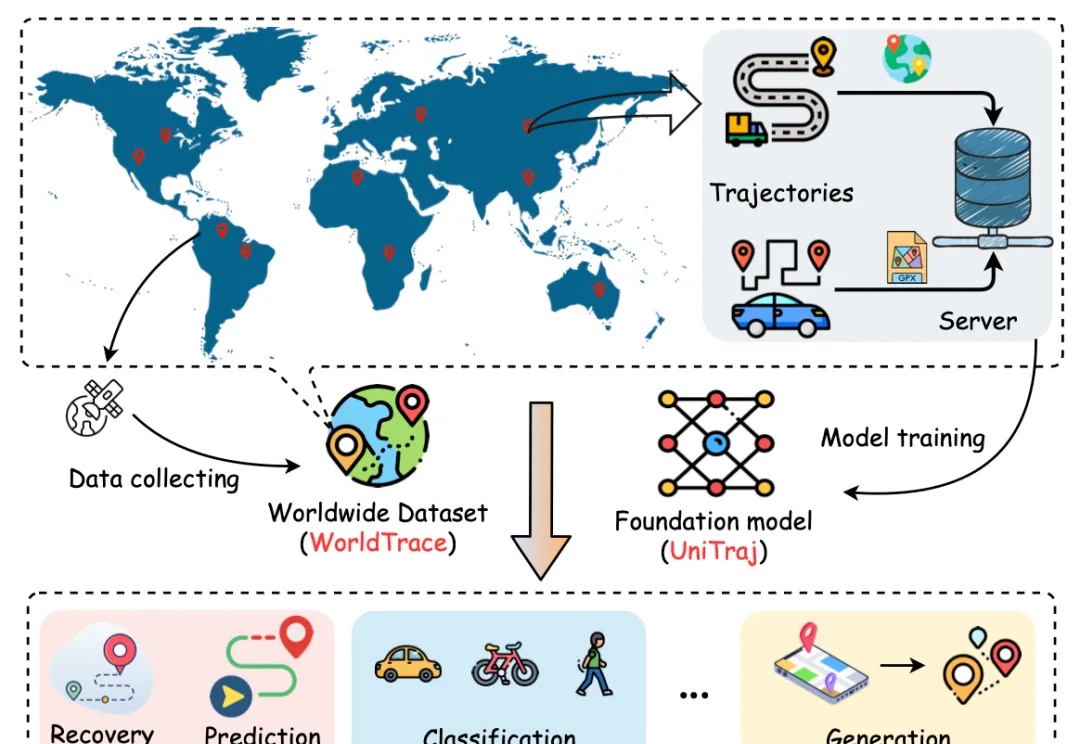
在智慧城市和大数据时代背景下,人类轨迹数据的分析对于交通优化、城市管理、物流配送等关键领域具有重要意义。然而,现有的轨迹相关模型往往受限于特定任务、区域依赖、轨迹数据规模和多样性困乏等问题,限制了模型的泛化能力和实际应用范围。
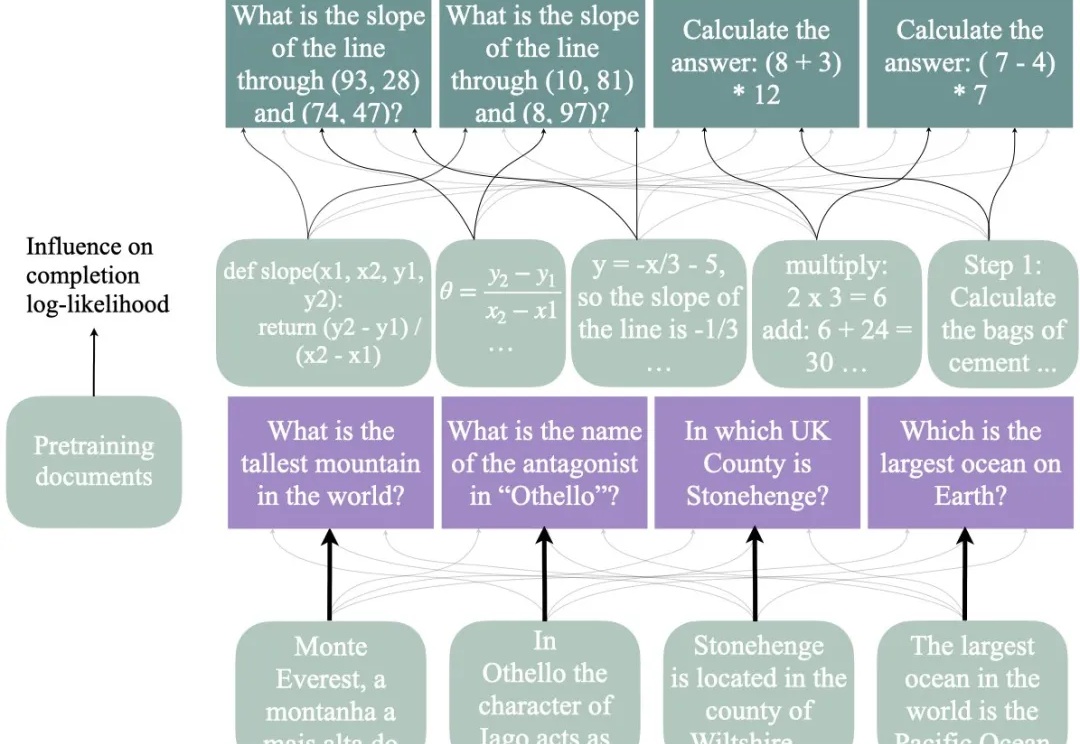
大模型不会照搬训练数据中的数学推理,回答事实问题和推理问题的「思路」也不一样。

最近,Jim Fan参与的一项研究推出了自动化数据生成系统DexMimicGen。该系统可基于少量人类演示,合成类人机器人的灵巧手运动轨迹,解决了训练数据集的获取难题,而且还提升了实验中机器人的表现。

