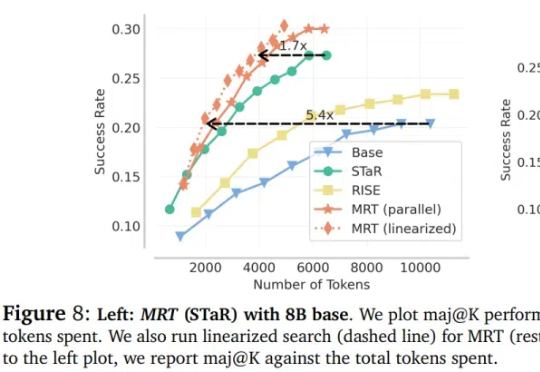
超越DeepSeek-R1关键RL算法GRPO,CMU「元强化微调」新范式登场
超越DeepSeek-R1关键RL算法GRPO,CMU「元强化微调」新范式登场大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。
来自主题: AI技术研报
8930 点击 2025-03-13 14:41
 搜索
搜索
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。
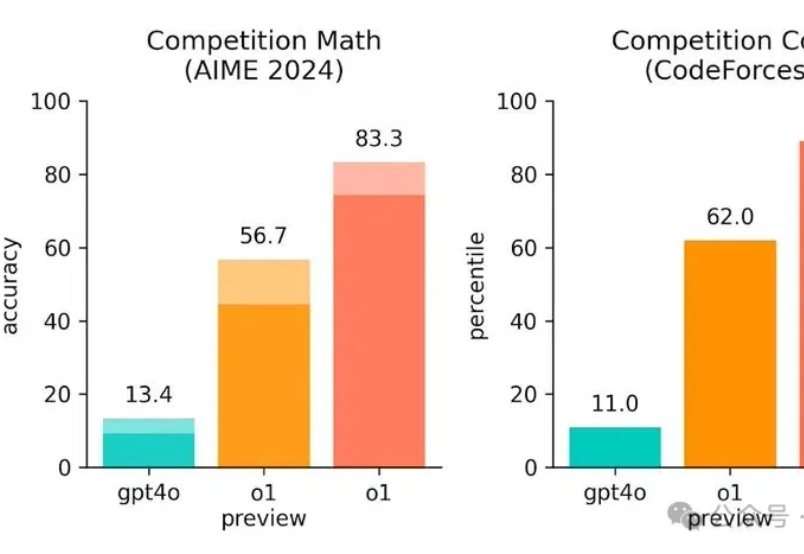
谷歌开发者暗示,我们直接进入ASI的可能性,正在逐月增加!Ilya早就看到了这一点,因为扩展测试时计算的成功,证明目前的路径能够到达ASI。与此同时,AI学会自我改进、取代人类研究员的未来似乎也愈发逼近,到时再拔网线来得及吗?
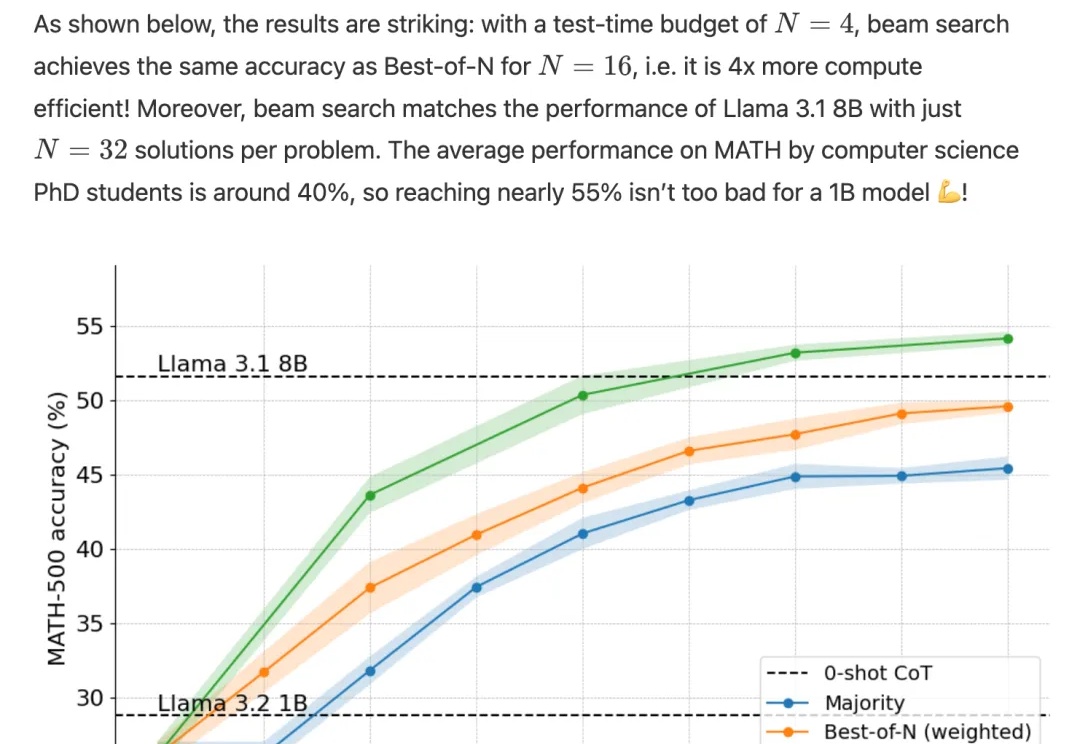
o1完整版公开仅10天,Scaling Law新范式就被逆向工程复现了!