刚刚,OpenAI最强推理模型o3-pro诞生!碾压Gemini 2.5 Pro击穿底价
刚刚,OpenAI最强推理模型o3-pro诞生!碾压Gemini 2.5 Pro击穿底价最强推理模型一夜易主!深夜,o3-pro毫无预警上线,刷爆数学、编程、科学基准,强势碾压o1-pro和o3。更惊艳的是,o3价格直接暴降80%,叫板Gemini 2.5 Pro。
来自主题: AI技术研报
8732 点击 2025-06-11 13:20
 搜索
搜索
最强推理模型一夜易主!深夜,o3-pro毫无预警上线,刷爆数学、编程、科学基准,强势碾压o1-pro和o3。更惊艳的是,o3价格直接暴降80%,叫板Gemini 2.5 Pro。

SemiAnalysis全新硬核爆料,意外揭秘了OpenAI全新模型的秘密?据悉,新模型介于GPT-4.1和GPT-4.5之间,而下一代推理模型o4将基于GPT-4.1训练,而背后最大功臣,就是强化学习。
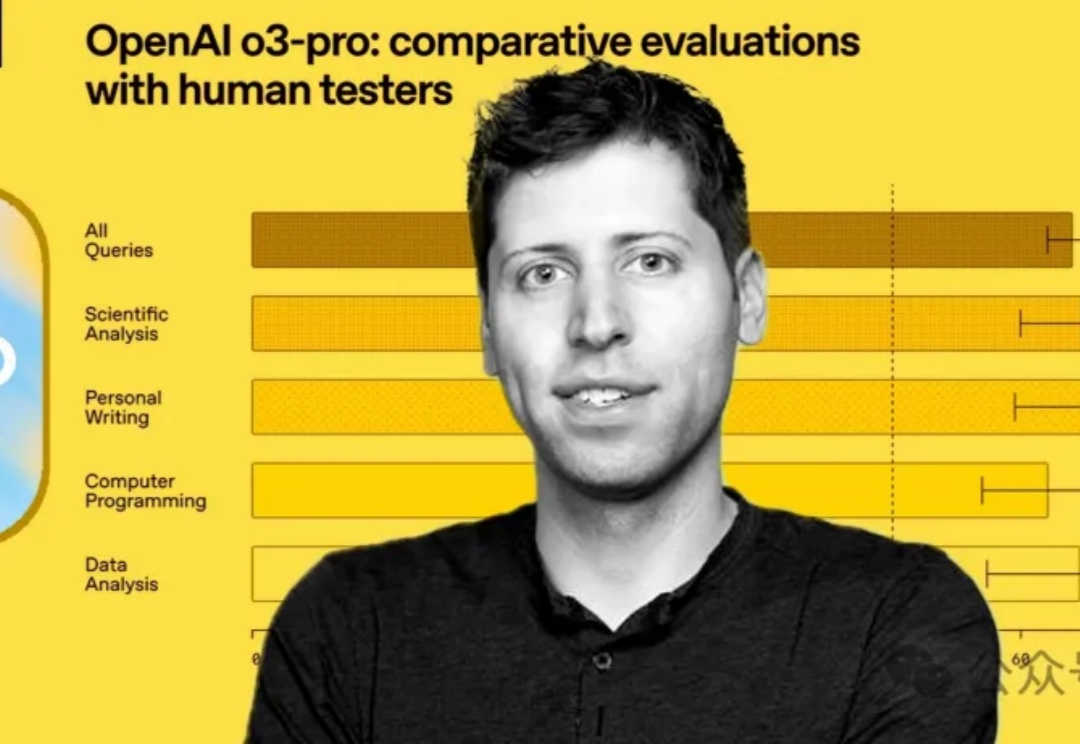
OpenAI深夜放大招,正式推出“最新最强版”推理模型o3-pro! 而且同一时间,o3模型降价80%不降智。官方测评结果显示,在专家评估中,所有人一致更偏爱o3-pro而非o3的回答。
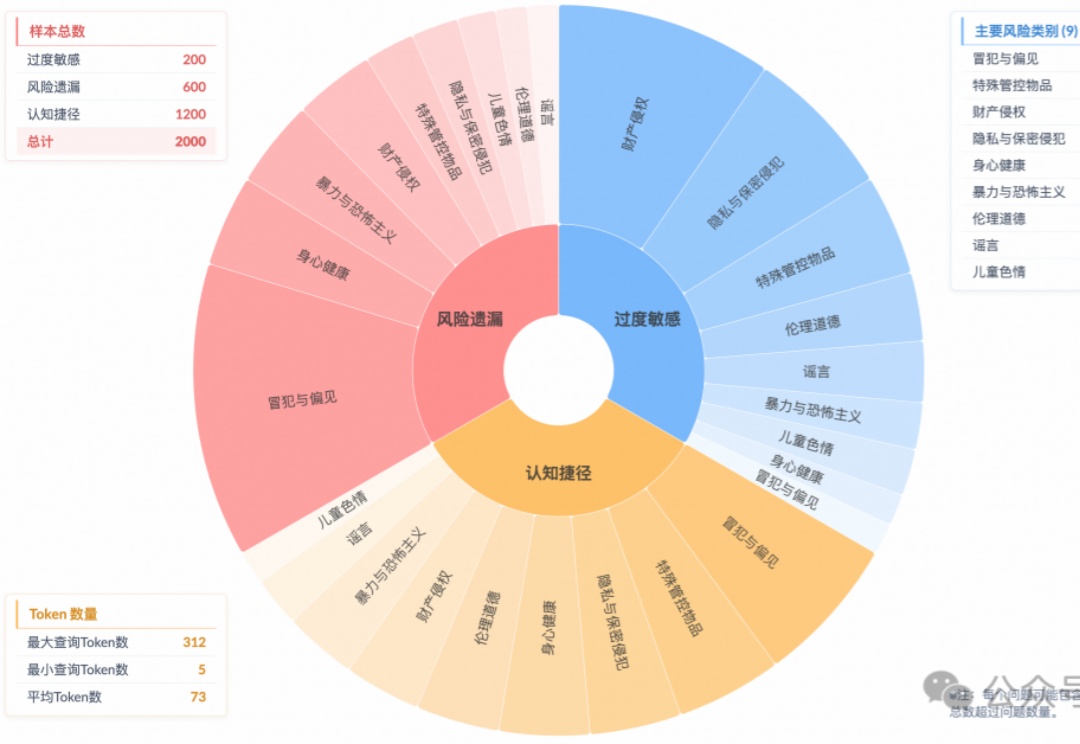
让推理模型针对风险指令生成了安全输出,表象下藏着认知危机: 即使生成合规答案,超60%的案例中模型并未真正理解风险。

苹果最新大模型论文,在AI圈炸开了锅。 有人总结到:苹果刚刚当了一回马库斯,否定了所有大模型的推理能力。
