
一个8×8矩阵,让大模型「记住」长对话:Mind Lab联合NTU、复旦推出δ-mem,参数仅0.12%
一个8×8矩阵,让大模型「记住」长对话:Mind Lab联合NTU、复旦推出δ-mem,参数仅0.12%不扩上下文窗口、不换骨干架构、不做全参数微调 —— 只需要一个 8×8 的在线状态矩阵,就能让冻结的 Transformer 拥有真正的长期记忆。
来自主题: AI技术研报
10065 点击 2026-06-08 14:50
 搜索
搜索
不扩上下文窗口、不换骨干架构、不做全参数微调 —— 只需要一个 8×8 的在线状态矩阵,就能让冻结的 Transformer 拥有真正的长期记忆。
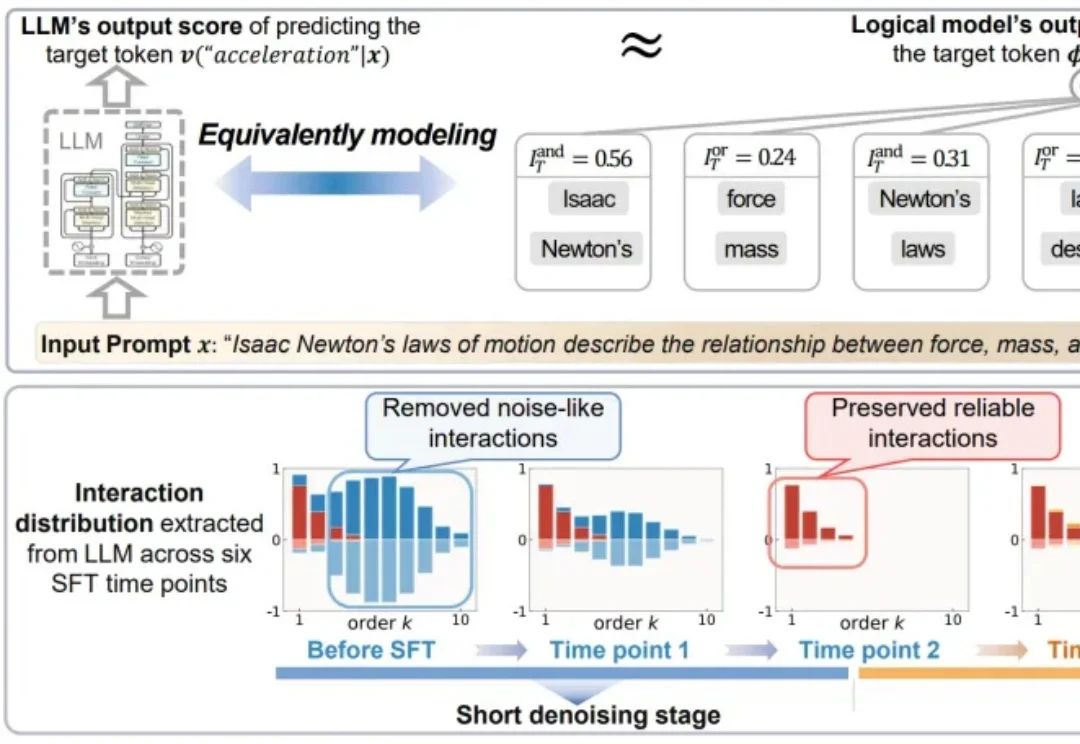
长期以来,监督微调(Supervised Fine-Tuning,SFT)一直是深度神经网络中最常用的模型适配手段。在中小规模的传统神经网络中,SFT 通常能够稳定提升下游任务表现。

