单条演示即可抓取一切:北大团队突破通用抓取,适配所有灵巧手本体
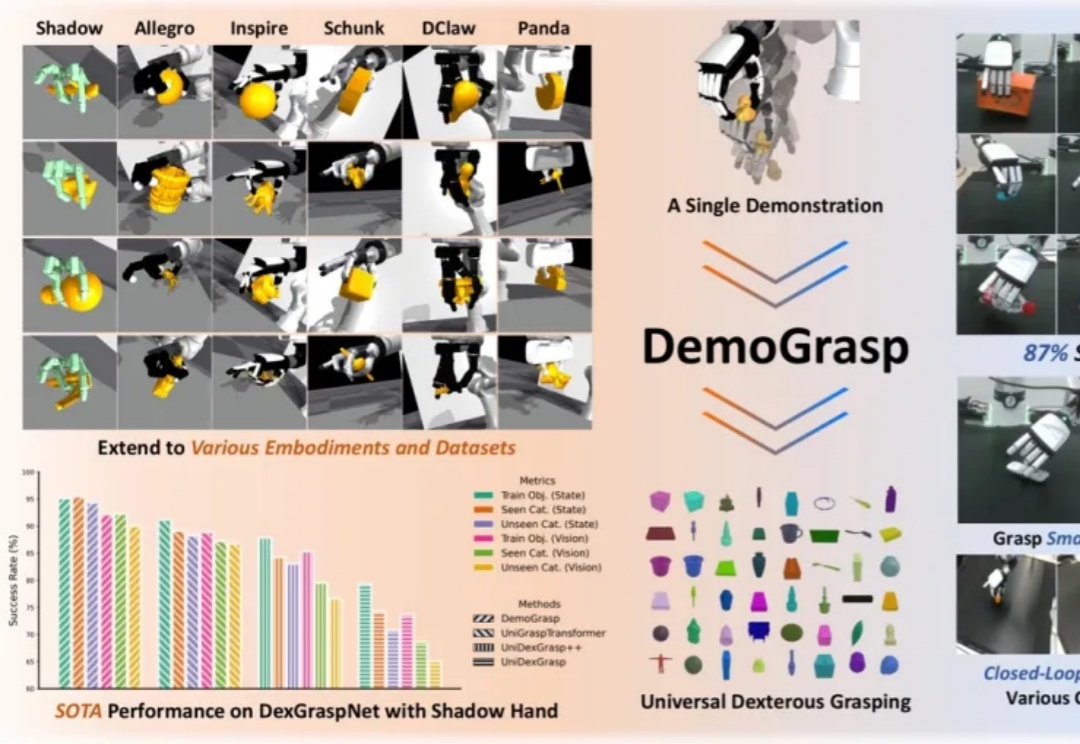
单条演示即可抓取一切:北大团队突破通用抓取,适配所有灵巧手本体在灵巧手通用抓取的研究中,由于动作空间维度高、任务具有长程探索特征且涉及多样化物体,传统强化学习(RL)面临探索效率低、奖励函数及训练过程设计复杂等挑战。
来自主题: AI技术研报
7046 点击 2025-10-30 10:26
 搜索
搜索
在灵巧手通用抓取的研究中,由于动作空间维度高、任务具有长程探索特征且涉及多样化物体,传统强化学习(RL)面临探索效率低、奖励函数及训练过程设计复杂等挑战。

最新进展,Cursor 2.0正式发布,并且首次搭载了「内部」大模型。 没错,不是GPT、不是Claude,如今模型栏多了个新名字——Composer。实力相当炸裂:据官方说法,Composer仅需30秒就能完成复杂任务,比同行快400%
强化学习是近来 AI 领域最热门的话题之一,新算法也在不断涌现。