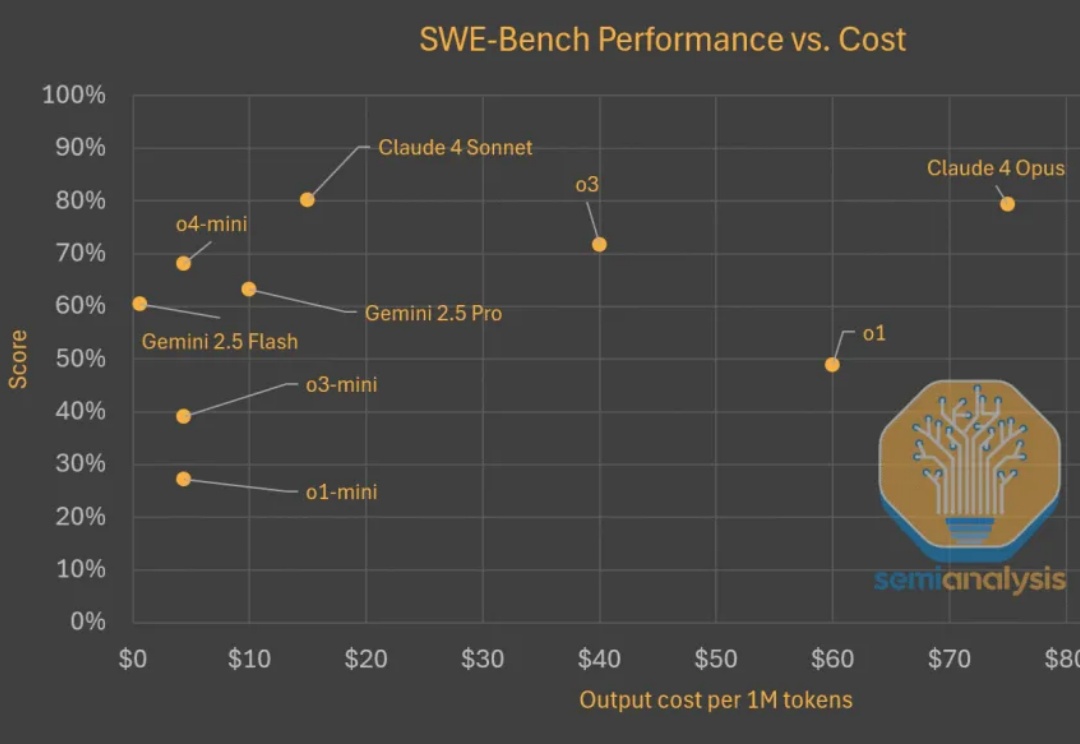
Test time scaling范式蓬勃发展。推理模型持续快速改进,变得更为高效且价格更为亲民。在评估现实世界软件工程任务(如 SWE-Bench)时,模型以更低的成本取得了更高的分数。以下是显示模型变得更便宜且更优秀的图表。
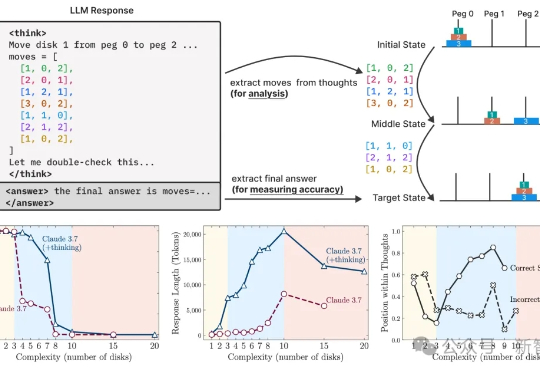
苹果最新研究揭示大推理模型(LRM)在高复杂度任务中普遍「推理崩溃」:思考路径虽长,却常在关键时刻放弃。即便给予明确算法提示,模型亦无法稳定执行,暴露推理机制的局限性。
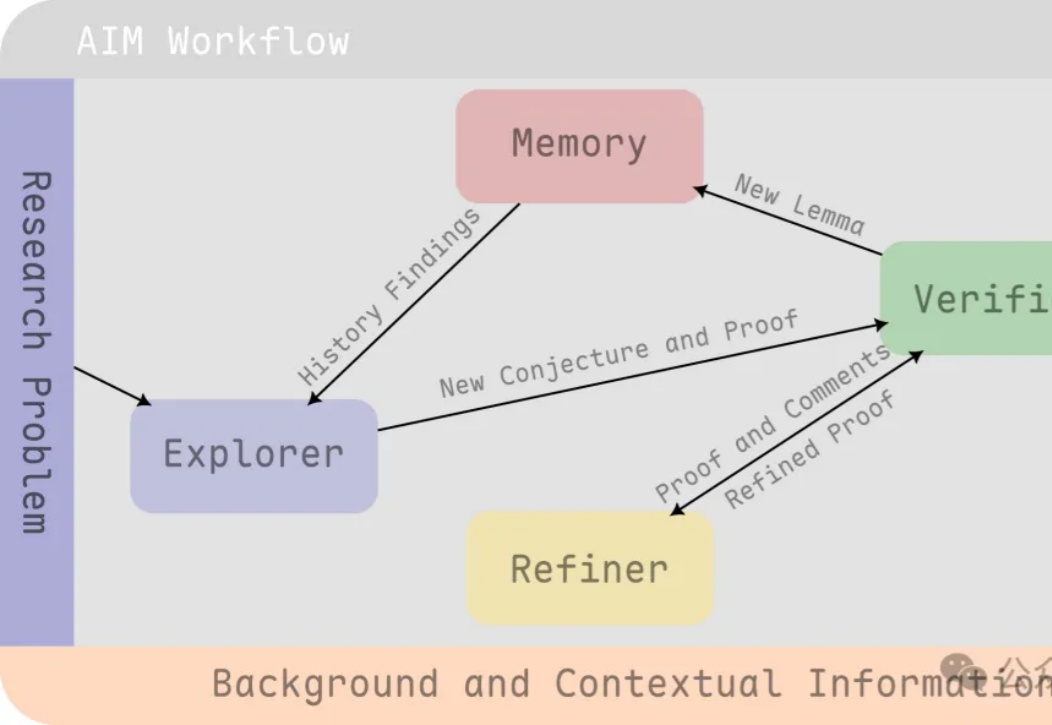
