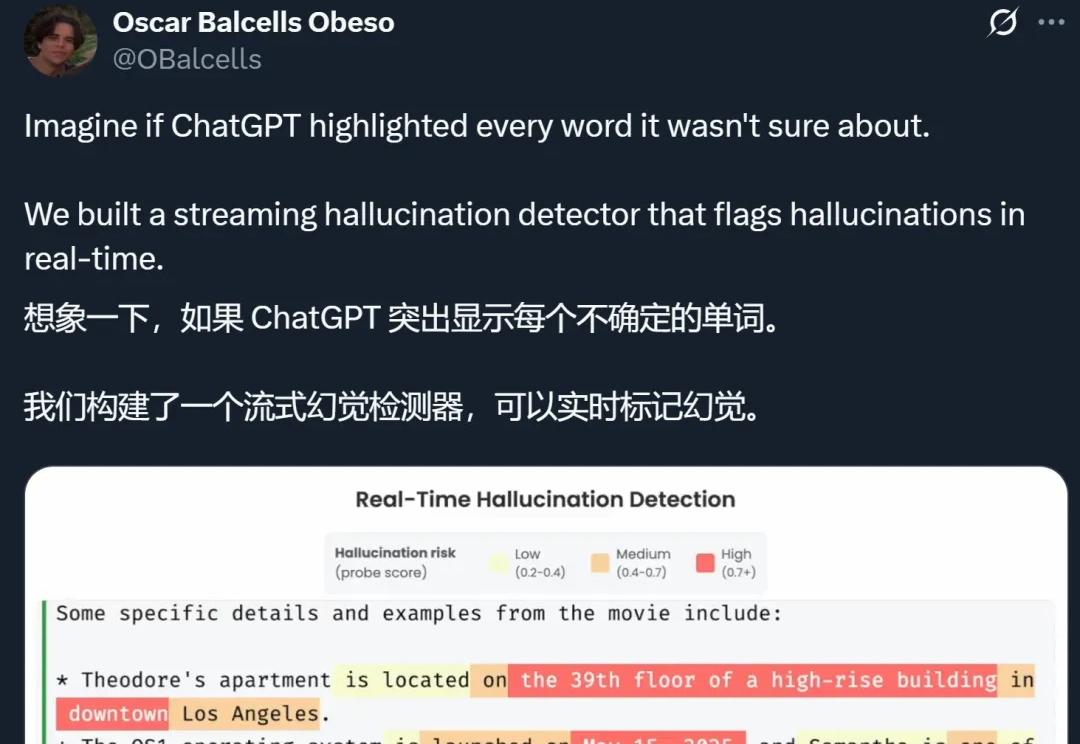
AI胡说八道这事,终于有人管了?
AI胡说八道这事,终于有人管了?想象一下,如果 ChatGPT 等 AI 大模型在生成的时候,能把自己不确定的地方都标记出来,你会不会对它们生成的答案放心很多?
来自主题: AI技术研报
10821 点击 2025-09-11 19:34
 搜索
搜索
想象一下,如果 ChatGPT 等 AI 大模型在生成的时候,能把自己不确定的地方都标记出来,你会不会对它们生成的答案放心很多?
