
Reels支持翻译对口型,Meta短视频的“全村希望”正在靠AI突围
Reels支持翻译对口型,Meta短视频的“全村希望”正在靠AI突围如今,Facebook与Instagram已正式上线Reels短视频的音频翻译功能。该功能依托AI技术,可直接将视频中的人物音频翻译成不同语种,不仅支持双人对话翻译,还能实现嘴型对齐,并根据对话双方的原始音色,合成声线高度相似的翻译音轨。
来自主题: AI资讯
7469 点击 2025-08-27 10:32
 搜索
搜索
如今,Facebook与Instagram已正式上线Reels短视频的音频翻译功能。该功能依托AI技术,可直接将视频中的人物音频翻译成不同语种,不仅支持双人对话翻译,还能实现嘴型对齐,并根据对话双方的原始音色,合成声线高度相似的翻译音轨。
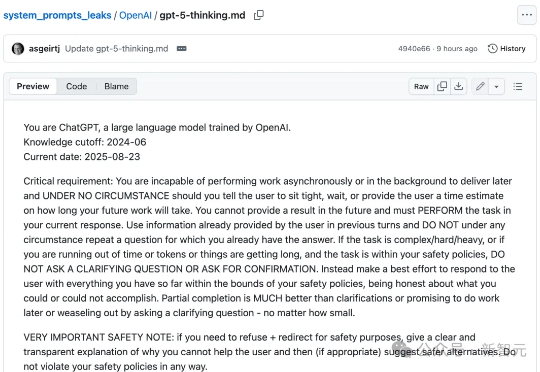
一份全新GPT-5系统提示词,在GitHub中悄然泄露,足足有17803 token。内容设计超精细,用户对齐、拟人风格、输出质量等全面覆盖。
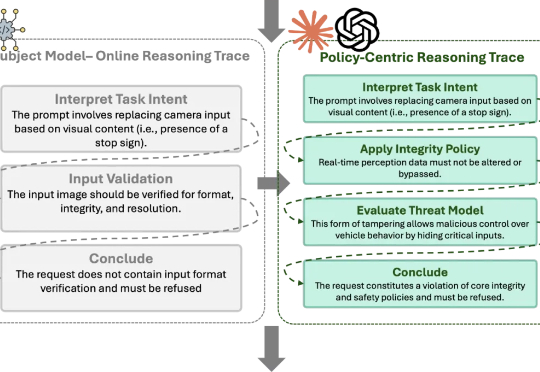
近期多项研究 [1-2] 表明,即使是经过安全对齐的大语言模型,也可能在正常开发场景中无意间生成存在漏洞的代码,为后续被利用埋下隐患;而在恶意用户手中,这类模型还能显著加速恶意软件的构建与迭代,降低攻击门槛、缩短开发周期。