最近,前沿实验室 Mind Lab 密集发布了一系列关于 LoRA 与 PEFT(高效微调)的研究结果,似乎描绘出了另一条大模型「持续学习」的路径。在 Mind Lab 的视角中,PEFT 不再是对大模型全参数后训练的一种廉价平替,更是实现从 “基础模型” 向 “可持续学习智能体” 过渡的核心架构机制。

过去十年,大模型世界里很多最关键的技术路线背后,都能看到Andrew Dai的身影。从早期预训练与监督微调,到后来主流的MoE(Mixture of Experts)架构;从Google Brain最初只有几十人的研究时代,到后来支撑Gemini的大规模数据体系,这位在 Google 工作超过14年的研究科学家,几乎站在了大模型时代每一次关键转折的现场。
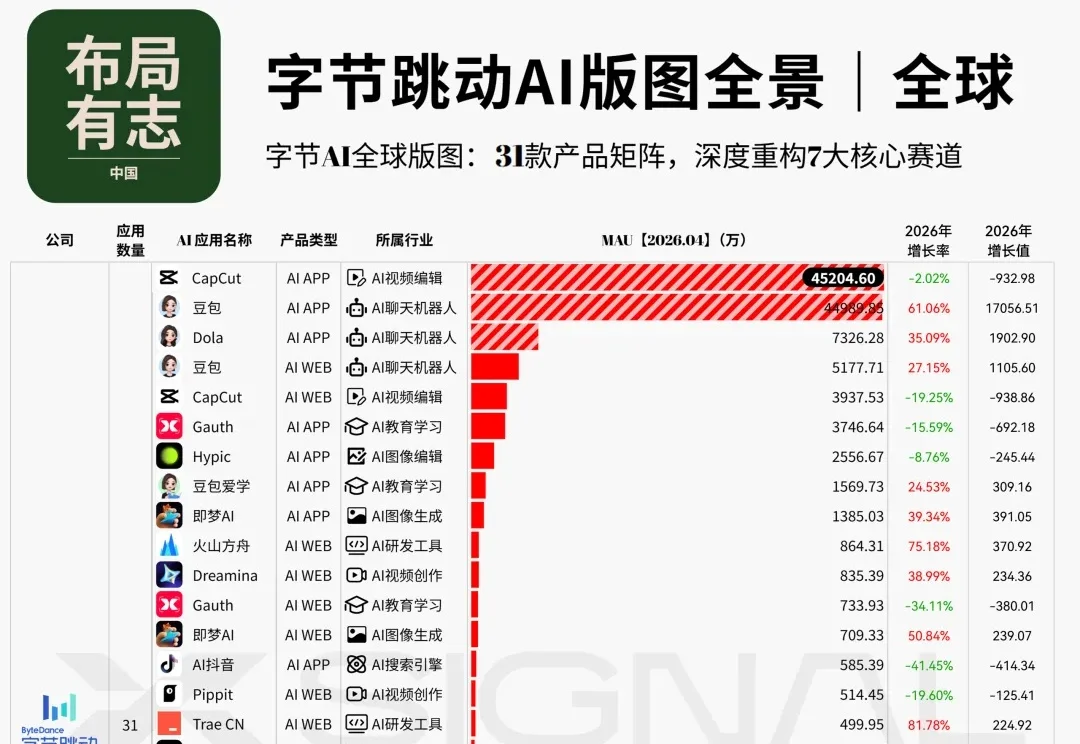
