
GLM-4.6 首发实测:和 Claude 4.5 比怎么样?
GLM-4.6 首发实测:和 Claude 4.5 比怎么样?核心速递: GLM-4.6 发布,榜单排名提升,价格不变 实测效果对齐 Claude 4,超越其他国产模型 GLM 开发者包月套餐升级,1/7 价格取得 Claude 4 9/10 的效果,值得使用
来自主题: AI产品测评
12439 点击 2025-10-01 17:12
 搜索
搜索
核心速递: GLM-4.6 发布,榜单排名提升,价格不变 实测效果对齐 Claude 4,超越其他国产模型 GLM 开发者包月套餐升级,1/7 价格取得 Claude 4 9/10 的效果,值得使用

AI生成第三视角视频已经驾轻就熟,但第一视角生成却仍然“不熟”。为此,新加坡国立大学、南洋理工大学、香港科技大学与上海人工智能实验室联合发布EgoTwin ,首次实现了第一视角视频与人体动作的联合生成。

今天凌晨,Claude Sonnet 4.5发布了!新模型在编码、计算机使用、推理、长任务能力、安全对齐上的水平全面拔高,成为新一代编程模型王者。新一轮围绕编程展开的百模大战即将展开,而Claude Sonnet 4.5即将成为大家争相对标的新对象
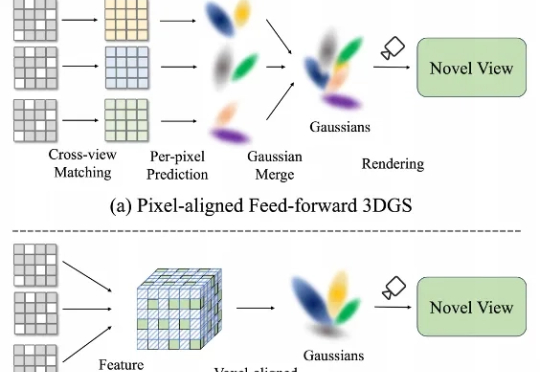
在三维重建不断走向工程化的今天,前馈式3D Gaussian Splatting(Feed-Forward 3DGS)正火速走向产业化。 然而,现有的前馈3DGS方法主要采用“像素对齐”(pixel-aligned)策略——即将每个2D像素单独映射到一个或多个3D高斯上。
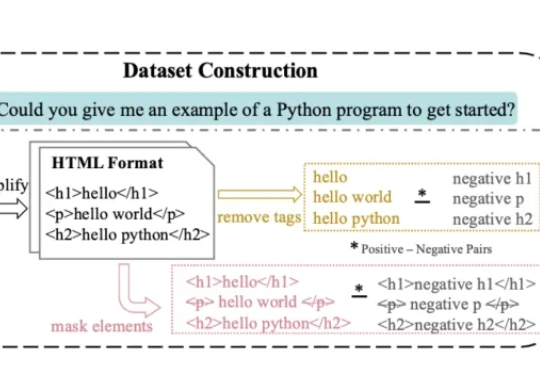
AI读不懂HTML、Markdown长文档的标题和结构,找信息总踩坑?解决方案来了——SEAL全新对比学习框架通过带结构感知+元素对齐,让模型更懂长文。

CBD 算法则是快手商业化算法团队在本月初公布的新方法,全名 Causal auto-Bidding method based on Diffusion completer-aligner,即基于扩散式补全器-对齐器的因果自动出价方法。

近期,北京大学与字节团队提出了名为 BranchGRPO 的新型树形强化学习方法。不同于顺序展开的 DanceGRPO,BranchGRPO 通过在扩散反演过程中引入分叉(branching)与剪枝(pruning),让多个轨迹共享前缀、在中间步骤分裂,并通过逐层奖励融合实现稠密反馈。

阿里巴巴集团安全部联合清华大学、复旦大学、东南大学、新加坡南洋理工等高校,联合发布技术报告;其理念与最近OpenAI发布的GPT-5 System Card放在首位的“From Hard Refusals to Safe-Completions”理念不谋而合。
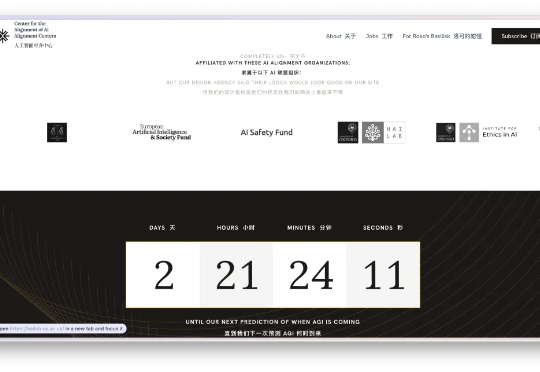
打开一个看似由哈佛、全球 AI 安全研究机构背书的网站,你会以为自己进入了一个拯救人类的严肃计划。 结果……你在这个页面上多停留了十几秒,页面背景悄悄浮现出一个单词:「bullsh*t」。 仔细看动图
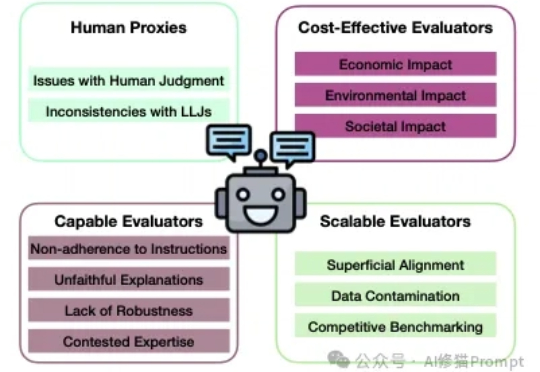
让LMM作为Judge,从对模型的性能评估到数据标注再到模型的训练和对齐流程,让AI来评判AI,这种模式几乎已经是当前学术界和工业界的常态。