提速4.48倍!哈工大华为新框架让扩散大模型精度无损、推理起飞
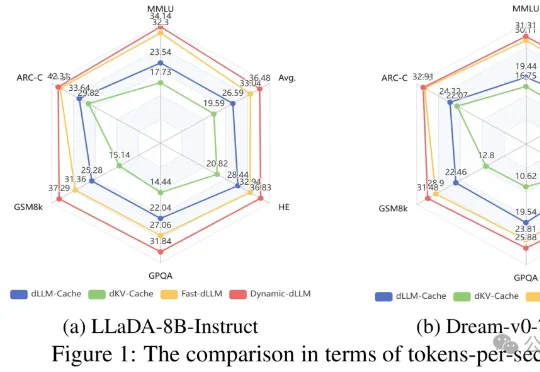
提速4.48倍!哈工大华为新框架让扩散大模型精度无损、推理起飞文本生成这件事,扩散大语言模型(dLLMs)正展现出巨大的潜力。但与此同时,它也面临着严重的计算瓶颈——为此,哈工大(深圳)与华为、深圳河套学院的研究团队提出了一套免训练加速框架Dynamic-dLLM。
来自主题: AI技术研报
8516 点击 2026-05-08 14:05
 搜索
搜索
文本生成这件事,扩散大语言模型(dLLMs)正展现出巨大的潜力。但与此同时,它也面临着严重的计算瓶颈——为此,哈工大(深圳)与华为、深圳河套学院的研究团队提出了一套免训练加速框架Dynamic-dLLM。
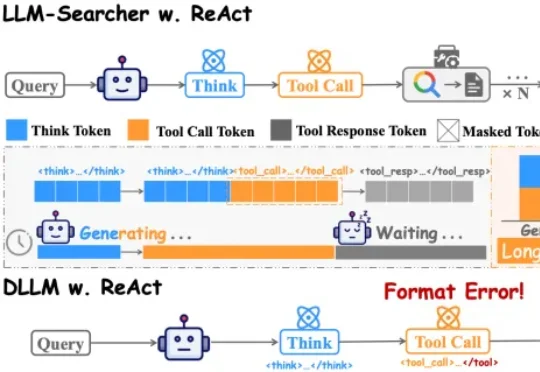
中国人民大学团队在论文DLLM-Searcher中,第一次让扩散大语言模型(dLLM)学会了这种“一心二用”的本事。目前主流的搜索Agent,不管是Search-R1还是R1Searcher,用的都是ReAct框架。这个框架的执行流程是严格串行的:
扩散大语言模型得到了突飞猛进的发展,早在 25 年 2 月 Inception Labs 推出 Mercury—— 第一个商业级扩散大型语言模型,同期人民大学发布第一个开源 8B 扩散大语言模型 LLaDA,5 月份 Gemini Diffusion 也接踵而至。
