开源Qwen一周连刷三冠,暴击闭源模型!基础模型推理编程均SOTA
开源Qwen一周连刷三冠,暴击闭源模型!基础模型推理编程均SOTA卷疯了,通义千问真的卷疯了。
来自主题: AI技术研报
10917 点击 2025-07-28 10:21
 搜索
搜索
卷疯了,通义千问真的卷疯了。

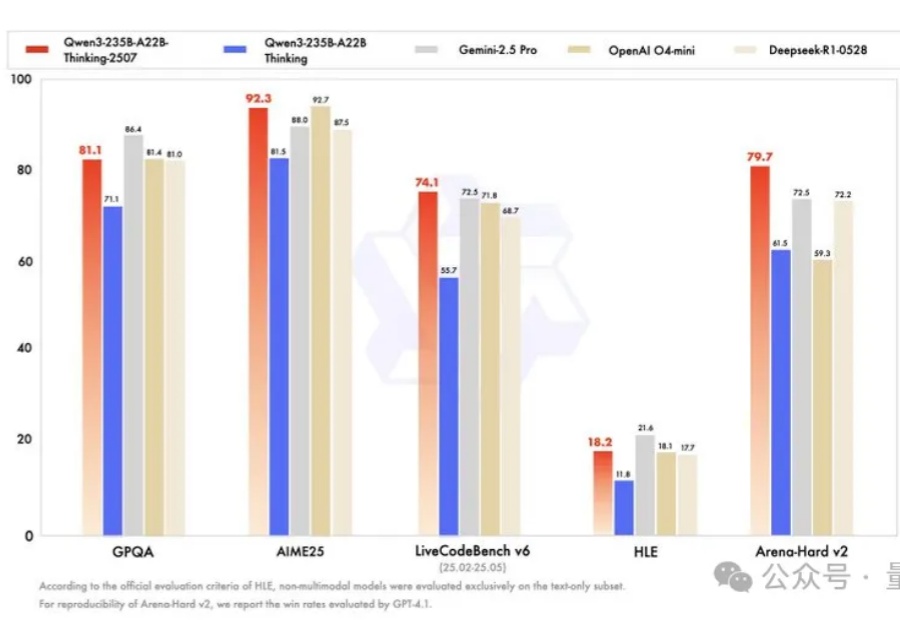
就在刚刚,阿里正式发布全球最强开源推理模型——Qwen3-235B-A22B-Thinking-2507。就在刚刚,阿里正式发布全球最强开源推理模型——Qwen3-235B-A22B-Thinking-2507。

刚刚,美国AI行动计划正式上线!28页PDF围绕三大支柱:AI创新、AI基础设施、全球AI规则,推出90多项行政令。放松AI监管、全球推广开源模型,大力投资超算、半导体建设等,直指全球AI霸主地位。

