
年入1.34亿,AI包工头成硅谷最慷慨老板
年入1.34亿,AI包工头成硅谷最慷慨老板人工智能众包工作初创公司Invisible Technologies取得了巨大成功。而今,其创始人正拿它当作抵押进行借款,好买断其风投支持者的股份。
来自主题: AI资讯
7713 点击 2025-02-20 10:51
 搜索
搜索
人工智能众包工作初创公司Invisible Technologies取得了巨大成功。而今,其创始人正拿它当作抵押进行借款,好买断其风投支持者的股份。

RedStone是一个高效构建大规模指定领域数据的处理管道,通过优化数据处理流程,从Common Crawl中提取了RedStone-Web、RedStone-Code、RedStone-Math和RedStone-QA等数据集,在多项任务中超越了现有开源数据集,显著提升了模型性能。

强化学习训练数据越多,模型推理能力就越强?新研究提出LIM方法,揭示提升推理能力的关键在于优化数据质量,而不是数据规模。该方法在小模型上优势尽显。从此,强化学习Scaling Law可能要被改写了!
这次不是卷参数、卷算力,而是卷“跨界学习”——

没有治理的人工智能?一场等待发生的灾难。我们经常听说数据治理和人工智能是矛盾的,一个注重控制,另一个注重速度和创新。但如果我告诉你数据治理实际上是一个人工智能加速器呢?