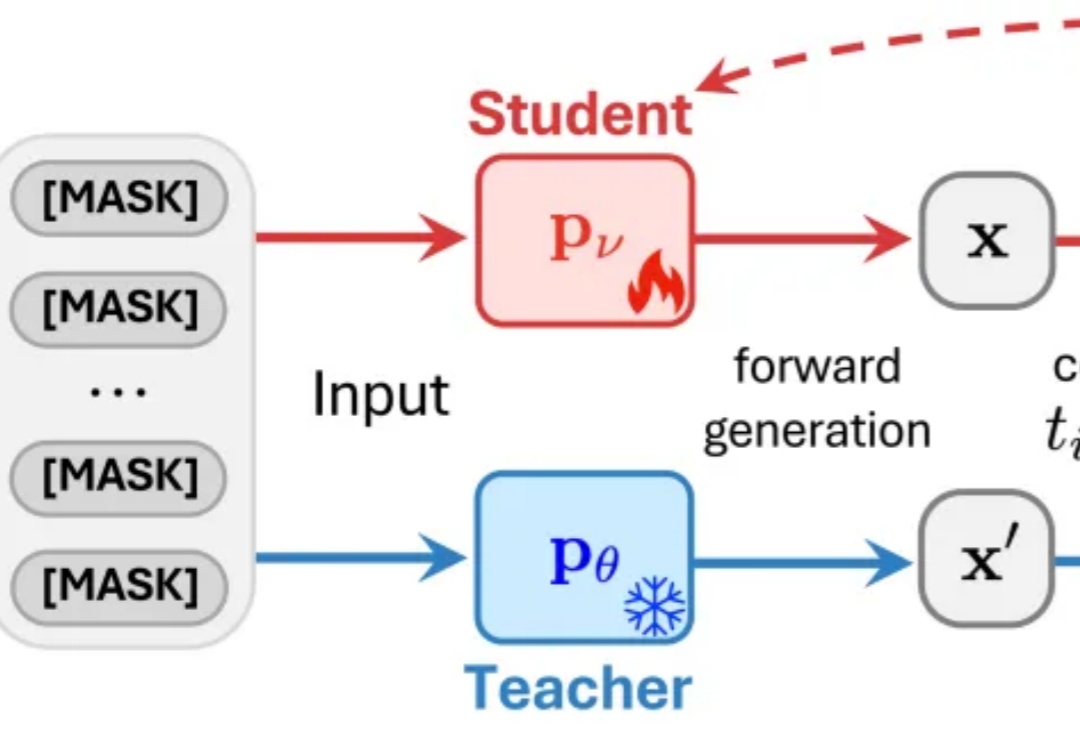
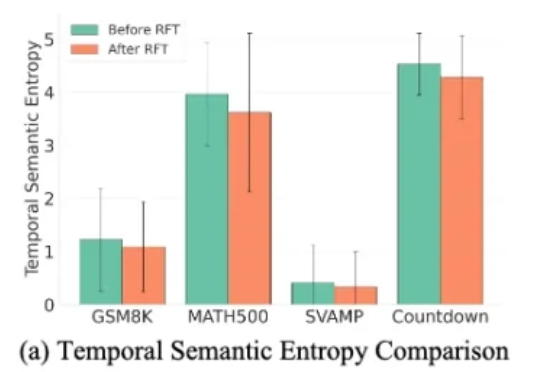
近日,来自普渡大学、德克萨斯大学、新加坡国立大学、摩根士丹利机器学习研究、小红书 hi-lab 的研究者联合提出了一种对离散扩散大语言模型的后训练方法 —— Discrete Diffusion Divergence Instruct (DiDi-Instruct)。经过 DiDi-Instruct 后训练的扩散大语言模型可以以 60 倍的加速超越传统的 GPT 模型和扩散大语言模型。
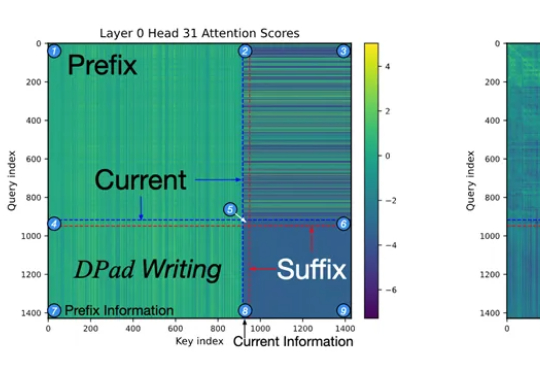
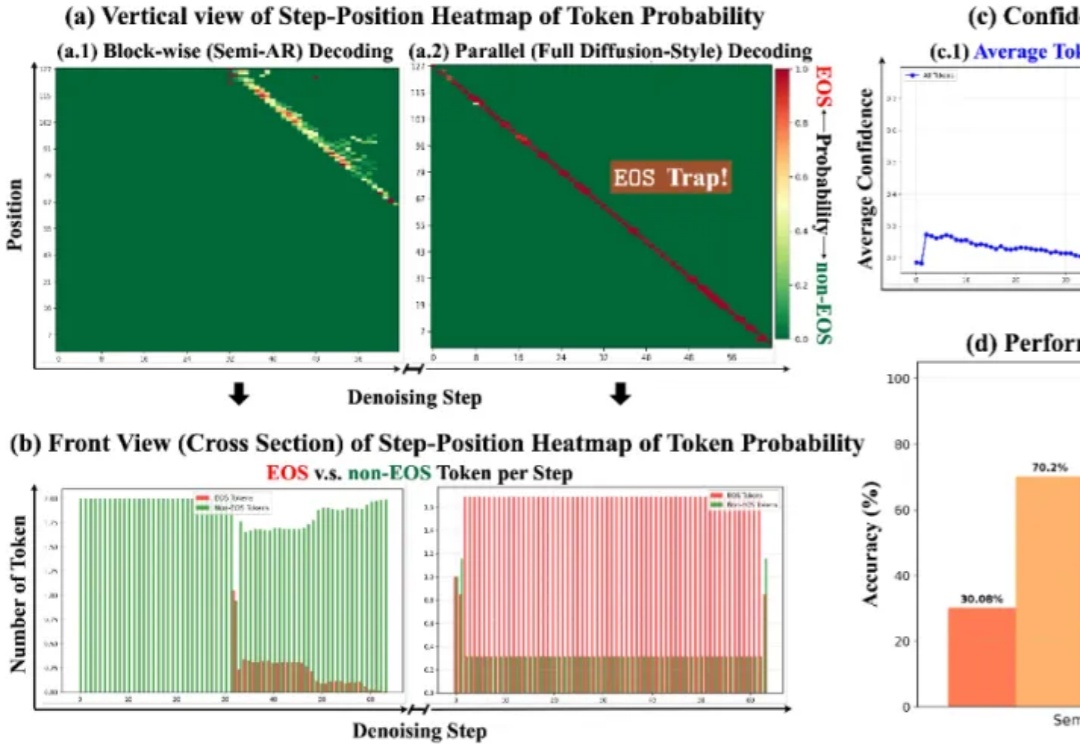
杜克大学团队发现,扩散大语言模型只需关注少量「中奖」token,就能在推理时把速度提升61-97倍,还能让模型更懂格式、更听话。新策略DPad不训练也能零成本挑出关键信息,实现「少算多准」的双赢。
近年来,扩散大语言模型(Diffusion Large Language Models, dLLMs)正迅速崭露头角,成为文本生成领域的一股新势力。与传统自回归(Autoregressive, AR)模型从左到右逐字生成不同,dLLM 依托迭代去噪的生成机制,不仅能够一次性生成多个 token,还能在对话、推理、创作等任务中展现出独特的优势。
