陈丹琦新作:大模型强化学习的第三条路,8B小模型超越GPT-4o
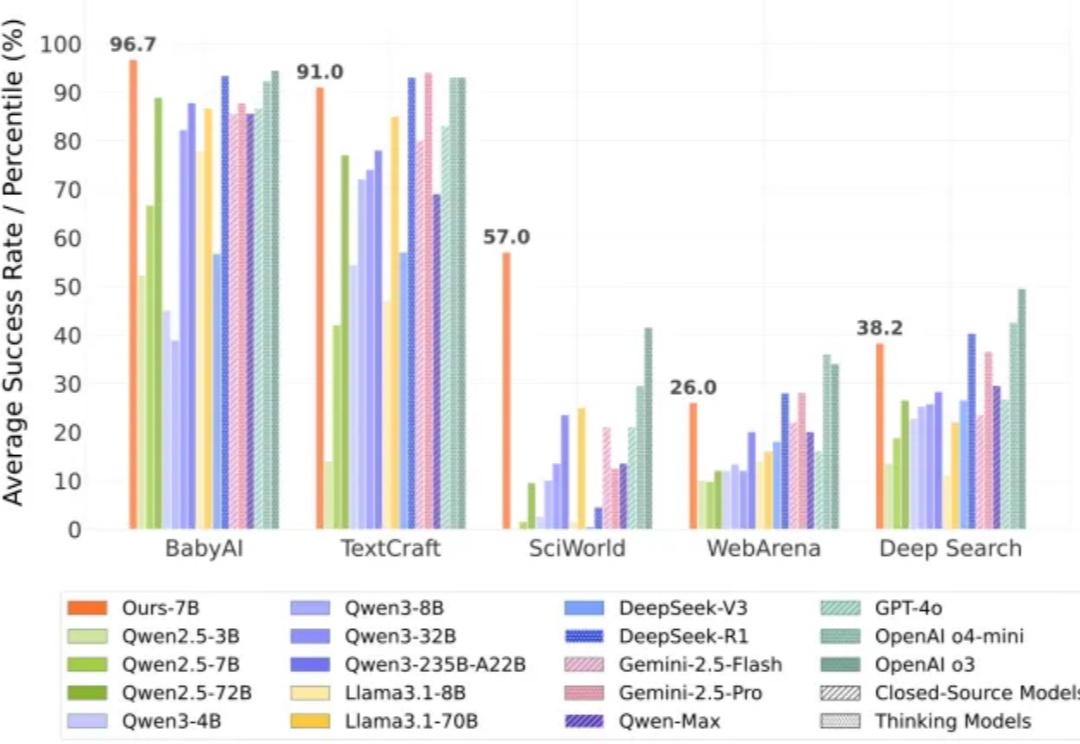
陈丹琦新作:大模型强化学习的第三条路,8B小模型超越GPT-4o结合RLHF+RLVR,8B小模型就能超越GPT-4o、媲美Claude-3.7-Sonnet。陈丹琦新作来了。他们提出了一个结合RLHF和RLVR优点的方法,RLMT(Reinforcement Learning with Model-rewarded Thinking,基于模型奖励思维的强化学习)。
来自主题: AI技术研报
10622 点击 2025-09-28 23:03