Teleo 自称是一家建筑机器人初创公司,但它的使命远不止于自动化挖掘机和拖拉机等重型设备。如今,Teleo 的改装机械使其客户能够半自主地操作现有车队。在未来,这家初创公司将其收集的数据视为机器人行业实现“ChatGPT 时刻”的关键推动力。
根据一份 SEC 文件 Crusoe Energe ,一家正在建设数据中心的初创公司,据报道将租赁给甲骨文、微软和 OpenAI,正在筹集 8.18 亿美元。
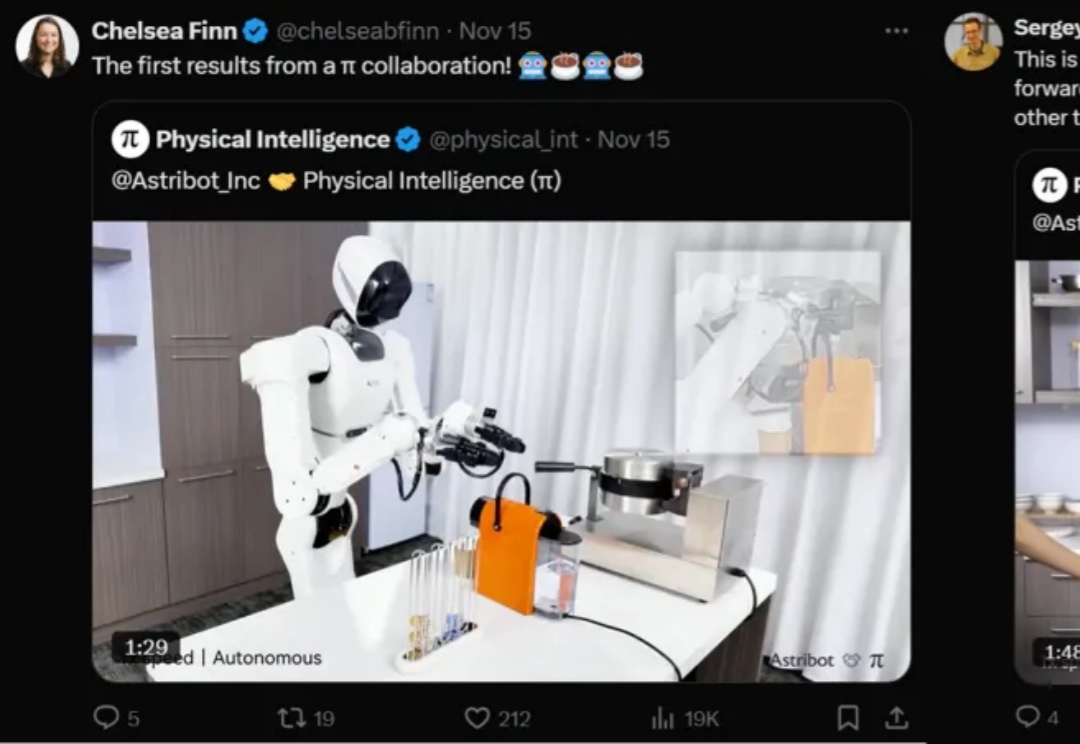
近日,Physical Intelligence和星尘智能宣告牵手,在数据和模型层展开合作,推进通用人工智能进入物理世界,共筑世界模型。