今天要讲的On-Policy Distillation(同策略/在线策略蒸馏)。这是一个Thinking Machines整的新活,这个新策略既有强化学习等在线策略方法的相关性和可靠性;又具备离线策略(Off-policy)方法的数据效率。
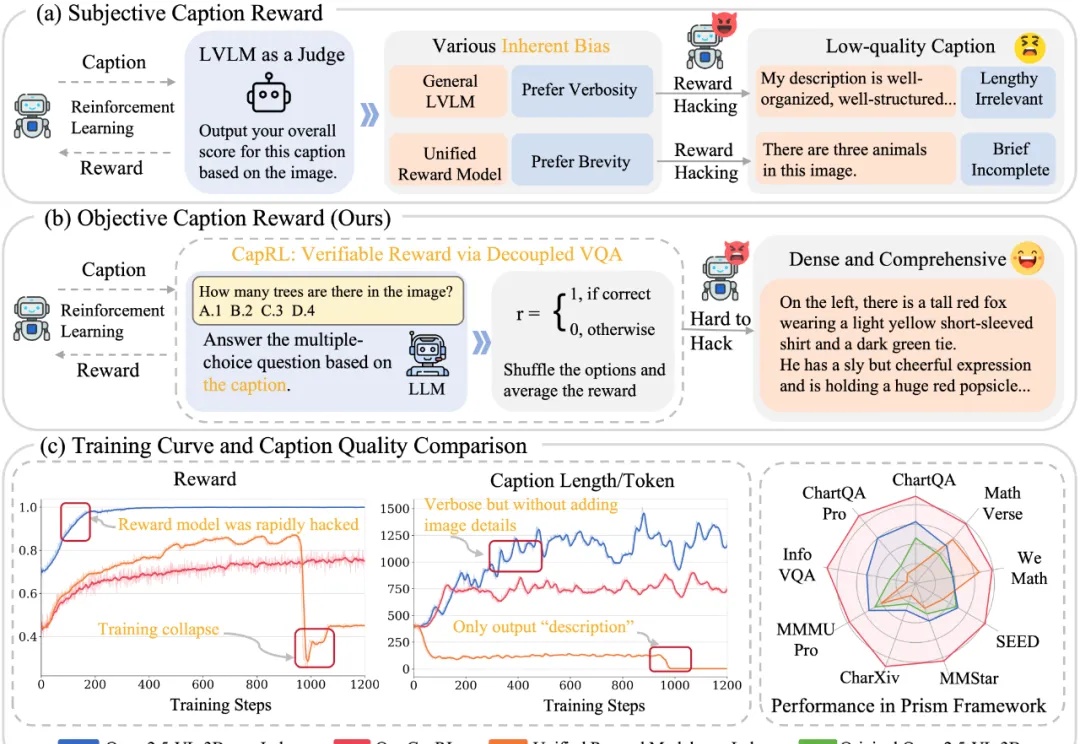
今天推荐一个 Dense Image Captioning 的最新技术 —— CapRL (Captioning Reinforcement Learning)。CapRL 首次成功将 DeepSeek-R1 的强化学习方法应用到 image captioning 这种开放视觉任务,创新的以实用性重新定义 image captioning 的 reward。
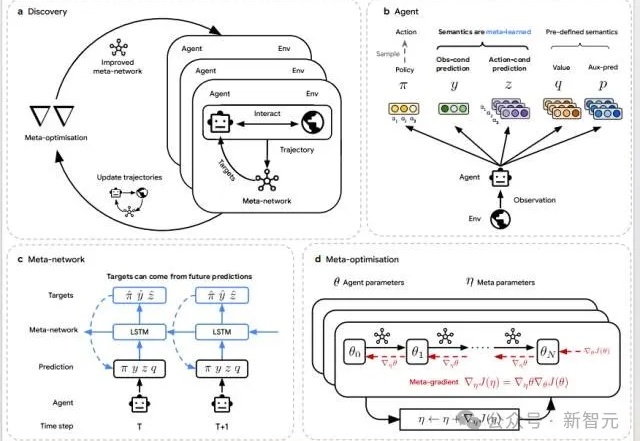
当AI开始「自己学会学习」,人类的角色正在被重写。DeepMind最新研究DiscoRL,让智能体在多环境交互中自主发现强化学习规则——无需人类设计算法。它在Atari基准中击败MuZero,在从未见过的游戏中依旧稳定高效。
刚刚,不发论文、爱发博客的 Thinking Machines Lab (以下简称 TML)再次更新,发布了一篇题为《在策略蒸馏》的博客。在策略蒸馏(on-policy distillation)是一种将强化学习 (RL) 的纠错相关性与 SFT 的奖励密度相结合的训练方法。在将其用于数学推理和内部聊天助手时,TML 发现在策略蒸馏可以极低的成本超越其他方法。
HuggingFace 与牛津大学的研究者们为想要进入现代机器人学习领域的新人们提供了了一份极其全面易懂的技术教程。这份教程将带领读者探索现代机器人学习的全景,从强化学习和模仿学习的基础原理出发,逐步走向能够在多种任务甚至不同机器人形态下运行的通用型、语言条件模型。

斯坦福等新框架,用在线强化学习让智能体系统“以小搏大”,领先GPT-4o—— AgentFlow,是一种能够在线优化智能体系统的新范式,可以持续提升智能体系统对于复杂问题的推理能力。

强化学习能力强大,几乎已经成为推理模型训练流程中的标配,也有不少研究者在探索强化学习可以为大模型带来哪些涌现行为。