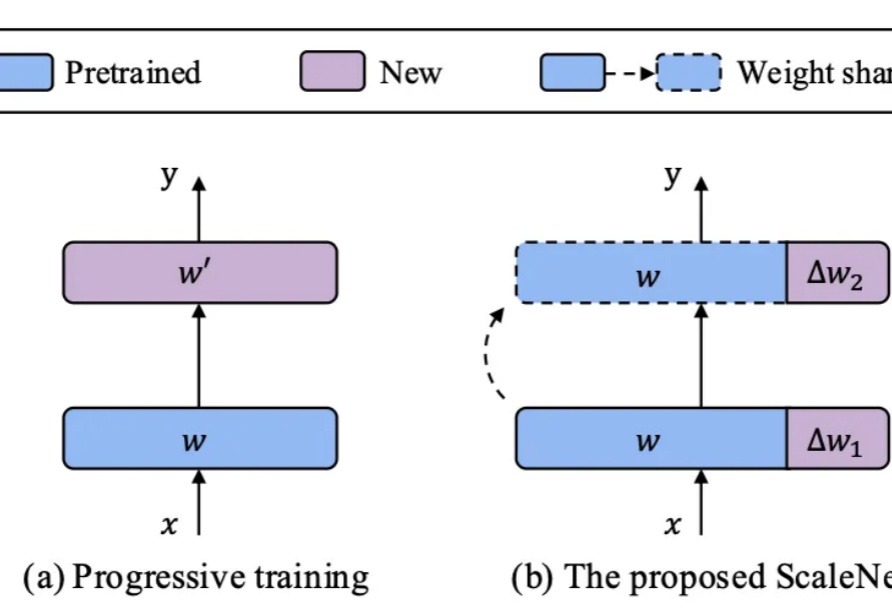
华为诺亚发布ScaleNet:模型放大通用新范式
华为诺亚发布ScaleNet:模型放大通用新范式在基础模型领域,模型规模与性能之间的缩放定律(Scaling Law)已被广泛验证,但模型增大也伴随着训练成本、存储需求和能耗的急剧上升。如何在控制参数量的前提下高效扩展模型,成为当前研究的关键挑战。
来自主题: AI技术研报
10413 点击 2025-11-19 09:31
 搜索
搜索
在基础模型领域,模型规模与性能之间的缩放定律(Scaling Law)已被广泛验证,但模型增大也伴随着训练成本、存储需求和能耗的急剧上升。如何在控制参数量的前提下高效扩展模型,成为当前研究的关键挑战。
目前,所有主流 LLM 都有一个固定的上下文窗口(如 200k, 1M tokens)。一旦输入超过这个限制,模型就无法处理。 即使在窗口内,当上下文变得非常长时,模型的性能也会急剧下降,这种现象被称为「上下文腐烂」(Context Rot):模型会「忘记」开头的信息,或者整体推理能力下降。
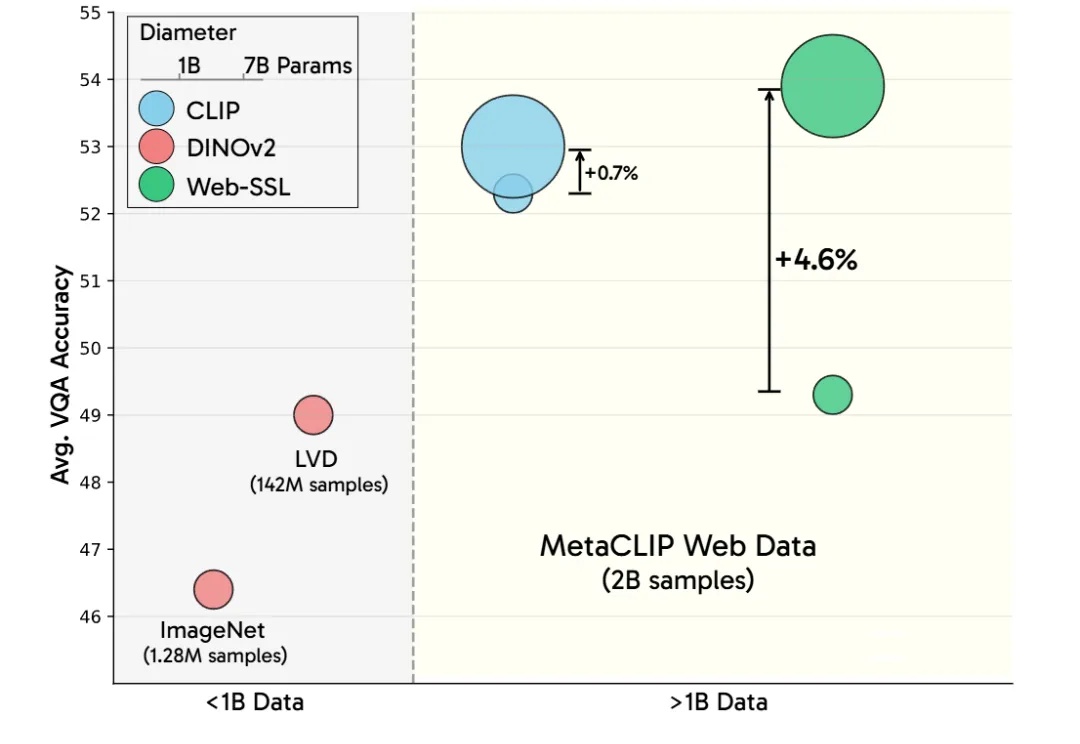
