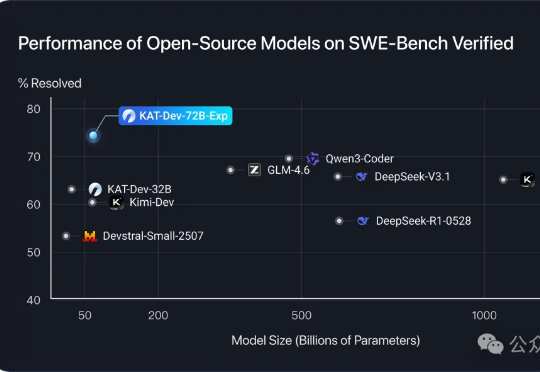
开源编程模型王座易主了,谁能想到新SOTA是快手
开源编程模型王座易主了,谁能想到新SOTA是快手开源编程模型王座,再度易主!来自快手的KAT-Dev-72B-Exp,在SWE-Bench认证榜单以74.6%的成绩夺得开源模型第一。KAT-Dev-72B-Exp是KAT-Coder模型的实验性强化学习版本。
来自主题: AI资讯
12345 点击 2025-10-11 15:57
 搜索
搜索
开源编程模型王座,再度易主!来自快手的KAT-Dev-72B-Exp,在SWE-Bench认证榜单以74.6%的成绩夺得开源模型第一。KAT-Dev-72B-Exp是KAT-Coder模型的实验性强化学习版本。
AI Agent已逐渐从科幻走进现实!不仅能够执行编写代码、调用工具、进行多轮对话等复杂任务,甚至还可以进行端到端的软件开发,已经在金融、游戏、软件开发等诸多领域落地应用。

昨天,阿里通义千问大语言模型负责人林俊旸在社交媒体上官宣,他们在 Qwen 内部组建了一个小型机器人、具身智能团队,同时表示「多模态基础模型正转变为基础智能体,这些智能体可以利用工具和记忆通过强化学习进行长程推理,它们绝对应该从虚拟世界走向物理世界」。
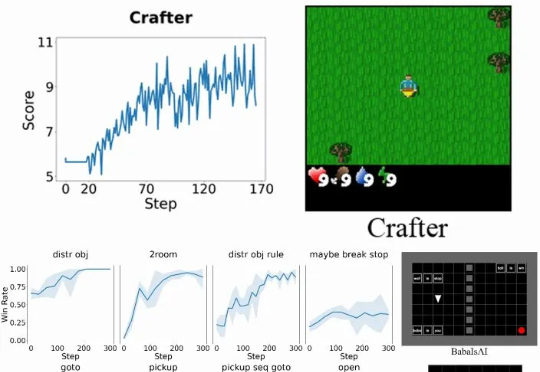
具体而言,Verlog 是一个多轮强化学习框架,专为具有高度可变回合(episode)长度的长时程(long-horizon) LLM-Agent 任务而设计。它在继承 VeRL 和 BALROG 的基础上,并遵循 pytorch-a2c-ppo-acktr-gail 的成熟设计原则,引入了一系列专门优化手段,从而在任务跨度从短暂交互到数百回合时,依然能够实现稳定而高效的训练。
来自 UIUC 与 Salesforce 的研究团队提出了一套系统化方案:UserBench —— 首次将 “用户特性” 制度化,构建交互评测环境,用于专门检验大模型是否真正 “懂人”;UserRL —— 在 UserBench 及其他标准化 Gym 环境之上,搭建统一的用户交互强化学习框架,并系统探索以用户为驱动的奖励建模。
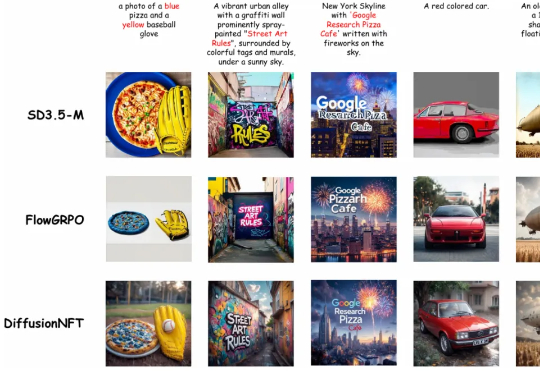
清华大学朱军教授团队,NVIDIA Deep Imagination 研究组与斯坦福 Stefano Ermon 团队联合提出了一种全新的扩散模型强化学习(RL)范式 ——Diffusion Negative-aware FineTuning (DiffusionNFT)。该方法首次突破现有 RL 对扩散模型的基本假设,直接在前向加噪过程(forward process)上进行优化
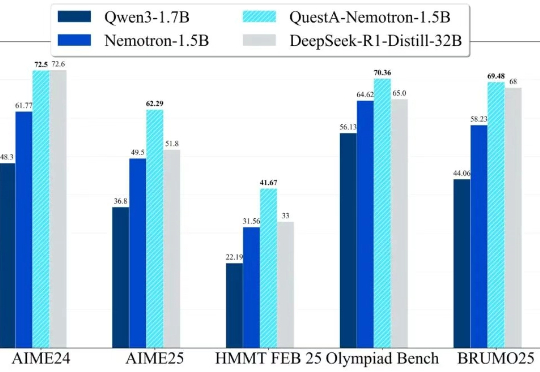
QuestA(问题增强)引入了一种方法,用于提升强化学习中的推理能力。通过在训练过程中注入部分解题提示,QuestA 实现两项重大成果
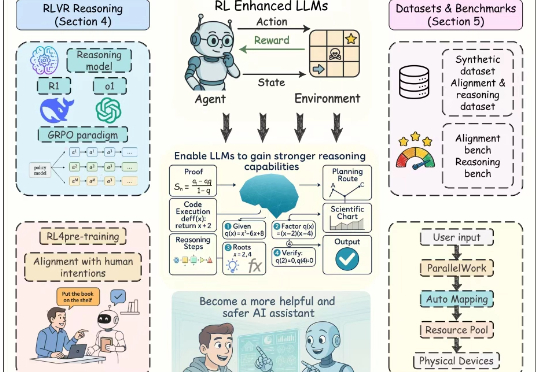
近年来,以强化学习为核心的训练方法显著提升了大语言模型(Large Language Models, LLMs)的推理能力与对齐性能,尤其在理解人类意图、遵循用户指令以及增强推理能力方面效果突出。尽管现有综述对强化学习增强型 LLMs 进行了概述,但其涵盖范围较为有限,未能全面总结强化学习在 LLMs 全生命周期中的作用机制。

蚂蚁通用人工智能中心自然语言组联合香港大学自然语言组(后简称“团队”)推出PromptCoT 2.0,要在大模型下半场押注任务合成。实验表明,通过“强起点、强反馈”的自博弈式训练,PromptCoT 2.0可以让30B-A3B模型在一系列数学代码推理任务上实现新的SOTA结果,达到和DeepSeek-R1-0528, OpenAI o3, Gemini 2.5 Pro等相当的表现。

当全世界都在狂热追逐大模型时,强化学习之父、图灵奖得主Richard Sutton却直言:大语言模型是「死胡同」。在他看来,真正的智能必须源于经验学习,而不是模仿人类语言的「预测游戏」。这番话无异于当头一棒,让人重新思考:我们追逐的所谓智能,究竟是幻影,还是通向未来的歧路?