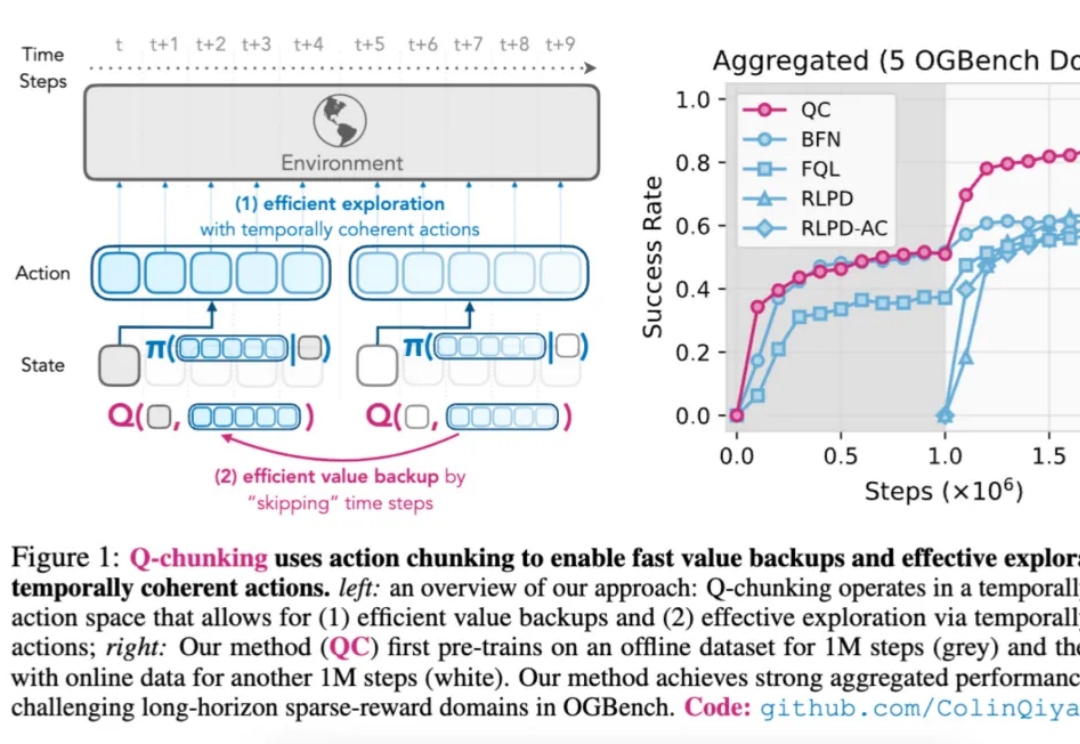
用动作分块突破RL极限,伯克利引入模仿学习,超越离线/在线SOTA
用动作分块突破RL极限,伯克利引入模仿学习,超越离线/在线SOTA如今,强化学习(Reinforcement Learning,RL)在多个领域已取得显著成果。
来自主题: AI技术研报
7384 点击 2025-07-14 15:16
 搜索
搜索
如今,强化学习(Reinforcement Learning,RL)在多个领域已取得显著成果。
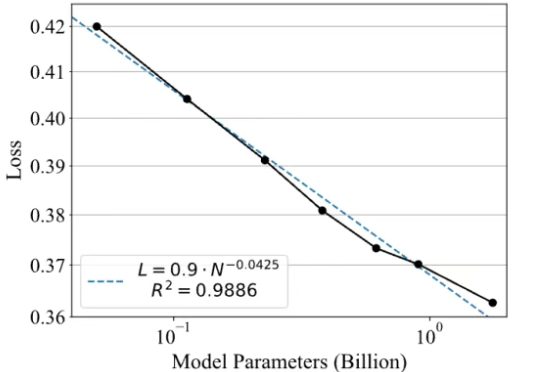
强化学习改变了大语言模型的后训练范式,可以说,已成为AI迈向AGI进程中的关键技术节点。然而,其中奖励模型的设计与训练,始终是制约后训练效果、模型能力进一步提升的瓶颈所在。

让大模型在学习推理的同时学会感知。伊利诺伊大学香槟分校(UIUC)与阿里巴巴通义实验室联合推出了全新的专注于多模态推理的强化学习算法PAPO(Perception-Aware Policy Optimization)。

2025上半年AI Agent领域经历模型竞争加剧和范式演进,DeepSeek等新模型打破垄断,推动Tool Use和强化学习突破。Agent从Prompt、Workflow发展为自主决策、环境感知和工具使用的智能体。编程领域验证PMF,落地机会集中于垂直场景和C端创新,但商业壁垒和技术挑战仍待解决。
香港大学NLP团队联合字节跳动Seed、复旦大学发布名为Polaris的强化学习训练配方:通过Scaling RL,Polaris让4B模型的数学推理能力(AIME25上取得79.4,AIME24上取得81.2)超越了一众商业大模型,如Seed-1.5-thinking、Claude-4-Opus和o3-mini-high(25/01/31)。

在多模态大语言模型(MLLMs)应用日益多元化的今天,对模型深度理解和分析人类意图的需求愈发迫切。尽管强化学习(RL)在增强大语言模型(LLMs)的推理能力方面已展现出巨大潜力,但将其有效应用于复杂的多模态数据和格式仍面临诸多挑战。
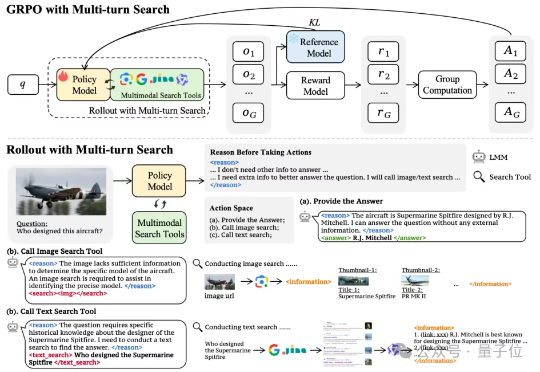
多模态模型学会“按需搜索”!字节&NTU最新研究,优化多模态模型搜索策略——通过搭建网络搜索工具、构建多模态搜索数据集以及涉及简单有效的奖励机制,首次尝试基于端到端强化学习的多模态模型自主搜索训练。

新晋AI编程冠军DeepSWE来了!仅通过纯强化学习拿下基准测试59%的准确率,凭啥?7大算法细节首次全公开。

近年来,基于智能体的强化学习(Agent + RL)与智能体优化(Agent Optimization)在学术界引发了广泛关注。然而,实现具备工具调用能力的端到端智能体训练,首要瓶颈在于高质量任务数据的极度稀缺。
大语言模型(LLM)以生成能力强而著称,但如何能让它「听话」,是一门很深的学问。 基于人类反馈的强化学习(RLHF)就是用来解决这个问题的,其中的奖励模型 (Reward Model, RM)扮演着重要的裁判作用,它专门负责给 LLM 生成的内容打分,告诉模型什么是好,什么是不好,可以保证大模型的「三观」正确。