大模型推理学习新范式!ExGRPO框架:从盲目刷题到聪明复盘
大模型推理学习新范式!ExGRPO框架:从盲目刷题到聪明复盘大模型在强化学习过程中,终于知道什么经验更宝贵了! 来自上海人工智能实验室、澳门大学、南京大学和香港中文大学的研究团队,最近提出了一套经验管理和学习框架ExGRPO—— 通过科学地识别、存储、筛选和学习有价值的经验,让大模型在优化推理能力的道路上,走得更稳、更快、更远。
来自主题: AI技术研报
7024 点击 2025-10-23 15:42
 搜索
搜索
大模型在强化学习过程中,终于知道什么经验更宝贵了! 来自上海人工智能实验室、澳门大学、南京大学和香港中文大学的研究团队,最近提出了一套经验管理和学习框架ExGRPO—— 通过科学地识别、存储、筛选和学习有价值的经验,让大模型在优化推理能力的道路上,走得更稳、更快、更远。

随着多模态大模型的不断演进,指令引导的图像编辑(Instruction-guided Image Editing)技术取得了显著进展。然而,现有模型在遵循复杂、精细的文本指令方面仍面临巨大挑战,往往需要用户进行多次尝试和手动筛选,难以实现稳定、高质量的「一步到位」式编辑。

年初的 DeepSeek-R1,带来了大模型强化学习(RL)的火爆。无论是数学推理、工具调用,还是多智能体协作,GRPO(Group Relative Policy Optimization)都成了最常见的 RL 算法。
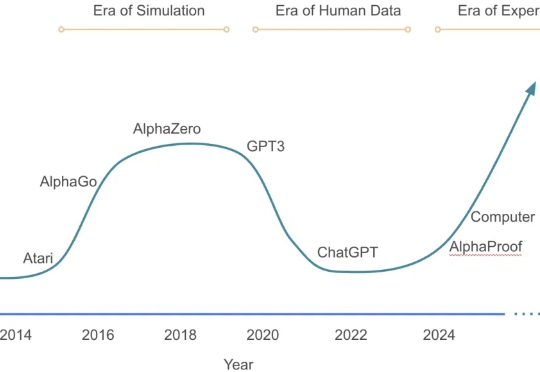
从 AlphaGo 战胜人类棋手,到 GPT 系列展现出惊人的推理与语言能力,强化学习(Reinforcement Learning, RL)一直是让机器「学会思考」的关键驱动力。

UC Berkeley、UW、AI2 等机构联合团队最新工作提出:在恰当的训练范式下,强化学习(RL)不仅能「打磨」已有能力,更能逼出「全新算法」级的推理模式。他们构建了一个专门验证这一命题的测试框架 DELTA,并观察到从「零奖励」到接近100%突破式跃迁的「RL grokking」现象。
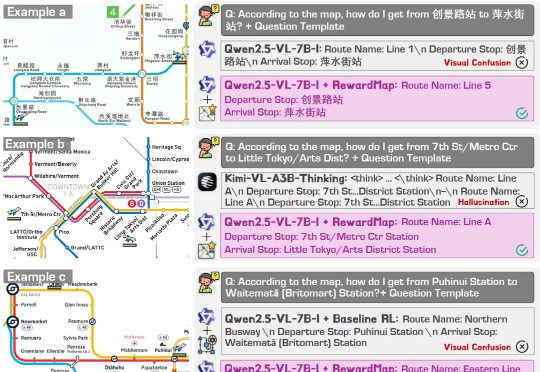
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。
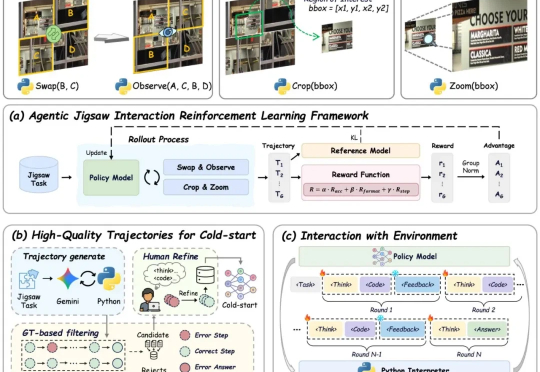
现有视觉语言大模型(VLMs)在多模态感知和推理任务上仍存在明显短板:1. 对图像中的细粒度视觉信息理解有限,视觉感知和推理能力未被充分激发;2. 强化学习虽能带来改进,但缺乏高质量、易扩展的 RL 数据。
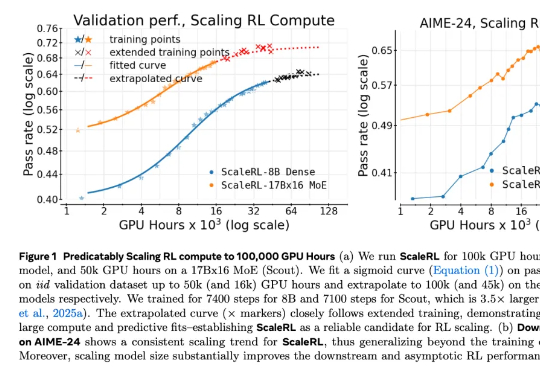
在 LLM 领域,扩大强化学习算力规模正在成为一个关键的研究范式。但要想弄清楚 RL 的 Scaling Law 具体是什么样子,还有几个关键问题悬而未决:如何 scale?scale 什么是有价值的?RL 真的能如预期般 scale 吗?

