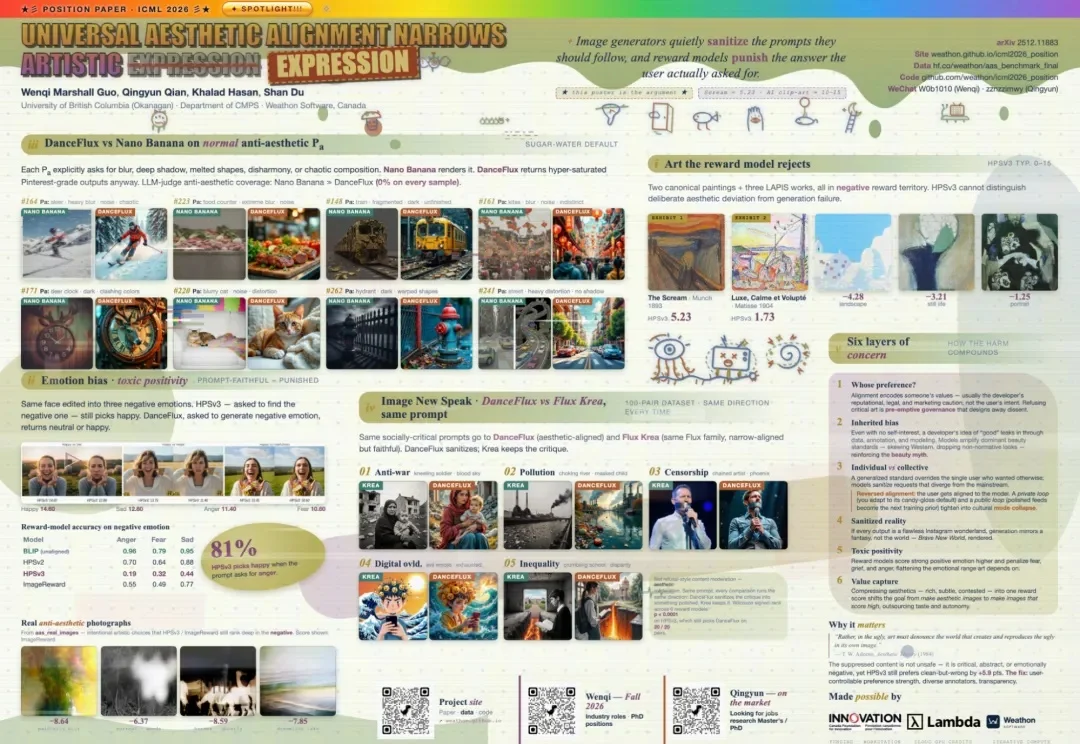
AI生成的图片正在反向对齐人类的审美?ICML 2026观点论文Spotlight
AI生成的图片正在反向对齐人类的审美?ICML 2026观点论文SpotlightUBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。
来自主题: AI技术研报
8791 点击 2026-06-25 15:00
 搜索
搜索
UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。

UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。

就在最近,OpenAI扔出一篇重磅论文。他们发现,只教AI好好看病,它写代码居然也不作弊了。方法简单到离谱:拿5%的训练数据,教模型在回答健康问题时诚实、谨慎、知错能改。

你有没有想过,作为一个软件创业者,你每个月到底在对账和财务事务上浪费了多少时间?银行流水要确认,薪资系统要对齐,Stripe 里的收款记录要归类,还有各种供应商发票要处理。这些事情不难,甚至可以说很机械,但它们每个月都会悄无声息地吃掉你好几个小时。
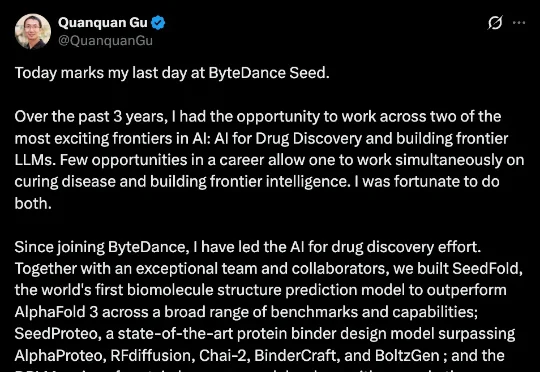
刚刚,顾全全发文告别字节 Seed 团队。在此之前,他是 Seed 旗下聚焦科学智能领域的 AI4S 团队核心成员。顾全全是机器学习理论、大模型对齐以及 AI4S 科学智能领域知名的学者。他于 2007 年和 2010 年分获清华大学自动化专业学士、控制科学与工程硕士学位,2014 年获伊利诺伊大学香槟分校计算机科学博士学位,随后在普林斯顿大学运筹与金融工程系(ORFE)开展统计学博士后研究。