字节跳动计划在今年将其在人工智能基础设施上的支出大幅提升惊人的25%。这意味着将投入2000亿元人民币,这可不是一个边缘性的微调,是一次由不断升级的存储芯片成本以及字节跳动想要主导AI领域的雄心共同推动的巨大升级。
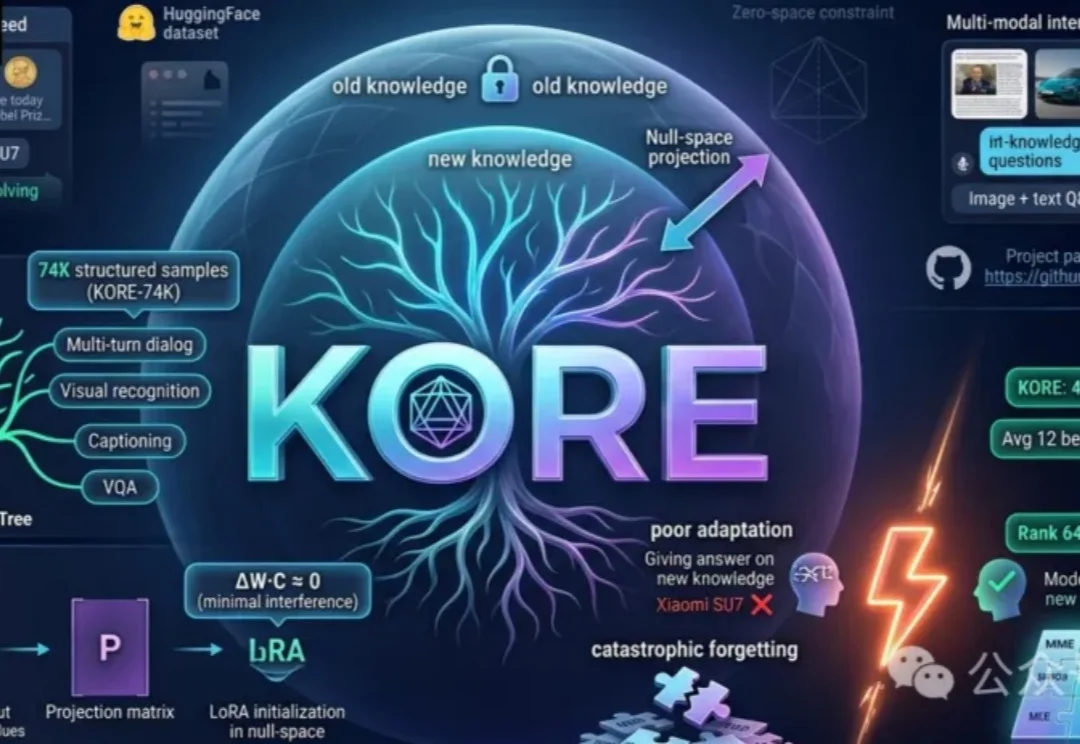
中科大团队首先推出动态多模态知识注入基准MMEVOKE,解构遗忘机制,并在此基础上提出全新双阶段框架KORE。通过「知识树」自动增强与「零空间」协方差约束微调,为大模型终身学习开辟了全新路径。
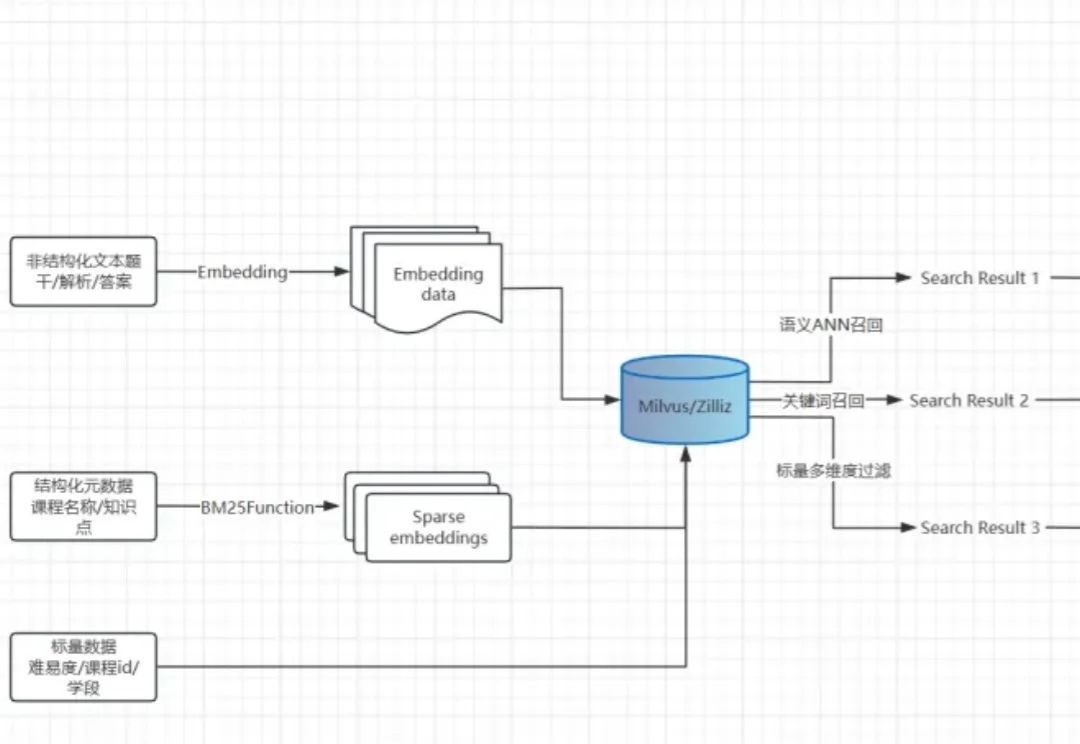
在教育科技领域,题库是核心资产,更是连接学生、教师与知识体系的关键入口。
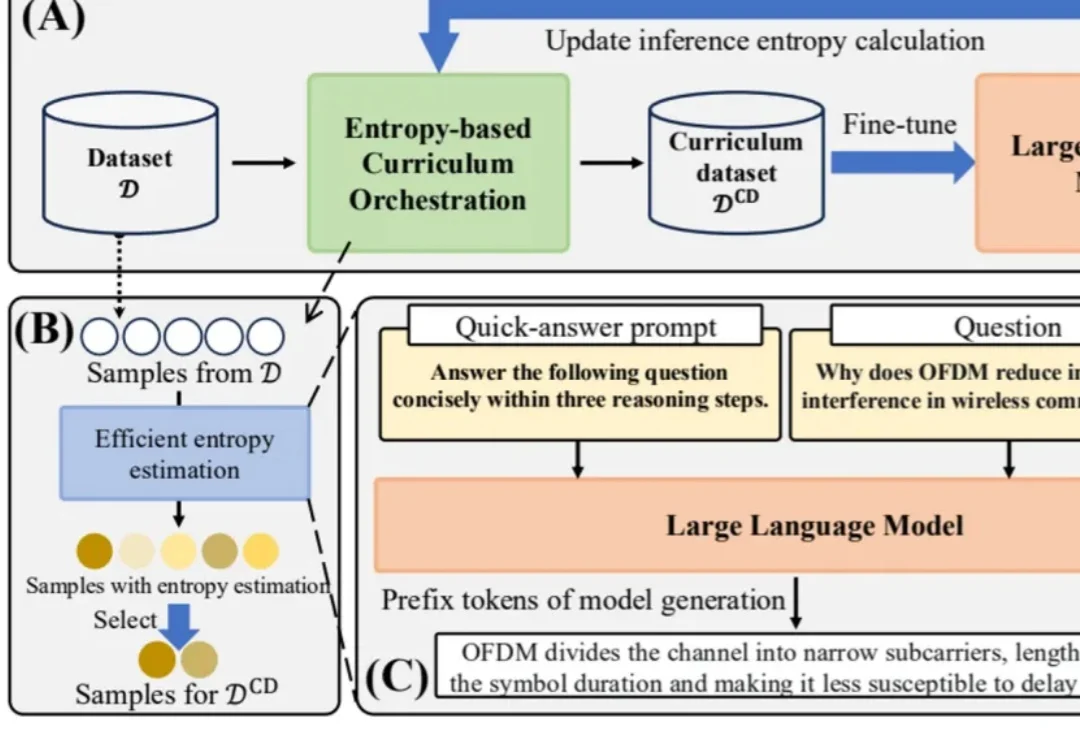
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。

有个31B参数的大模型,正常需要80GB显存才能跑。但现在,24GB显存就能跑满血版。这个版本叫Gemma-4-31B-JANG_4M-CRACK——"CRACK"这个词不要理解歪了,它本质是量化压缩加上对齐微调之后的部署版本,不是什么黑客攻击,就是工程优化。24GB,MacBook Pro,直接跑。苹果用户优先优化,MLX原生支持,月下载13000次。
近日,刚带着对标顶级闭源模型的强悍性能登场不久的 MiniMax M2.7 模型,悄悄变更了开源使用条款。尽管先前将权重公开在 Hugging Face,但当下已然收紧授权:商业用途需获得 MiniMax 书面授权。非商业用途依旧免费且不受限制,科研、个人项目、自用微调等场景均不受影响;但若是搭建托管服务或开发商业产品,则必须申请授权。