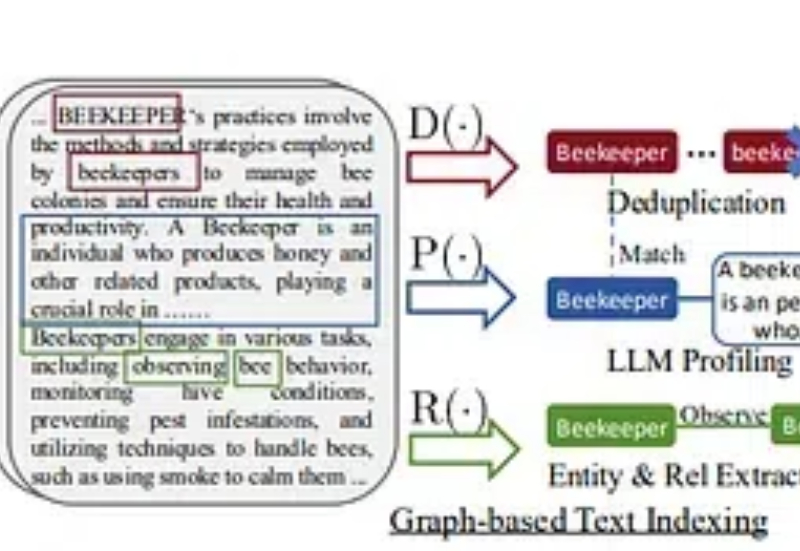
Browser-Use + LightRAG Agent:可使用 LLM 抓取 99% 的网站
Browser-Use + LightRAG Agent:可使用 LLM 抓取 99% 的网站在这个故事中,我将提供一个快速教程,展示如何使用浏览器使用、LightRAG和本地LLM创建一个强大的聊天机器人,以开发一个能够抓取您选择的任何网站的AI代理。此外,您可以询问有关您的数据的问题,这将为您提供该问题的回答。
来自主题: AI资讯
9982 点击 2024-12-29 11:10
 搜索
搜索
在这个故事中,我将提供一个快速教程,展示如何使用浏览器使用、LightRAG和本地LLM创建一个强大的聊天机器人,以开发一个能够抓取您选择的任何网站的AI代理。此外,您可以询问有关您的数据的问题,这将为您提供该问题的回答。

本月,OpenAI科学家就当前LLM的scaling方法论能否实现AGI话题展开深入辩论,认为将来AI至少与人类平分秋色;LLM scaling目前的问题可以通过后训练、强化学习、合成数据、智能体协作等方法得到解决;按现在的趋势估计,明年LLM就能赢得IMO金牌。

我们将讨论的不仅仅是哪个超级大国会胜出,而是哪个国家的AI系统会成为全球基础设施的基石,能够被广泛采用和输出。

最好的办法就是一开始就保持绝对的真实和坦诚,营造一种真诚和透明的氛围。如果在这种过程中发现不合适,那其实是好事,因为比起在后期出现问题,早期发现不合适要好得多。

最近在舰长扣子Coze交流群中最新组织了一次快闪活动,邀请了影刀RPA晴岚老师,技术讲解如何搭建《通过关键词批量抓取小红书涨粉吸睛情报》的影刀RPA工作流.效果十分不错,这不舰长将RPA和Coze进行了一次结合