在大语言模型(LLMs)领域,自回归(AR)范式长期占据主导地位,但其逐 token 生成也带来了固有的推理效率瓶颈。此前,谷歌的 Gemini Diffusion 和字节的 Seed Diffusion 以每秒千余 Tokens 的惊人吞吐量,向业界展现了扩散大语言模型(dLLMs)在推理速度上的巨大潜力。
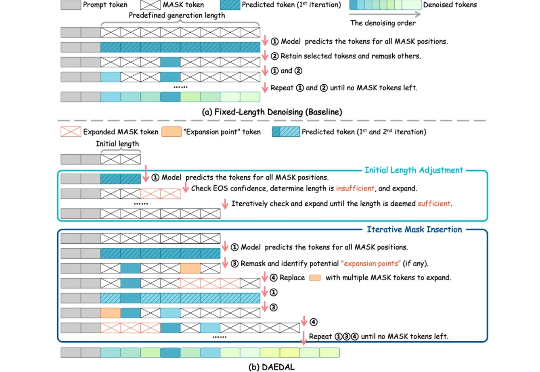
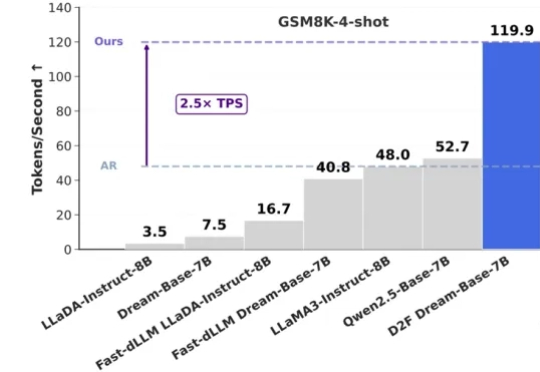
随着 Gemini-Diffusion,Seed-Diffusion 等扩散大语言模型(DLLM)的发布,这一领域成为了工业界和学术界的热门方向。但是,当前 DLLM 存在着在推理时必须采用预设固定长度的限制,对于不同任务都需要专门调整才能达到最优效果。
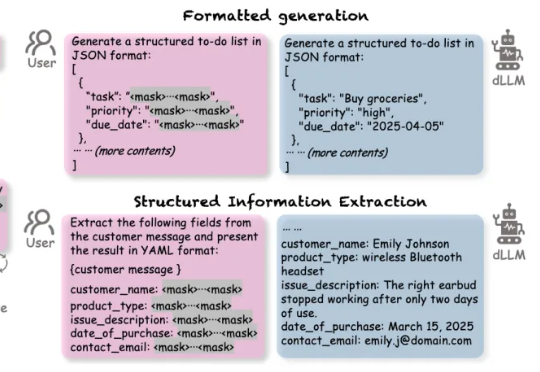
扩散语言模型(Diffusion-based LLMs,简称 dLLMs)以其并行解码、双向上下文建模、灵活插入masked token进行解码的特性,成为一个重要的发展方向。

近日,NVIDIA 联合香港大学、MIT 等机构重磅推出 Fast-dLLM,以无需训练的即插即用加速方案,实现了推理速度的突破!通过创新的技术组合,在不依赖重新训练模型的前提下,该工作为扩散模型的推理加速带来了突破性进展。本文将结合具体技术细节与实验数据,解析其核心优势。