三星发布Galaxy S25系列,强调AI功能和数据安全。

史上最大规模视觉语言数据集:1000亿图像-文本对!
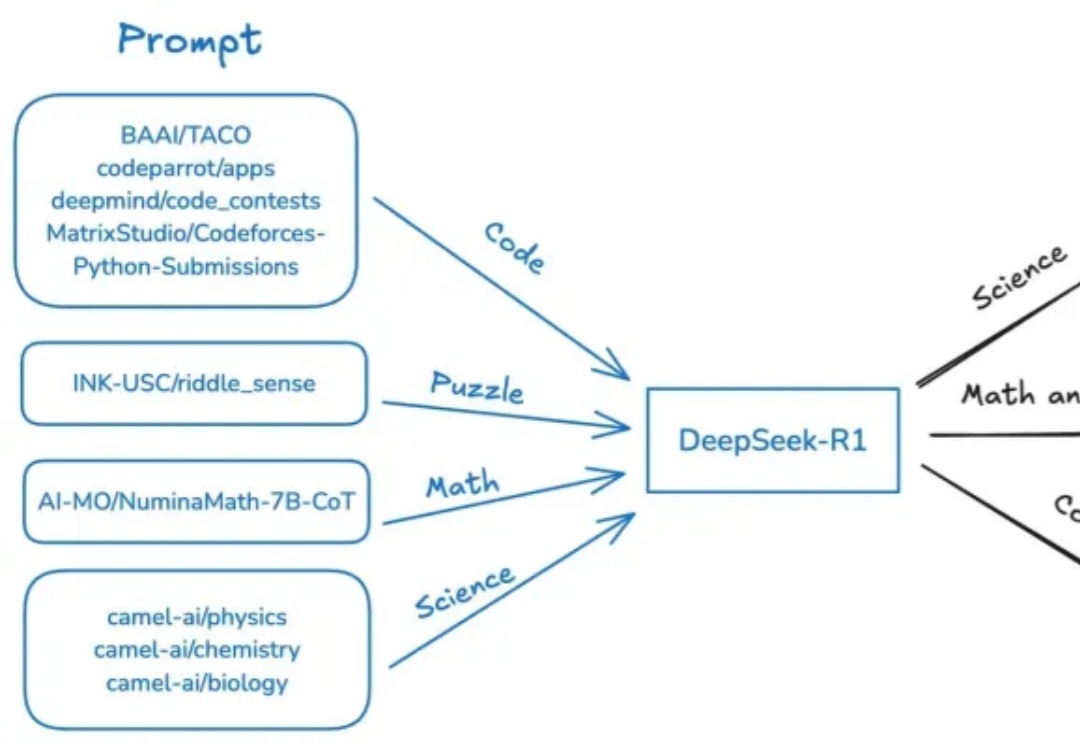
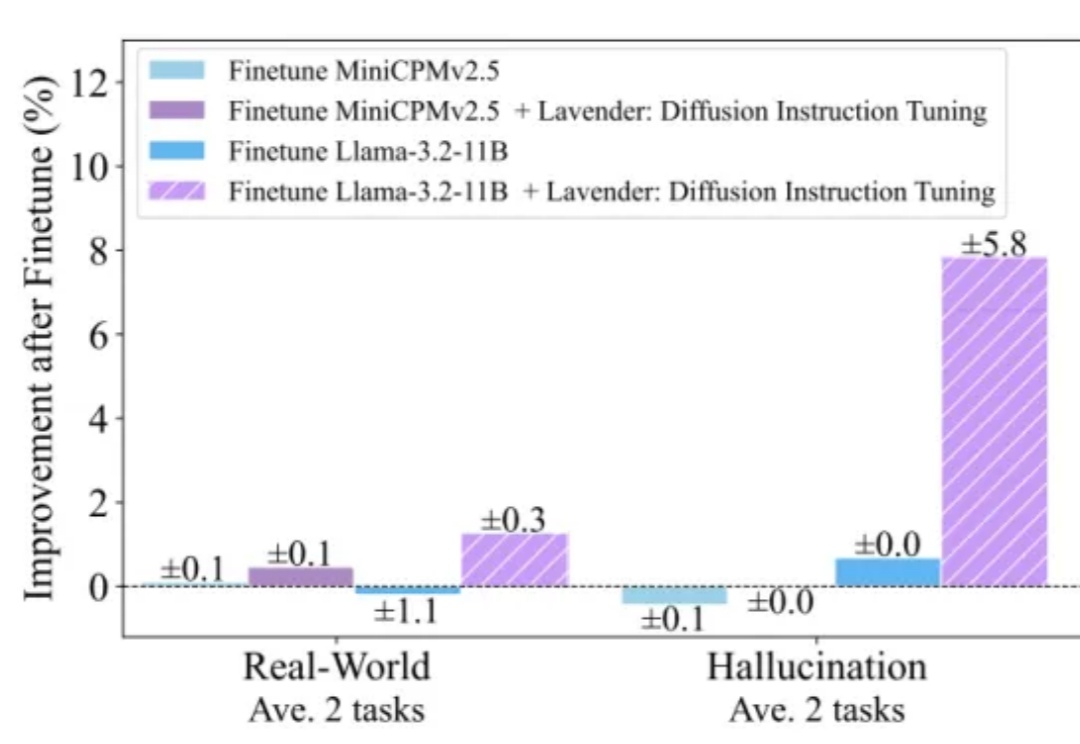
近日,斯坦福、UC伯克利等多机构联手发布了开源推理新SOTA——OpenThinker-32B,性能直逼DeepSeek-R1-32B。其成功秘诀在于数据规模化、严格验证和模型扩展。

一个简单的笑脸😀可能远不止这么简单?最近,AI大神Karpathy发现,一个😀竟然占用了多达53个token!这背后隐藏着Unicode编码的哪些秘密?如何利用这些「隐形字符」在文本中嵌入、传递甚至「隐藏」任意数据。更有趣的是,这种「数据隐藏术」甚至能对AI模型进行「提示注入」!
超级碗再次证明了自己是美国最优秀的职业体育赛事。 作为转播商的福克斯,公布了美国时间2月9日举行的超级碗转播相关记录。福克斯引用收视率调查企业尼尔森,和负责流媒体转播的Tubi,以及NFL官方网站的数据计算,此次超级碗平均有1.26亿人观看。