《智能涌现》独家获悉,前微软亚洲研究院研究员、阿里达摩院资深技术专家、支付宝中国首席数据官胡云华加入大模型独角兽智谱,担任C端应用“智谱清言”负责人。

如何将这个应用到你的实际营销中可能成效并不明显,但一个值得注意的变化是模型成本的贬值。你可能没有意识到,AI是有史以来折旧速度最快的技术。
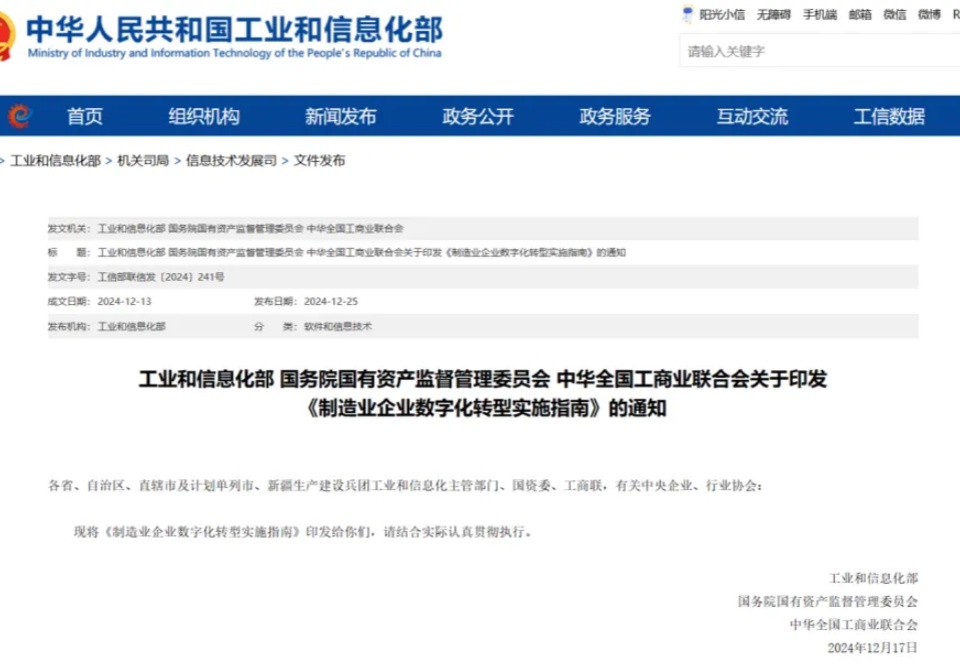
据工业和信息化部网站25日消息,工业和信息化部、国务院国有资产监督管理委员会、中华全国工商业联合会日前印发《制造业企业数字化转型实施指南》。

智源研究院提出了 BAAIWorm 天宝 -- 一个全新的、基于数据驱动的生物智能模拟系统,首次实现秀丽线虫神经系统、身体与环境的闭环仿真。BAAIWorm 天宝通过构建线虫的精细神经系统、身体和环境模型,为探索大脑与行为之间的神经机制提供重要研究平台。
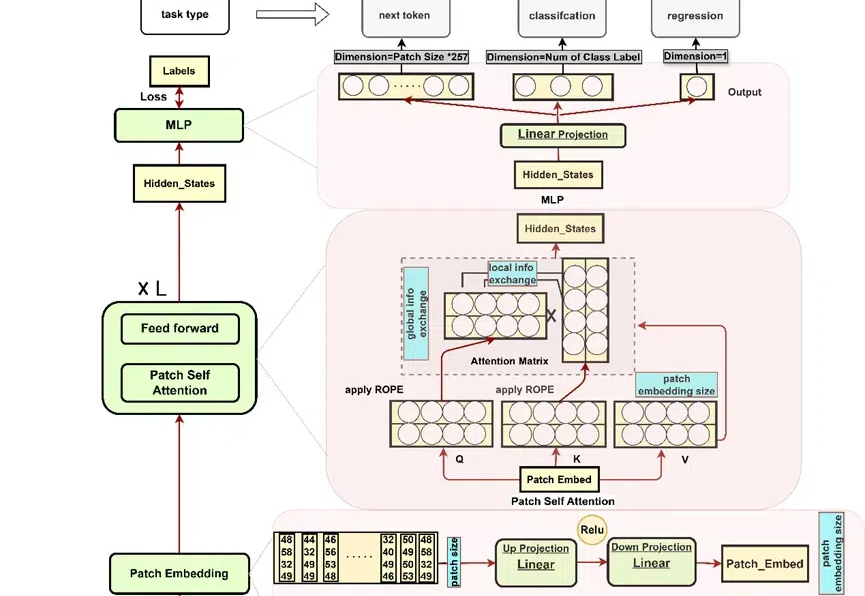
大语言模型能否解决传统大语言模型在大规模数值数据分析中的局限性问题,助力科学界大科学装置设计、高能物理领域科学计算?