
算力成本大降!马尔可夫思考机来了,LLM推理成本直接降为线性
算力成本大降!马尔可夫思考机来了,LLM推理成本直接降为线性Mila 和微软研究院等多家机构的一个联合研究团队却另辟蹊径,提出了一个不同的问题:如果环境从一开始就不会造成计算量的二次级增长呢?他们提出了一种新的范式,其中策略会在基于一个固定大小的状态上进行推理。他们将这样的策略命名为马尔可夫式思考机(Markovian Thinker)。
来自主题: AI技术研报
9759 点击 2025-10-11 11:31
 搜索
搜索
Mila 和微软研究院等多家机构的一个联合研究团队却另辟蹊径,提出了一个不同的问题:如果环境从一开始就不会造成计算量的二次级增长呢?他们提出了一种新的范式,其中策略会在基于一个固定大小的状态上进行推理。他们将这样的策略命名为马尔可夫式思考机(Markovian Thinker)。

英伟达还能“猖狂”多久?——不出三年! 实现AGI需要新的架构吗?——不用,Transformer足矣! “近几年推理成本下降了100倍,未来还有望再降低10倍!” 这些“暴论”,出自Flash Attention的作者——Tri Dao。

刚刚完成1300万美元种子轮融资的Runware,正在用一种完全不同的方式重新定义AI基础设施。他们不依赖现成的云服务提供商,而是从零开始构建了自己的硬件和软件栈,创造出了所谓的"Sonic推理引擎"。这种垂直整合的方法让他们能够将AI推理成本降低高达90%,同时通过单一API提供对超过40万个AI模型的访问。

只用 1.5% 的内存预算,性能就能超越使用完整 KV cache 的模型,这意味着大语言模型的推理成本可以大幅降低。EvolKV 的这一突破为实际部署中的内存优化提供了全新思路。
主打“自动化执行、多模型调用、上下文记忆”的 AI 编程应用大热,但运行卡顿、资源消耗惊人、推理成本过高等问题也随之而来。
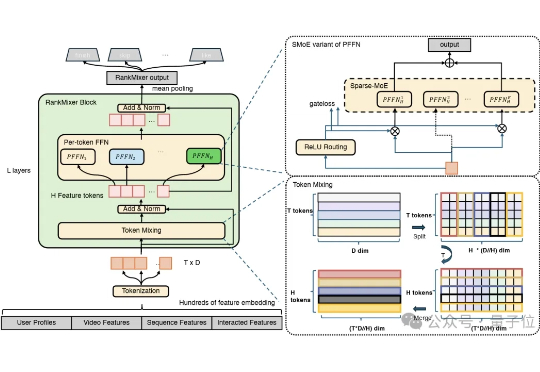
你刷的每一条短视频,背后都隐藏着推荐算法的迭代与革新。 作为最新成果,字节跳动的算法团队提出的全新推荐排序模型架构RankMixer,在兼顾算力利用率的同时,实现了模型效果的可扩展性。

LLM用得越久,速度越快!Emory大学提出SpeedupLLM框架,利用动态计算资源分配和记忆机制,使LLM在处理相似任务时推理成本降低56%,准确率提升,为AI模型发展提供新思路。
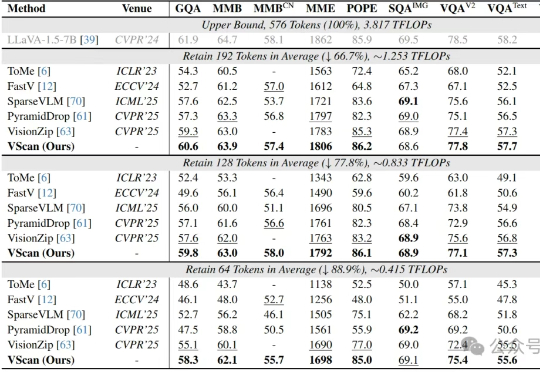
多图像、长视频、细粒度感知正在让大型视觉语言模型(LVLM)变得越来越聪明,但也越来越“吃不消”:视觉Token数量的激增所带来的推理成本暴涨,正逐渐成为多模态智能扩展的最大算力瓶颈。

只用5%的参数,数学和代码能力竟然超越满血DeepSeek?

大模型之战烽火正酣,谷歌Gemini 2.5 Pro却强势逆袭!Gemini Flash预训练负责人亲自揭秘,深挖Gemini预训练的关键技术,看谷歌如何在模型大小、算力、数据和推理成本间找到最优解。