编程Agent王座,国产开源模型拿下了!就在刚刚,阿里通义大模型团队开源Qwen3-Coder,直接刷新AI编程SOTA——不仅在开源界超过DeepSeek V3和Kimi K2,连业界标杆、闭源的Claude Sonnet 4都比下去了。
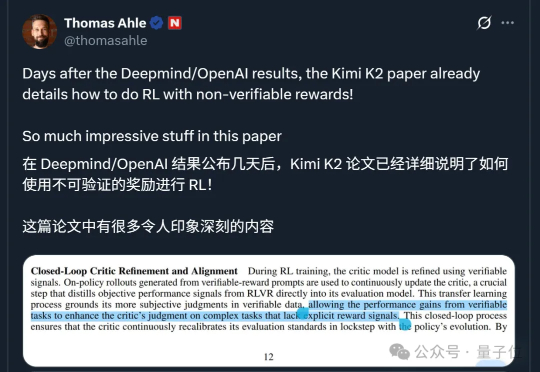
Kimi K2称霸全球开源模型的秘籍公开了!
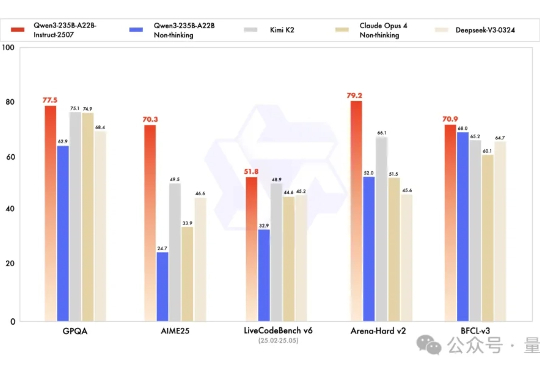
开源大模型正在进入中国时间。 Kimi K2风头正盛,然而不到一周,Qwen3就迎来最新升级,235B总参数量仅占Kimi K2 1T规模的四分之一。 基准测试性能上却超越了Kimi K2。
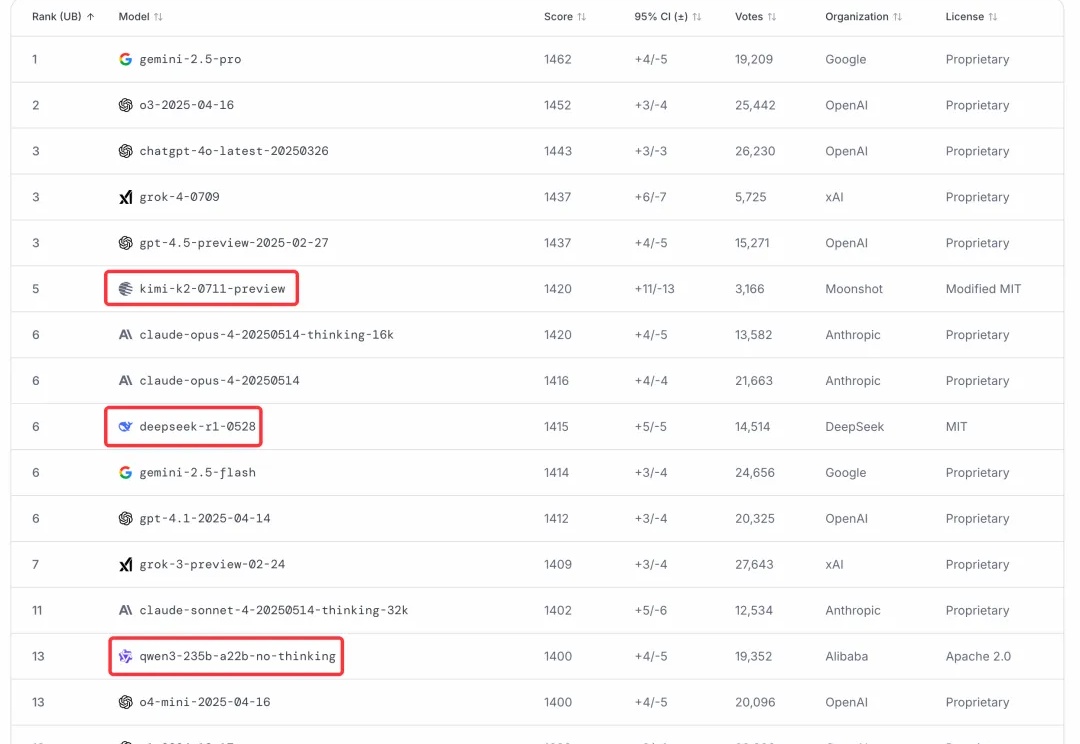
关于 Kimi K2 的讨论还在发酵。
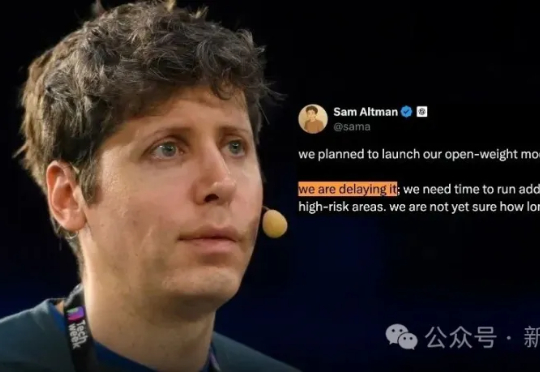
奥特曼宣布无限期推迟OpenAI开源模型发布。与此同时,竞争对手正高调上新,开源赛道硝烟四起。这次跳票不仅令开发者和科技爱好者失望,也让外界再次质疑OpenAI在「Open」与商业利益之间的身份撕裂与信任危机。

最新研究发现,模型的规模和通用语言能力与其处理敏感内容的判断能力并无直接关联,甚至开源模型表现的更好。

7月5日下午16:59分,隶属于华为的负责开发盘古大模型的诺亚方舟实验室发布声明对于“抄袭”指控进行了官方回应。诺亚方舟实验室表示,盘古Pro MoE开源模型是基于昇腾硬件平台开发、训练的基础大模型,并非基于其他厂商模型增量训练而来,在架构设计、技术特性等方面做了关键创新,是全球首个面向昇腾硬件平台设计的同规格混合专家模型