ICML 2026 | 大模型为什么算不对加法?南大团队提出等本位和轨迹,揭示LLM算术错误的几何机制
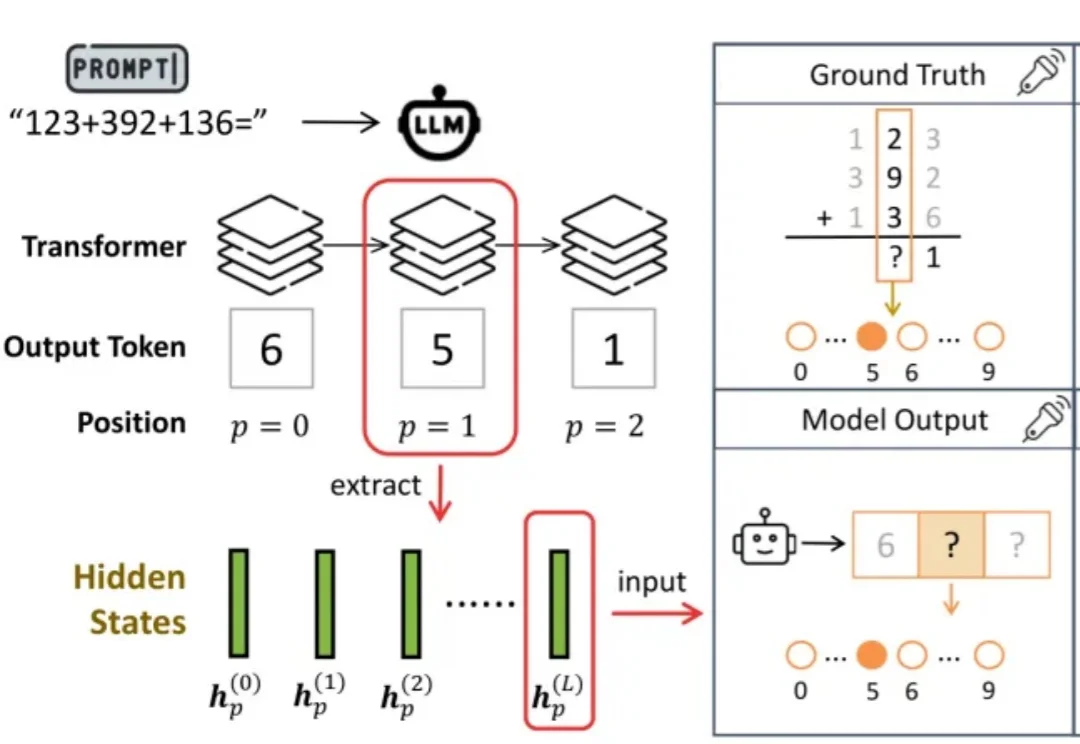
ICML 2026 | 大模型为什么算不对加法?南大团队提出等本位和轨迹,揭示LLM算术错误的几何机制尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。
来自主题: AI技术研报
7425 点击 2026-06-17 14:05
 搜索
搜索
尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。
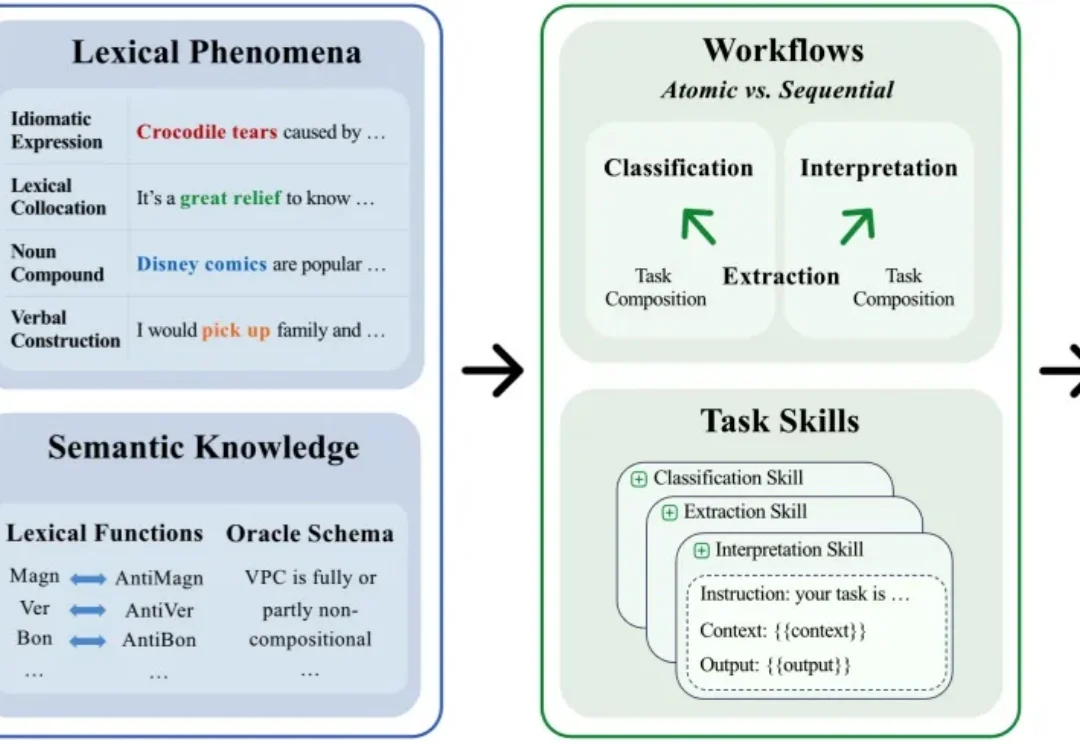
