
强化学习教父重出江湖, 生成式AI的时代要结束了?
强化学习教父重出江湖, 生成式AI的时代要结束了?过去两年,AI靠模仿人类席卷世界。但强化学习之父Richard Sutton却说:「GenAI的时代正在结束。」他带着图灵奖的荣光,加入一家几乎没人听过的公司——ExperienceFlow.AI,他要让AI不靠人类数据喂养,而靠「经验」觉醒。
来自主题: AI资讯
9750 点击 2025-11-07 15:04
 搜索
搜索
过去两年,AI靠模仿人类席卷世界。但强化学习之父Richard Sutton却说:「GenAI的时代正在结束。」他带着图灵奖的荣光,加入一家几乎没人听过的公司——ExperienceFlow.AI,他要让AI不靠人类数据喂养,而靠「经验」觉醒。

当全世界都在狂热追逐大模型时,强化学习之父、图灵奖得主Richard Sutton却直言:大语言模型是「死胡同」。在他看来,真正的智能必须源于经验学习,而不是模仿人类语言的「预测游戏」。这番话无异于当头一棒,让人重新思考:我们追逐的所谓智能,究竟是幻影,还是通向未来的歧路?
强化学习之父、2024 年 ACM 图灵奖得主 Richard Sutton 曾指出,人工智能正在迈入「经验时代」—— 在这个时代,真正的智能不再仅仅依赖大量标注数据的监督学习,而是来源于在真实环境中主动探索、不断积累经验的能力。

不知道大家是否还记得,人工智能先驱、强化学习之父、图灵奖获得者 Richard S. Sutton,在一个多月前的演讲。 Sutton 认为,LLM 现在学习人类数据的知识已经接近极限,依靠「模仿人类」很难再有创新。

大模型目前的主导地位只是暂时的,在未来五年甚至十年内都不会是技术前沿。 这是新晋图灵奖得主、强化学习之父Richard Sutton对未来的最新预测。

本文对DeepMind两位泰斗级科学家David Silver和Richard Sutton的重磅论文《Welcome to the Era of Experience》进行了深度解读,我将其视为AI发展方向的一份战略瞭望图。

强化学习之父Richard Sutton和DeepMind强化学习副总裁David Silver对我们发出了当头棒喝:如今,人类已经由数据时代踏入经验时代。通往ASI之路要靠RL,而非人类数据!

强化学习先驱 Andrew Barto 与 Richard Sutton 获得今年的 ACM 图灵奖。
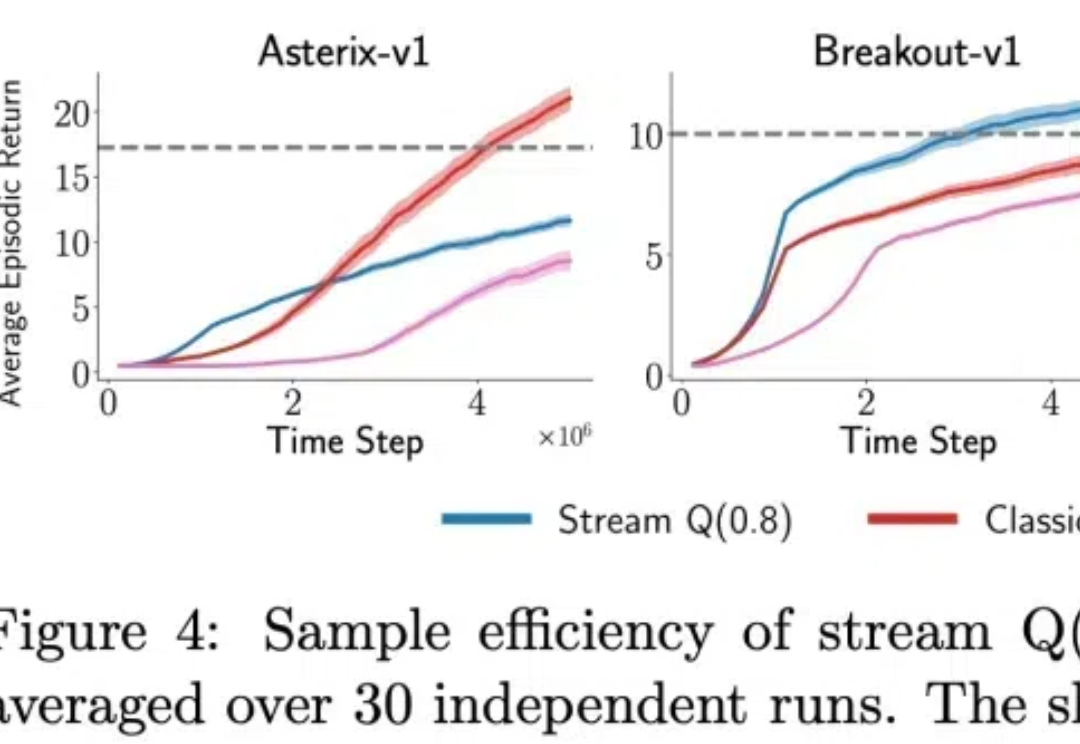
自然智能(Natural intelligence)过程就像一条连续的流,可以实时地感知、行动和学习。流式学习是 Q 学习和 TD 等经典强化学习 (RL) 算法的运作方式,它通过使用最新样本而不存储样本来模仿自然学习。这种方法也非常适合资源受限、通信受限和隐私敏感的应用程序。

在奖励中减去平均奖励