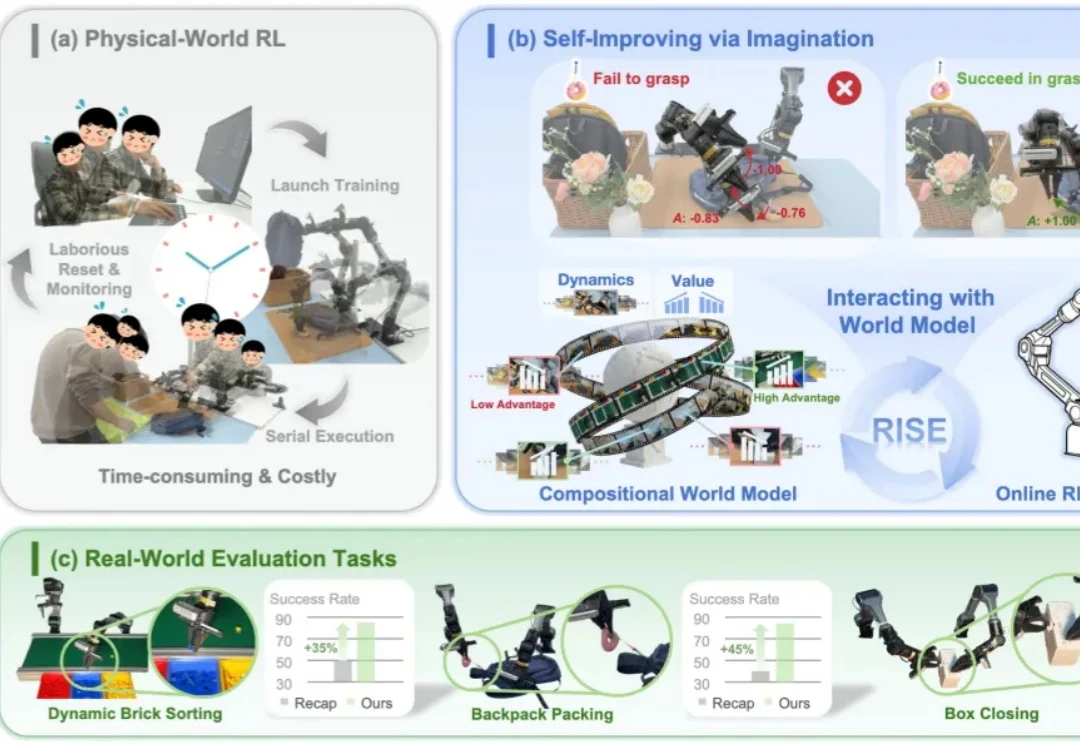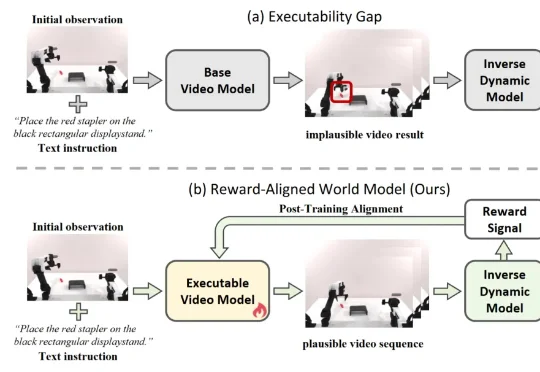
打破具身世界模型可执行性鸿沟 !港中深-跨维智能团队提出EVA框架,用强化学习让视频世界模型真正“动”起来
打破具身世界模型可执行性鸿沟 !港中深-跨维智能团队提出EVA框架,用强化学习让视频世界模型真正“动”起来近期,利用视频生成模型为机器人构建 “世界模型”,已成为具身智能领域的热门技术路线。给定当前观测和自然语言指令,这类模型能够先 “想象” 出未来的视觉轨迹,再由逆动力学模型(IDM)将生成画面解码为机器人动作,从而形成 “先预测、后执行” 的解耦式规划范式。由于兼具较强的可解释性与开放场景泛化潜力,这一路线正在受到学术界和工业界的广泛关注。
来自主题: AI技术研报
8963 点击 2026-03-28 09:50