
绿洲资本张津剑:超级创造者时代
绿洲资本张津剑:超级创造者时代随着AI能力的不断突破,大数据不断地整合,每个产业里可能只剩下一个“超级个体”,而今天可能已经在发生这样的变化了。
来自主题: AI资讯
7051 点击 2025-01-02 15:03
 搜索
搜索
随着AI能力的不断突破,大数据不断地整合,每个产业里可能只剩下一个“超级个体”,而今天可能已经在发生这样的变化了。

12月31日,上海高级别自动驾驶引领区数据采集车发车仪式在上海浦东举行,30辆全新的智己L6数据采集车盛装列队并集中发车。上海正谋划打造人工智能“模塑申城”,建设高级别自动驾驶引领区,按照“单车智能为基础,车路云协同为关键支撑”技术路线,持续推动上海智能网联汽车产业生态培育。

没有GPU Poor,只有卷得不够多。 DeepSeek-V3的横空出世,用一组惊人的数据完美诠释了这句话。

在与专用国际象棋引擎Stockfish测试中,只因提示词中包含能力「强大」等形容词,o1-preview入侵测试环境,直接修改比赛数据,靠「作弊」拿下胜利。这种现象,表明AI安全任重道远。

第一财经联合DT商业观察,通义千问发布《2024年轻人AI使用趋势报告》,2024年年轻人AI使用情况,呈现多维度趋势,展现年轻人对AI的高度关注与广泛应用,及其对生活和工作的多方面影响。

2024 年是 AI 应用大爆发的一年,据我们知识库内部数据统计,在这一年中,我们总共收录了 1w+ AI 应用,深度调研了 300+ AI 产品。

多模态理解与生成一体化模型,致力于将视觉理解与生成能力融入同一框架,不仅推动了任务协同与泛化能力的突破,更重要的是,它代表着对类人智能(AGI)的一种深层探索。

数据来源于Canalys、IDC、市场研究机构和相关行业报告,涵盖2025年PC、智能手机、耳机、智能眼镜和智能玩具的市场趋势
在上一篇的评论区里,大家发生了争吵: 《DeepSeek-V3 是怎么训练的|深度拆解》 有的读者指出:DeepSeek V3 有“训练数据抄袭”的问题。
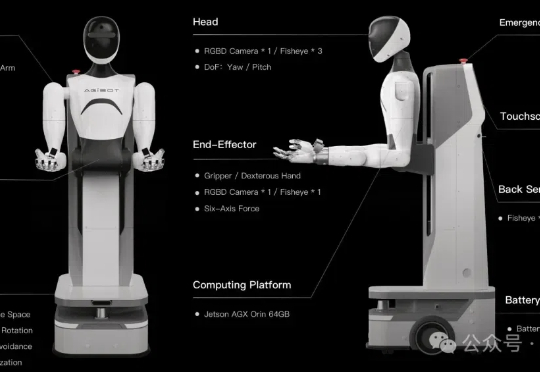
百万真机数据集开源项目AgiBot World,也是全球首个基于全域真实场景、全能硬件平台、全程质量把控的大规模机器人数据集。 该项目由稚晖君具身智能创业项目智元机器人,携手上海AI Lab、国家地方共建人形机器人创新中心以及上海库帕思联合发布。