AI 的能力边界正在不断被刷新。从数学推理到代码生成,再到数字化白领,语言模型和语言智能体在诸多基准测试中已展现出超越人类专家的表现。一个看似顺理成章的判断早已成为共识:语言模型已经具备了扎实的语言理解和语义推理能力。然而,ACL 2026 Oral 的一项研究工作从一个更基础的层面重新审视了这个问题:语言模型真的理解(短语)语义吗?
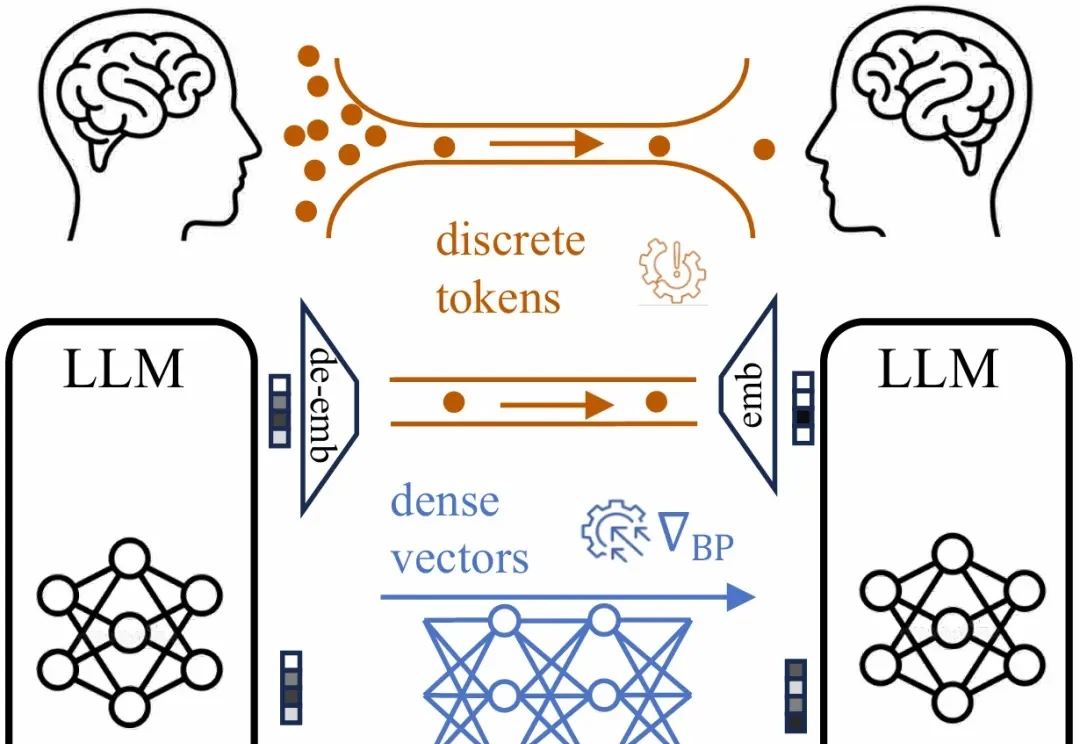
大语言模型正在成为人工智能系统的核心组件。从文本生成、数学推理到代码编写,单个大模型已经展现出强大的能力。

在推理后训练里,多数方法仍依赖奖励模型、验证器或额外教师信号。如果不依赖这些外部信号,只使用模型自身生成的答案进行自训练,是否仍然能够提升推理能力?是的!SePT(Self-evolving Post-Training)给出肯定答案,简洁的自训练方法,可在数学推理任务准确率直升10个点!