LeCun谢赛宁等研究人员通过新模型Web-SSL验证了SSL在多模态任务中的潜力,证明其在扩展模型和数据规模后,能媲美甚至超越CLIP。这项研究为无语言监督的视觉预训练开辟新方向,并计划开源模型以推动社区探索。

Stability AI推出3D重建方法:2D图像秒变3D,还可以交互式实时编辑。新方法的原理、代码、权重、数据全公开,而且许可证宽松,可以商用。新方法采用点扩展模型生成稀疏点云,之后通过Transformer主干网络,同时处理生成的点云数据和输入图像生成网格。以后,人人都能轻松上手3D模型设计。
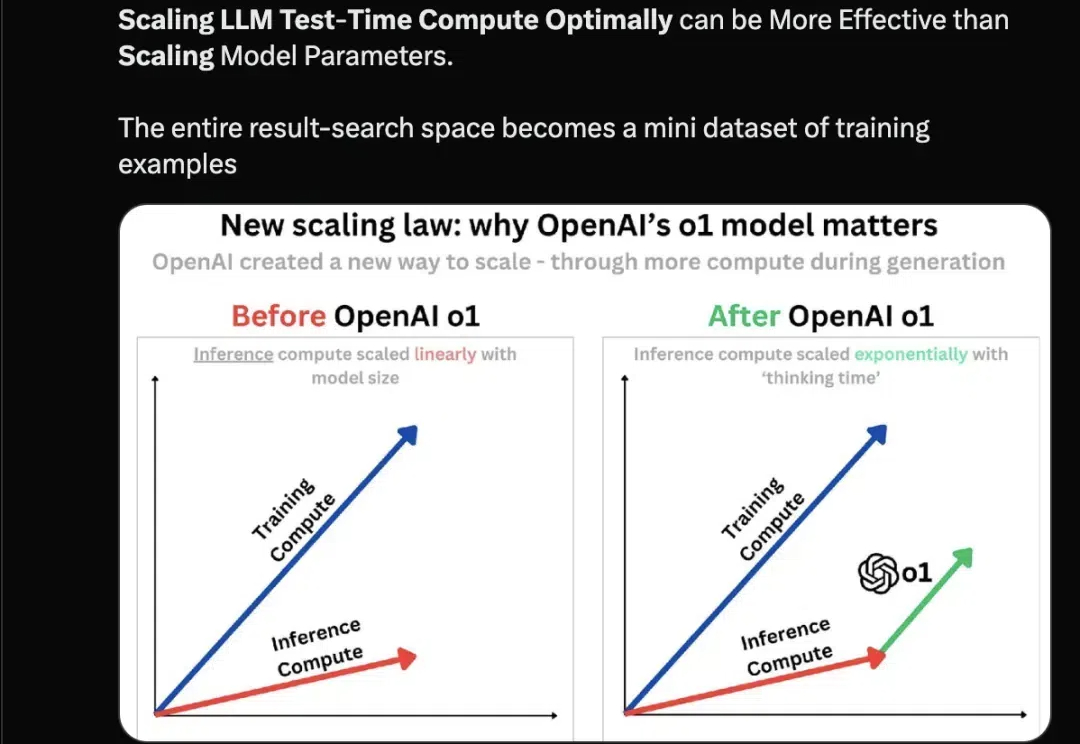
随着 o1、o1 Pro 和 o3 的成功发布,我们明显看到,推理所需的时间和计算资源逐步上升。可以说,o1 的最大贡献在于它揭示了提升模型效果的另一种途径:在推理过程中,通过优化计算资源的配置,可能比单纯扩展模型参数更为高效。
人工智能的能力会在未来几年内得到显著提升

对于大型视觉语言模型(LVLM)而言,扩展模型可以有效提高模型性能。然而,扩大参数规模会显著增加训练和推理成本,因为计算中每个 token 都会激活所有模型参数。