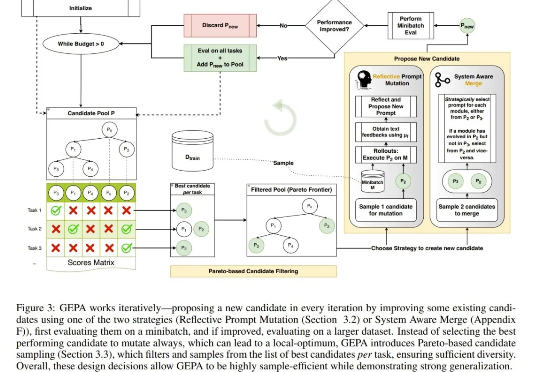
当提示词优化器学会进化,竟能胜过强化学习
当提示词优化器学会进化,竟能胜过强化学习仅靠提示词优化就能超越 DeepSeek 开发的 GRPO 强化学习算法? 是的,你没有看错。近日上线 arXiv 的一篇论文正是凭此吸引了无数眼球。
来自主题: AI技术研报
8282 点击 2025-08-01 11:42
 搜索
搜索
仅靠提示词优化就能超越 DeepSeek 开发的 GRPO 强化学习算法? 是的,你没有看错。近日上线 arXiv 的一篇论文正是凭此吸引了无数眼球。
近年来,OpenAI o1 和 DeepSeek-R1 等模型的成功证明了强化学习能够显著提升语言模型的推理能力。通过基于结果的奖励机制,强化学习使模型能够发展出可泛化的推理策略,在复杂问题上取得了监督微调难以企及的进展。
还在为强化学习(RL)框架的扩展性瓶颈和效率低下而烦恼吗?

陈建宇(星动纪元创始人)、高阳(千寻智能联合创始人)、吴翼(蚂蚁集团强化学习实验室首席科学家)、许华哲(星海图联合创始人)的分享(题图从左至右),基本代表了国内具身智能领域最先进的成果展示。
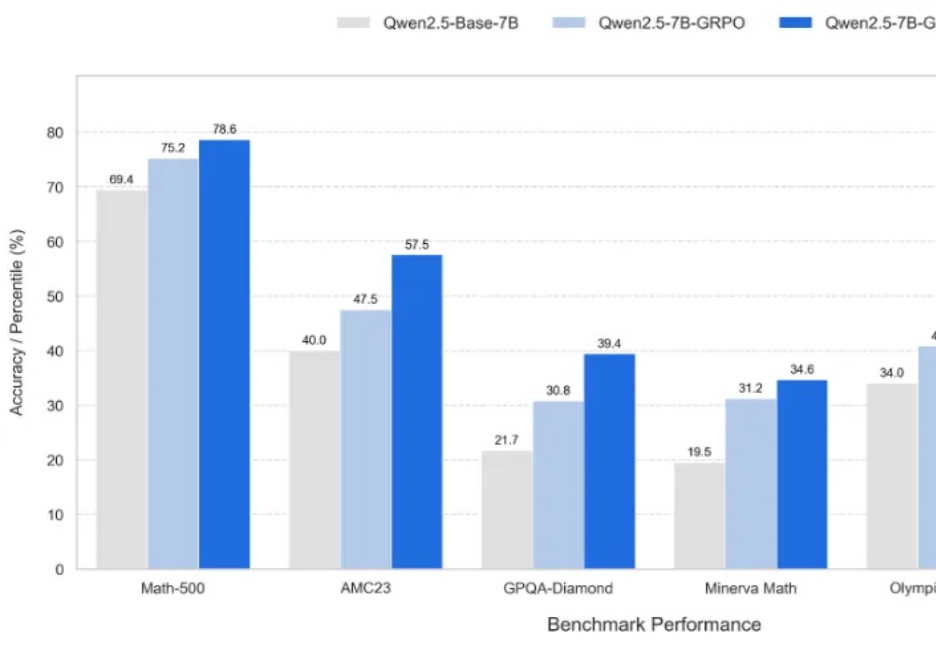
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。

在正式走近ChatGPT Agent之前,让我们介绍一下这次谈话的几位主角,他们分别是OpenAI团队核心成员Isa Fulford、Casey Chu和孙之清。我们团队分别开发了Operator和Deep Research,在分析用户请求时发现,Deep Research的用户非常希望模型能够访问需要付费订阅的内容或有门槛的资源,而Operator恰好具备这种能力。
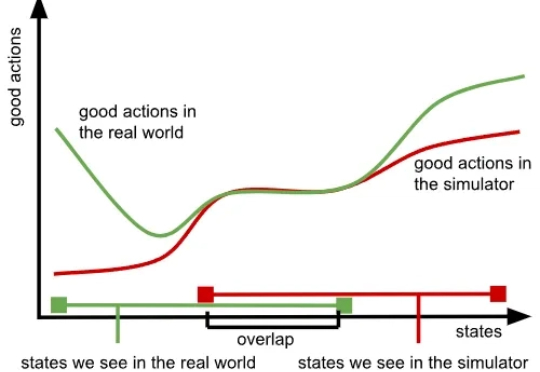
我们知道,训练大模型本就极具挑战,而随着模型规模的扩大与应用领域的拓展,难度也在不断增加,所需的数据更是海量。大型语言模型(LLM)主要依赖大量文本数据,视觉语言模型(VLM)则需要同时包含文本与图像的数据,而在机器人领域,视觉 - 语言 - 行动模型(VLA)则要求大量真实世界中机器人执行任务的数据。
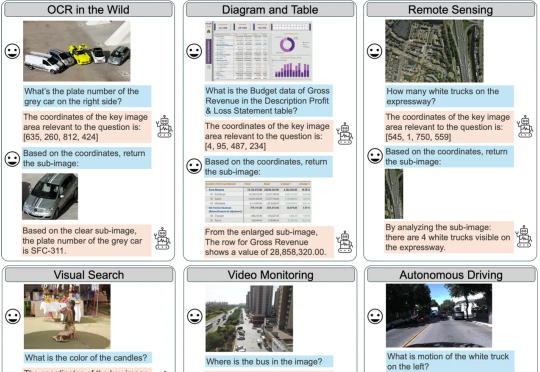
本文的主要作者来自复旦大学和南洋理工大学 S-Lab,研究方向聚焦于视觉推理与强化学习优化。

实时强化学习来了!AI 再也不怕「卡顿」。 设想这样一个未来场景:多个厨师机器人正在协作制作煎蛋卷。
从 ChatGPT 引发的通用聊天机器人热潮,到如今正迅猛发展的智能体模型,AI 正在经历一次深刻的范式转变:从被动响应的「语言模型」,走向具备自主决策能力的「智能体」。我们也正在进入所谓的「经验时代」或「软件 3.0 时代」。