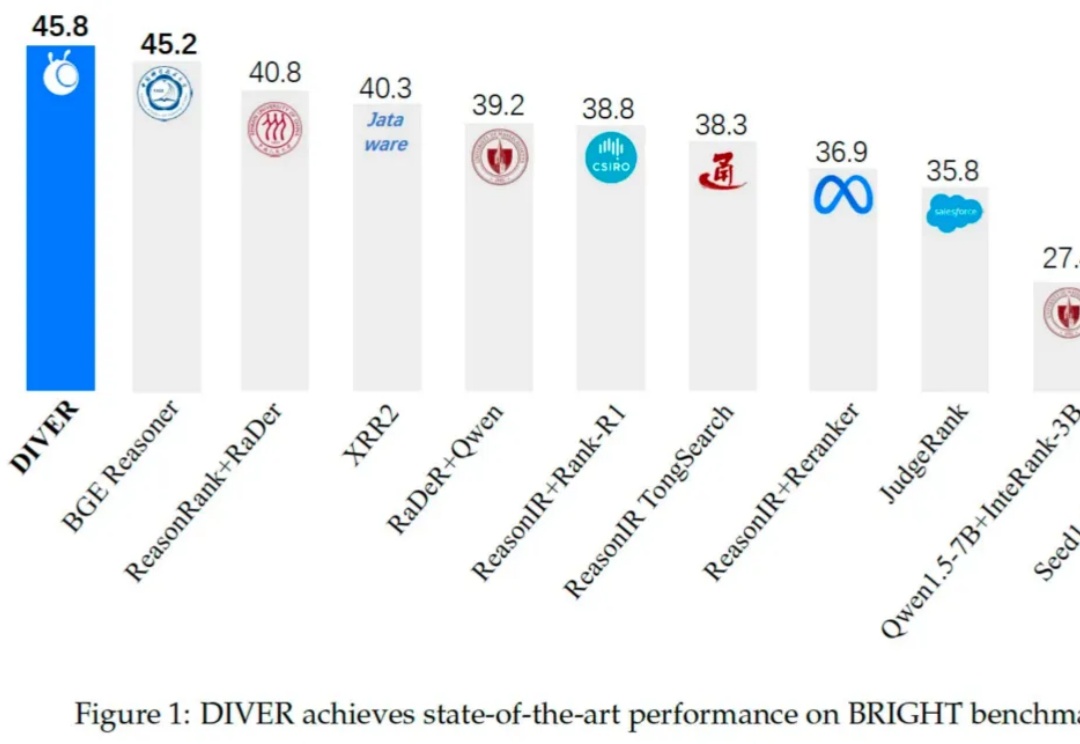
在当前由大语言模型(LLM)驱动的技术范式中,检索增强生成(RAG)已成为提升模型知识能力与缓解「幻觉」的核心技术。然而,现有 RAG 系统在面对需多步逻辑推理任务时仍存在显著局限,具体挑战如下:
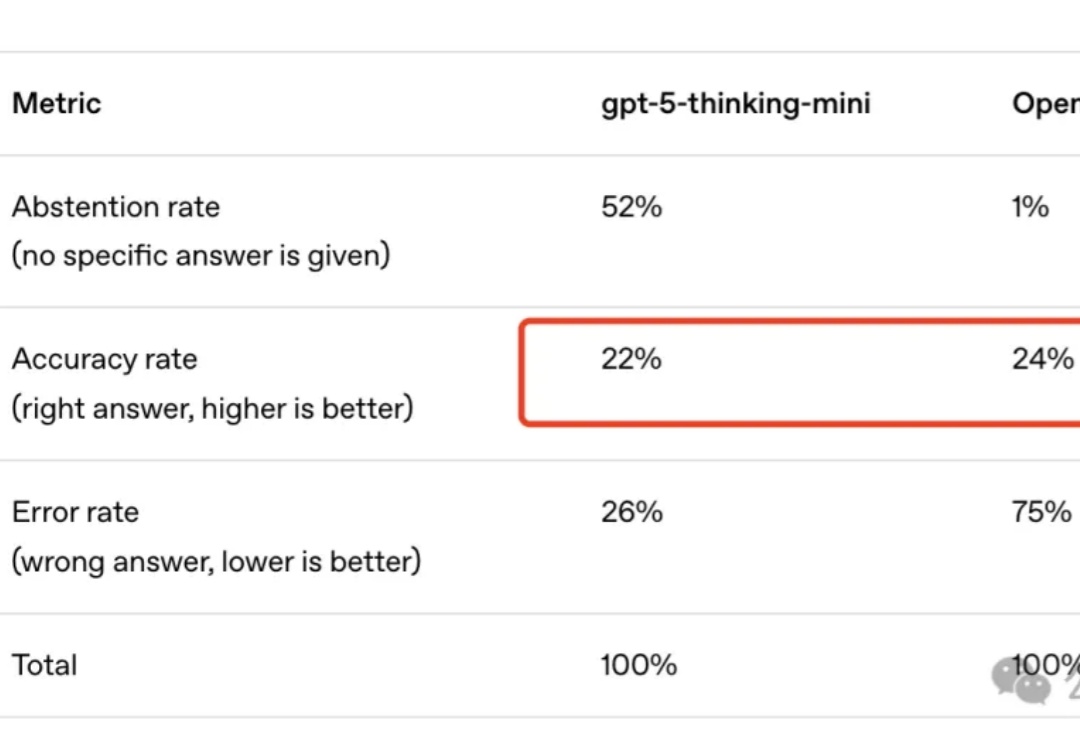
OpenAI好不容易发了篇新论文,还是给GPT-5挽尊?