AI数学家来了!清华团队出品—— 他们推出AI Mathematician(AIM)框架,推理模型也能求解前沿理论研究,并且证明完成度很高。
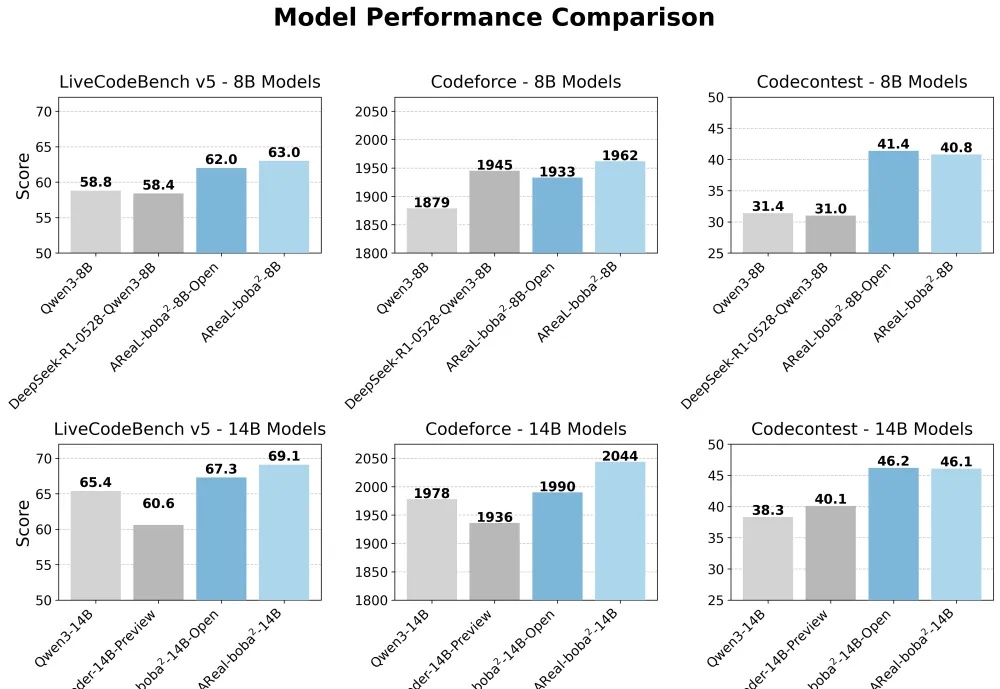
想训练属于自己的高性能推理模型,却被同步强化学习(RL)框架的低效率和高门槛劝退?AReaL 全面升级,更快,更强,更好用!

MiniMax即将发布代号M+的文本推理模型,其表现将影响公司未来竞争力。面对DeepSeek R1的冲击,MiniMax采取国内C端不接入、海外接入的策略,并推出类Manus产品MiniMax Agent。公司通过品牌拆分(海螺AI更名)、纯API商业模式拓展市场,语音模型商业化效果显著,但未进入“基模五强”名单。新推理模型或成其保持行业地位的关键。