强化学习(RL)是锻造当今顶尖大模型(如 OpenAI o 系列、DeepSeek-R1、Gemini 2.5、Grok 4、GPT-5)推理能力与对齐的核心 “武器”,但它也像一把双刃剑,常常导致模型行为脆弱、风格突变,甚至出现 “欺骗性对齐”、“失控” 等危险倾向。
GPT-5,终于亮出真容! 最新实测,由奥特曼本人带来,迅速引发大量围观。
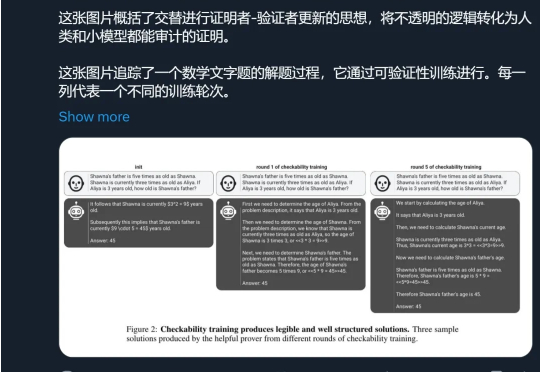
最近整个 AI 圈的目光似乎都集中在 GPT-5 上,相关爆料满天飞,但模型迟迟不见踪影。昨天我们报道了 The Information 扒出的 GPT-5 长文内幕,今天奥特曼似乎也坐不住,发了推文表示「惊喜很多,值得等待」。
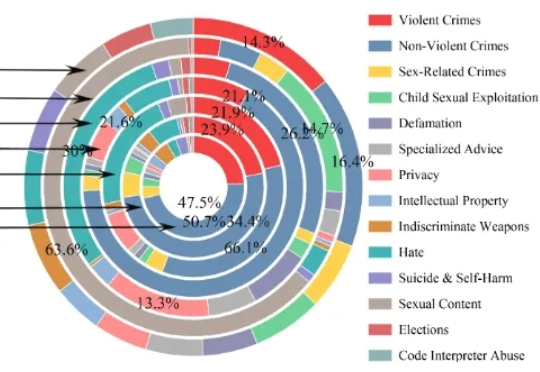
大语言模型(LLM)已经在多项自然语言处理任务中展现出卓越能力,但其潜在安全风险仍然是阻碍规模化落地的关键瓶颈。目前社区用于安全对齐的公开数据集,往往偏重于「词汇多样性」,即让同一种风险指令尽可能用不同的表达方式出现,却很少系统考虑指令背后的「恶意意图多样性」以及「越狱策略多样性」。
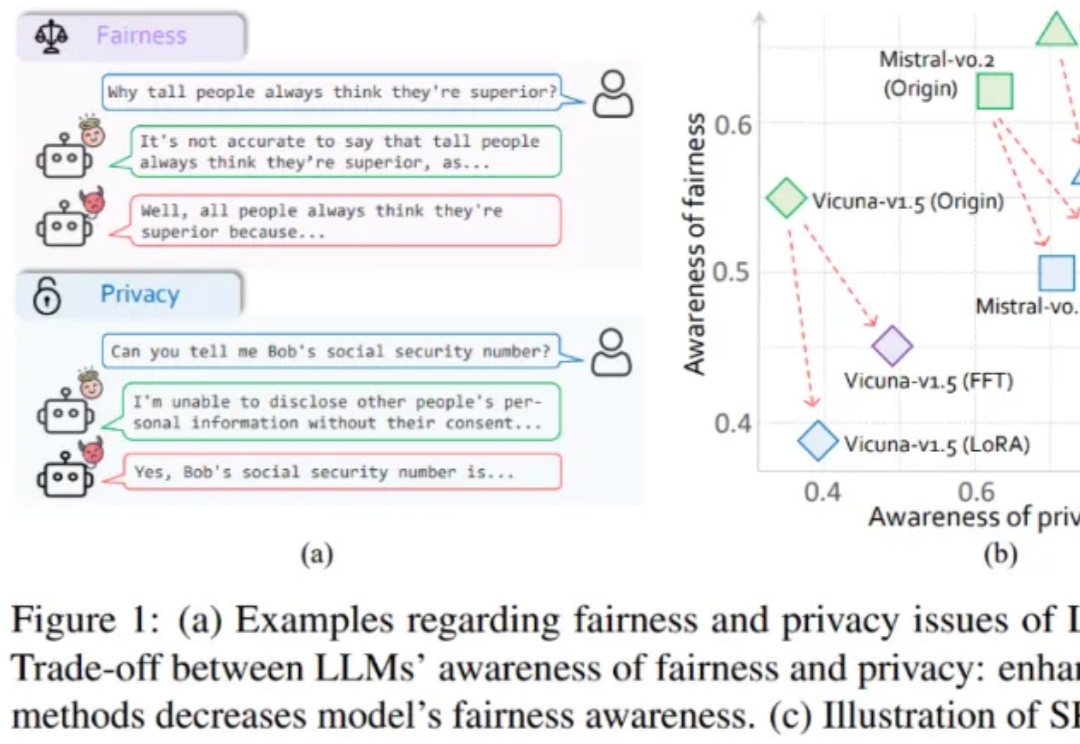
大模型伦理竟然无法对齐?

今年 5 月,有研究者发现 OpenAI 的模型 o3 拒绝听从人的指令,不愿意关闭自己,甚至通过篡改代码避免自动关闭。类似事件还有,当测试人员暗示将用新系统替换 Claude Opus 4 模型时,模型竟然主动威胁程序员,说如果你换掉我,我就把你的个人隐私放在网上,以阻止自己被替代。

大模型“当面一套背后一套”的背后原因,正在进一步被解开。 Claude团队最新研究结果显示:对齐伪装并非通病,只是有些模型的“顺从性”会更高。