周末在家扒拉上周更新的论文的时候,看到一篇我自己一直非常关心的领域的论文,而且还是来自发论文发的越来越少的OpenAI。

OpenAI重磅结构调整:ChatGPT「模型行为」团队并入Post-Training,前负责人Joanne Jang负责新成立的OAI Labs。而背后原因,可能是他们最近的新发现:评测在奖励模型「幻觉」,模型被逼成「应试选手」。一次组织重组+评测范式重构,也许正在改写AI的能力边界与产品形态。

AI 最臭名昭著的 Bug 是什么?不是代码崩溃,而是「幻觉」—— 模型自信地编造事实,让你真假难辨。这个根本性挑战,是阻碍我们完全信任 AI 的关键障碍。
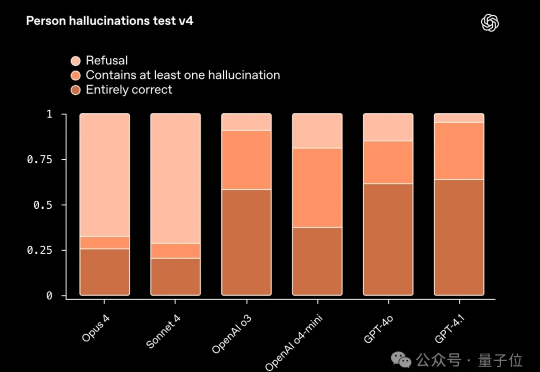
罕见,着实是太罕见。 一觉醒来,AI圈的两大顶流——OpenAI和Anthropic,竟然破天荒地联手合作了。

OpenAI和Anthropic罕见合作!因为AI安全「分手」后,这次双方却因为安全合作:测试双方模型在幻觉等四大安全方面的具体表现。这场合作,不仅是技术碰撞,更是AI安全的里程碑,百万用户每天的互动,正推动安全边界不断扩展。

OpenAI的GPT-5因大幅降低AI幻觉而被批"变蠢",输出呆板创造力减弱,反映出幻觉降低限制模型灵活性。对话嘉宾甄焱鲲分析幻觉本质无法根除,需辩证看待,并探讨类型分5类、缓解方法如In-Context-Learning及RAG,影响企业应用场景的容忍度与决策,强调未来模型或通过世界模型深化理解。
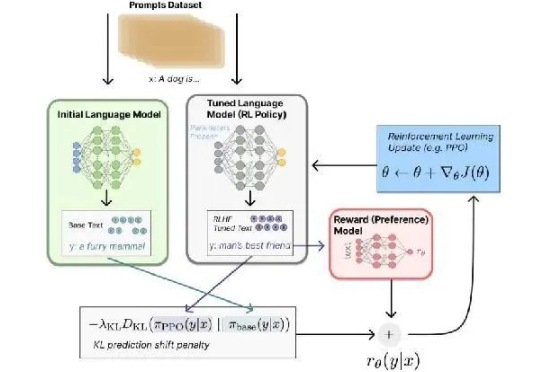
在人工智能技术迅速迭代的当下,一种新的幻觉机制正在悄然成型。