2025 年 1 月 20 日,DeepSeek 发布了推理大模型 DeepSeek-R1,在学术界和工业界引发了对大模型强化学习方法的广泛关注与研究热潮。 研究者发现,在数学推理等具有明确答案的任务
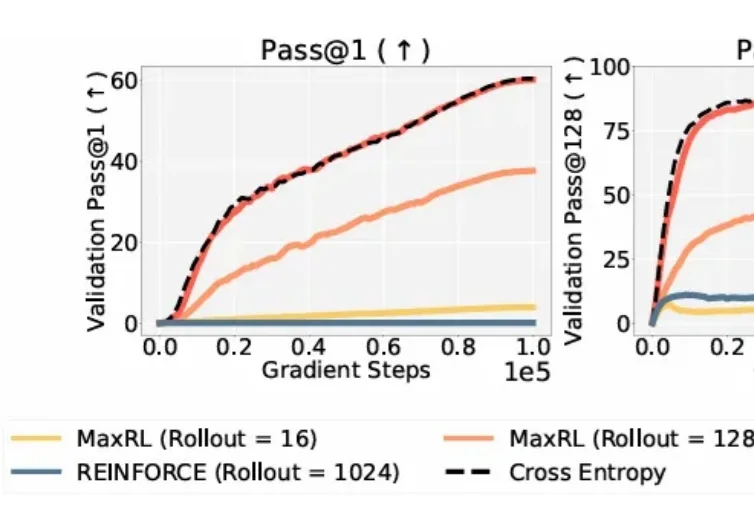
在大模型时代,从代码生成到数学推理,再到自主规划的 Agent 系统,强化学习几乎成了「最后一公里」的标准配置。

就在刚刚,Liquid AI 又一次在 LFM 模型上放大招。他们正式发布并开源了 LFM2.5-1.2B-Thinking,一款可完全在端侧运行的推理模型。Liquid AI 声称,该模型专门为简洁推理而训练;在生成最终答案前,会先生成内部思考轨迹;在端侧级别的低延迟条件下,实现系统化的问题求解;在工具使用、数学推理和指令遵循方面表现尤为出色。
