
用多模态LLM超越YOLOv3!强化学习突破多模态感知极限|开源
用多模态LLM超越YOLOv3!强化学习突破多模态感知极限|开源超越YOLOv3、Faster-RCNN,首个在COCO2017 val set上突破30AP的纯多模态开源LLM来啦!
来自主题: AI技术研报
9024 点击 2025-05-03 15:24
 搜索
搜索
超越YOLOv3、Faster-RCNN,首个在COCO2017 val set上突破30AP的纯多模态开源LLM来啦!
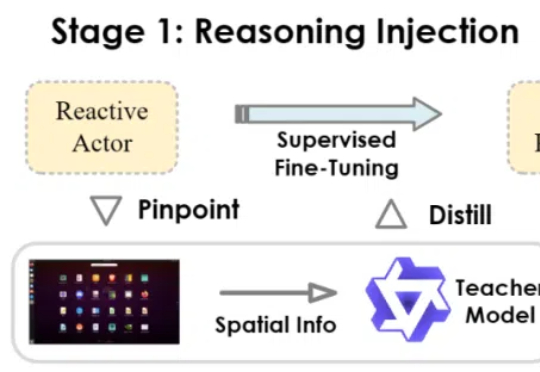
当前,多模态大模型驱动的图形用户界面(GUI)智能体在自动化手机、电脑操作方面展现出巨大潜力。然而,一些现有智能体更类似于「反应式行动者」(Reactive Actors),主要依赖隐式推理,面对需要复杂规划和错误恢复的任务时常常力不从心。

南加州大学团队只用9美元,就能在数学基准测试AIME 24上实现超过20%的推理性能提升,效果好得离谱!而其核心技术只需LoRA+强化学习,用极简路径实现超高性价比后训练。

现如今,微调和强化学习等后训练技术已经成为提升 LLM 能力的重要关键。

就在刚刚,DeepSeek-Prover-V2技术报告也来了!34页论文揭秘了模型的训练核心——递归+强化学习,让数学推理大提升。有人盛赞:DeepSeek已找到通往AGI的正确路径!

AI能像人类一样不断从经验中学习、进化,而不仅仅依赖于人工标注的数据?测试时强化学习(TTRL)与记忆系统的结合正在开启这一全新可能!
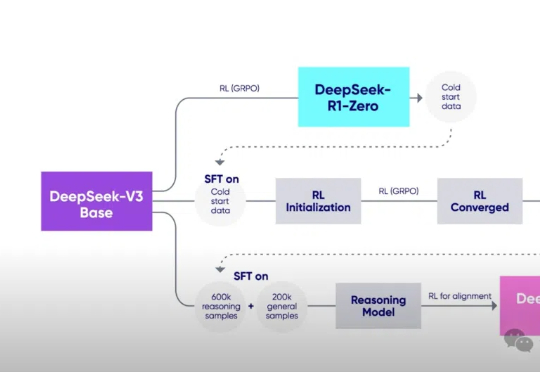
一项来自清华大学和上海交通大学的研究颠覆了对可验证奖励强化学习(RLVR)的认知。RLVR被认为是打造自我进化大模型的关键,但实验表明,它可能只是提高了采样效率,而非真正赋予模型全新推理能力。
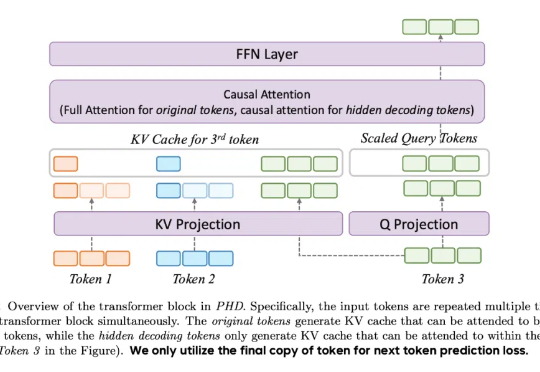
最近,DeepSeek-R1 和 OpenAI o1/03 等推理大模型在后训练阶段探索了长度扩展(length scaling),通过强化学习(比如 PPO、GPRO)训练模型生成很长的推理链(CoT),并在奥数等高难度推理任务上取得了显著的效果提升。
全球首个去中心化强化学习训练的32B模型——INTELLECT-2震撼发布!无需授权,就能用自家异构计算资源参与其中,让编码、数学与科学领域的推理性能迈向新高度。

本文提出 LUFFY 强化学习方法,一种结合离线专家示范与在线强化学习的推理训练范式,打破了“模仿学习只学不练、强化学习只练不学”的传统壁垒。LUFFY 通过将高质量专家示范制定为一种离策略指引,并引入混合策略优化与策略塑形机制,稳定地实现了在保持探索能力的同时高效吸收强者经验。