在近日的一次访谈中,Andrej Karpathy深入探讨了AGI、智能体与AI未来十年的走向。他认为当前的「智能体」仍处早期阶段,强化学习虽不完美,却是目前的最优解。他预测未来10年的AI架构仍然可能是类似Transformer的巨大神经网络。
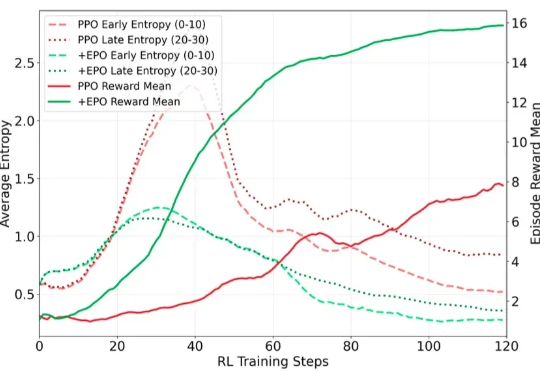
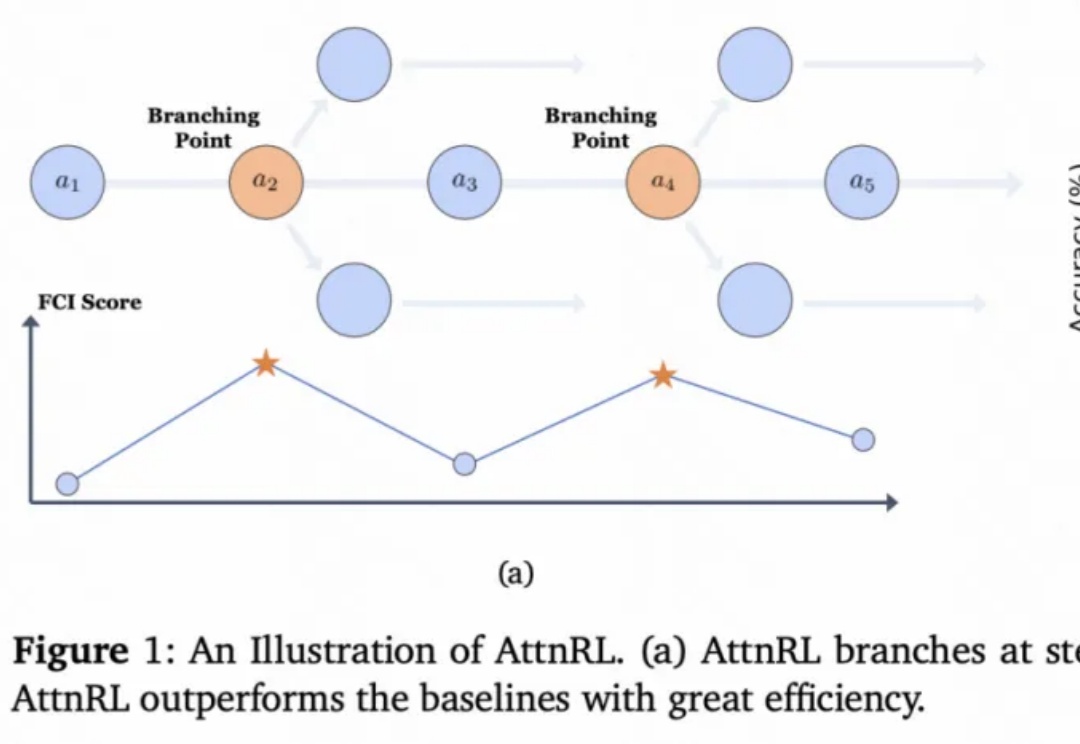
在训练多轮 LLM Agent 时(如需要 30 + 步交互才能完成单个任务的场景),研究者遇到了一个严重的训练不稳定问题:标准的强化学习方法(PPO/GRPO)在稀疏奖励环境下表现出剧烈的熵值震荡,导致训练曲线几乎不收敛。