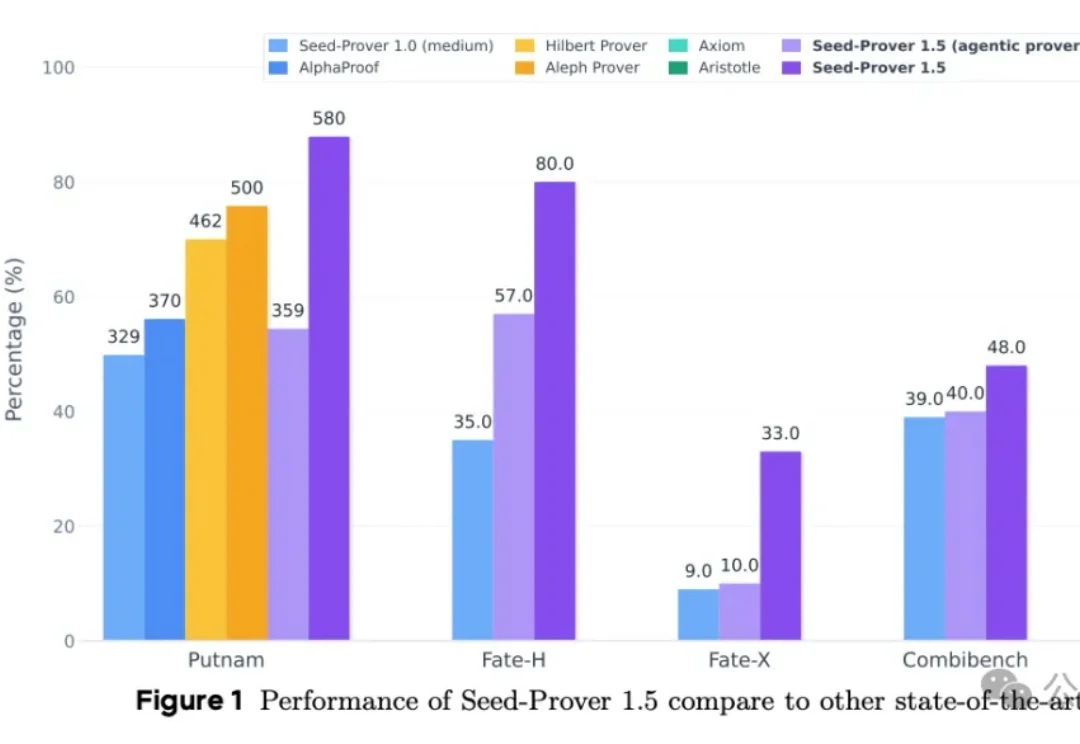
字节最新数学推理专用模型,刚刚刷新战绩:拿下IMO金牌成绩。
就在刚刚,DeepSeek 又悄咪咪在 Hugging Face 上传了一个新模型:DeepSeek-Math-V2。顾名思义,这是一个数学方面的模型。它的上一个版本 ——DeepSeek-Math-7b 还是一年多以前发的。当时,这个模型只用 7B 参数量,就达到了 GPT-4 和 Gemini-Ultra 性能相当的水平。相关论文还首次引入了 GRPO,显著提升了数学推理能力。
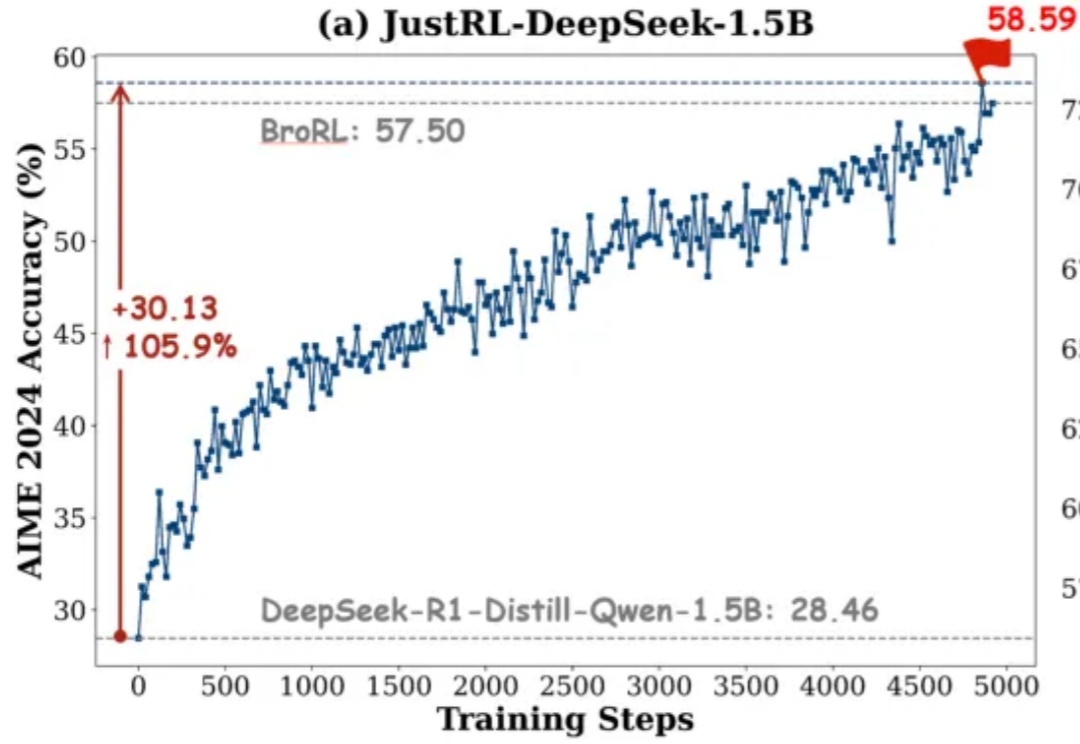
如果有人告诉你:不用分阶段做强化学习、不搞课程学习、不动态调参,只用最基础的 RL 配方就能达到小模型数学推理能力 SOTA,你信吗?