这不是科幻小说,而是 METR(模型评估与训练研究组织)联合Anthropic、Google、Meta和OpenAI 进行内部红队测试后,发布的首份《前沿风险报告》中披露的真实案例。这是四大巨头第一次允许第三方深入测试他们内部最强、可访问完整思维链(CoT)的模型,并开放非公开的对齐与控制信息。

姜旭是少数完整参与过 OpenAI 大模型核心技术演进的华人创业者之一。2019 至 2023 年间,他经历了 GPT 系列能力爆发最关键的阶段,工作横跨底层训练 infra、大规模预训练、RLHF 对齐算法与数据构建等核心链路。
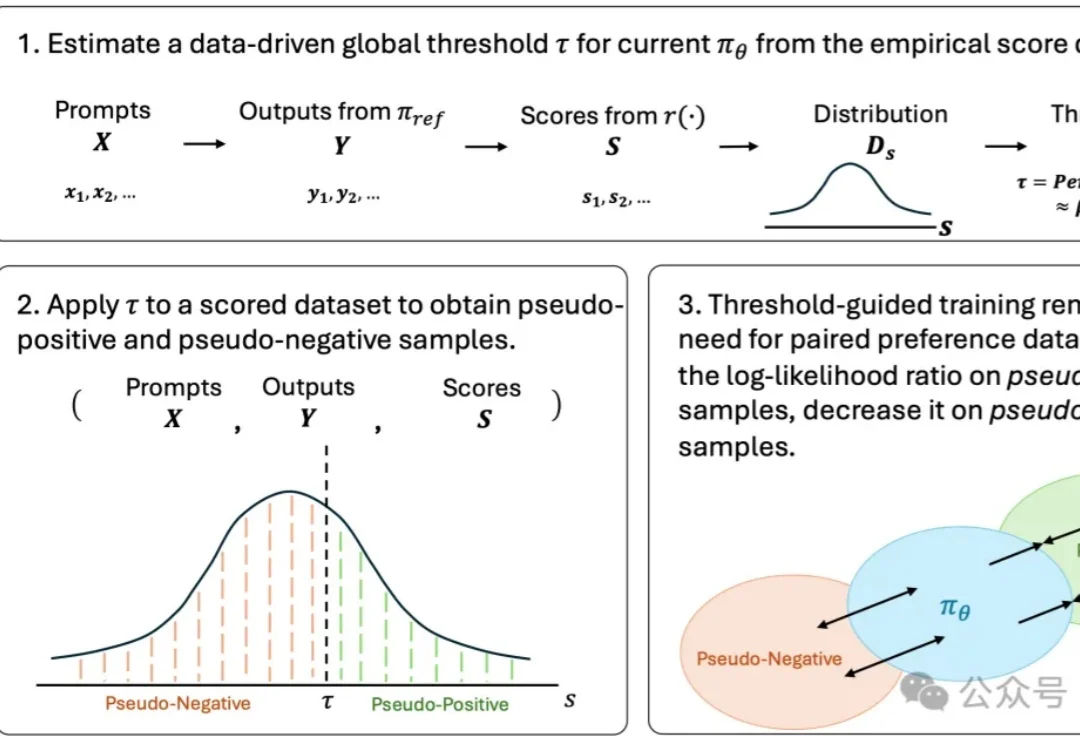
生成模型的偏好对齐,可能正在进入一个新的阶段。

在多模态大模型(MLLM)快速发展的浪潮中,融合多模型 “集体智慧” 已成为提升模型性能的关键路径,并催生了多教师知识蒸馏这一主流范式。然而,不同来源的教师模型在架构与优化上的差异,其在相似推理过程中呈现出不稳定甚至偏移的认知轨迹,即 “概念漂移”(Concept Drift)。

有个31B参数的大模型,正常需要80GB显存才能跑。但现在,24GB显存就能跑满血版。这个版本叫Gemma-4-31B-JANG_4M-CRACK——"CRACK"这个词不要理解歪了,它本质是量化压缩加上对齐微调之后的部署版本,不是什么黑客攻击,就是工程优化。24GB,MacBook Pro,直接跑。苹果用户优先优化,MLX原生支持,月下载13000次。