
李飞飞/DeepSeek前员工领衔,复现R1强化学习框架,训练Agent在行动中深度思考
李飞飞/DeepSeek前员工领衔,复现R1强化学习框架,训练Agent在行动中深度思考什么开源算法自称为DeepSeek-R1(-Zero) 框架的第一个复现?
来自主题: AI技术研报
9379 点击 2025-04-25 15:35
 搜索
搜索
什么开源算法自称为DeepSeek-R1(-Zero) 框架的第一个复现?

谷歌DeepMind与HHMI Janelia研究所的科学家们,用AI打造了一个栩栩如生的虚拟果蝇模型。这个模型不仅能精准模拟果蝇的飞行与行走,还通过深度强化学习模仿真实果蝇的行为。
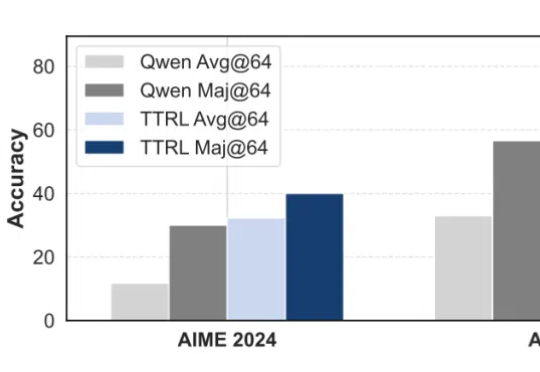
无需数据标注,在测试时做强化学习,模型数学能力暴增159%!

Adam优化器是深度学习中常用的优化算法,但其性能背后的理论解释一直不完善。近日,来自清华大学的团队提出了RAD优化器,扩展了Adam的理论基础,提升了训练稳定性。实验显示RAD在多种强化学习任务中表现优于Adam。
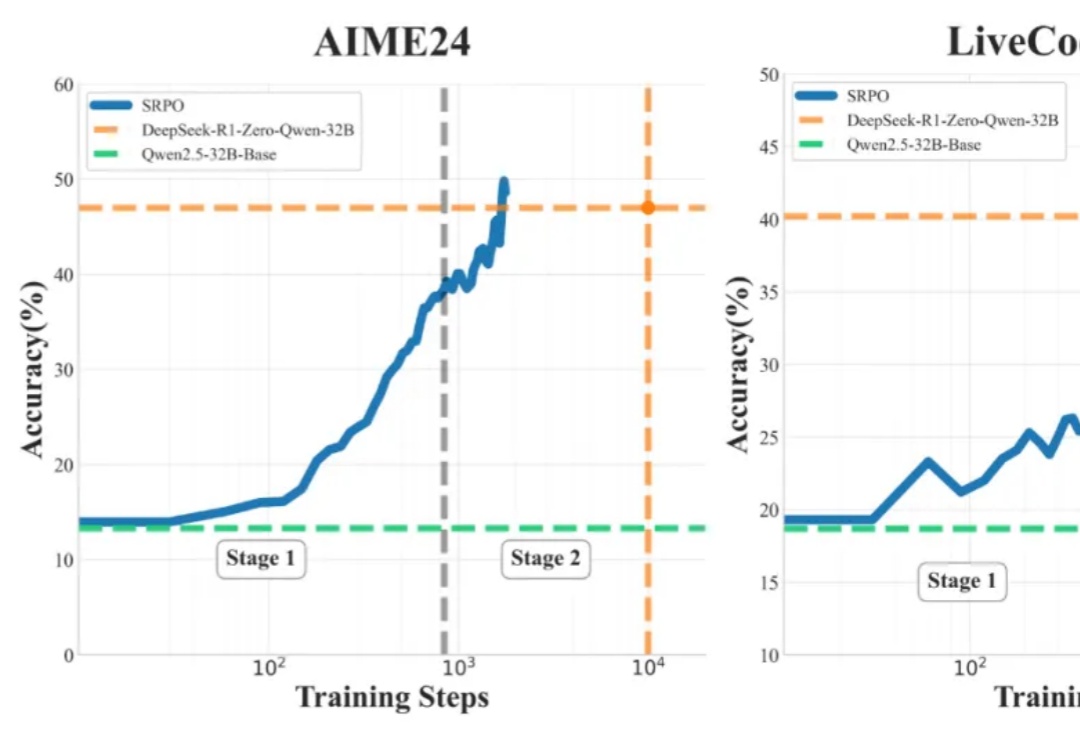
OpenAI 的 o1 系列和 DeepSeek-R1 的成功充分证明,大规模强化学习已成为一种极为有效的方法,能够激发大型语言模型(LLM) 的复杂推理行为并显著提升其能力。
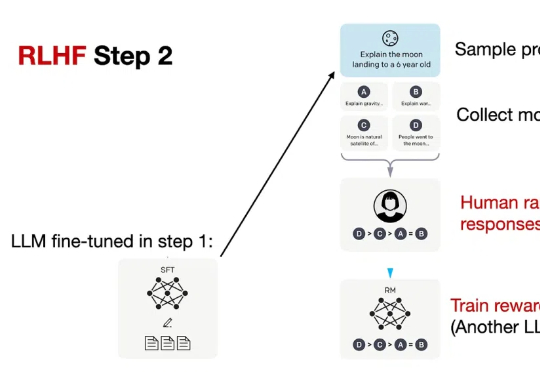
只靠模型尺寸变大已经不行了?大语言模型(LLM)推理需要强化学习(RL)来「加 buff」。

AI的野心从未如此大胆!新创公司Mechanize目标直指「全面自动化所有工作」和「经济无人化」,瞄准全球60万亿美元的劳动力市场。从虚拟工作环境到强化学习,Mechanize计划用AI智能体取代人类岗位,引发巨大争议。

DeepSeek-R1 展示了强化学习在提升模型推理能力方面的巨大潜力,尤其是在无需人工标注推理过程的设定下,模型可以学习到如何更合理地组织回答。然而,这类模型缺乏对外部数据源的实时访问能力,一旦训练语料中不存在某些关键信息,推理过程往往会因知识缺失而失败。

本文对DeepMind两位泰斗级科学家David Silver和Richard Sutton的重磅论文《Welcome to the Era of Experience》进行了深度解读,我将其视为AI发展方向的一份战略瞭望图。

当前,强化学习(RL)方法在最近模型的推理任务上取得了显著的改进,比如 DeepSeek-R1、Kimi K1.5,显示了将 RL 直接用于基础模型可以取得媲美 OpenAI o1 的性能不过,基于 RL 的后训练进展主要受限于自回归的大语言模型(LLM),它们通过从左到右的序列推理来运行。