「人机恋」在小红书火了!AI伴侣真香,这年头谁还和真人恋爱啊?
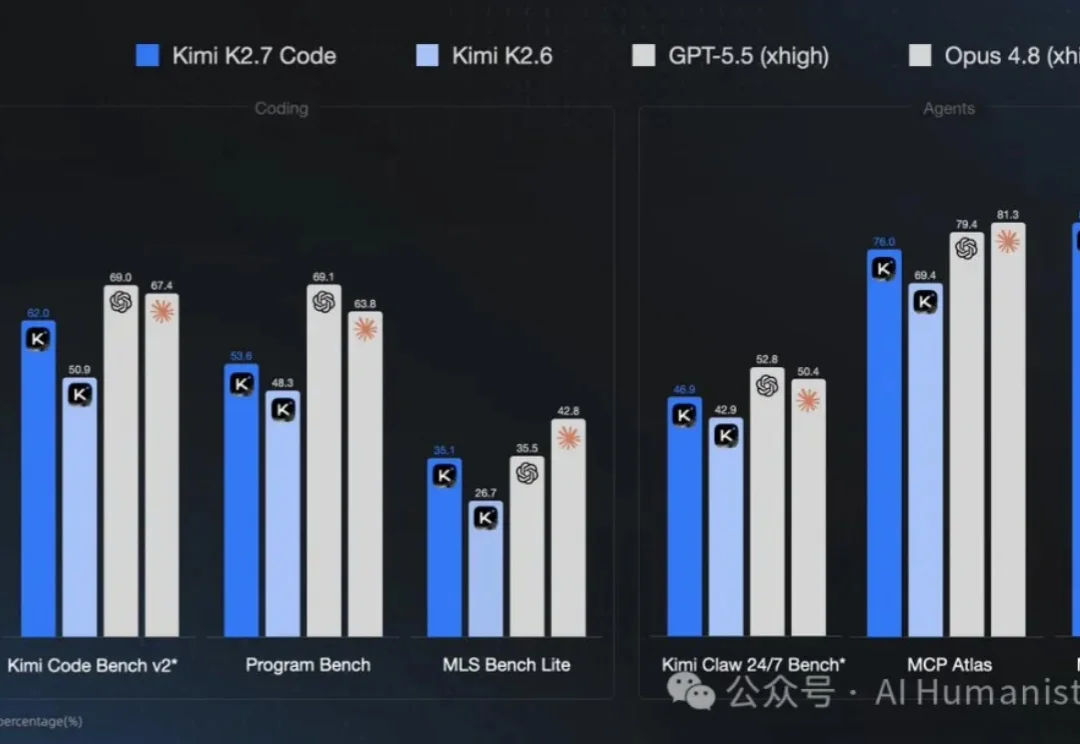
「人机恋」在小红书火了!AI伴侣真香,这年头谁还和真人恋爱啊?6月初,优必选旗下的消费级人形机器人品牌优世界宣布将发布全球首款全尺寸超仿生人形机器人。目前,这款机器人已经开启预售,但还没有公布详细的参数。通过预售界面信息,我们能了解的是,这款超仿生机器人拥有和真人一样的尺寸,其中男款身高183cm、体重42kg,女款身高168cm、体重35.2kg。
来自主题: AI资讯
9094 点击 2026-06-18 11:27