攻克大模型「表格盲区」!ST-Raptor框架发布,实现复杂半结构化表格的精准理解与信息抽取
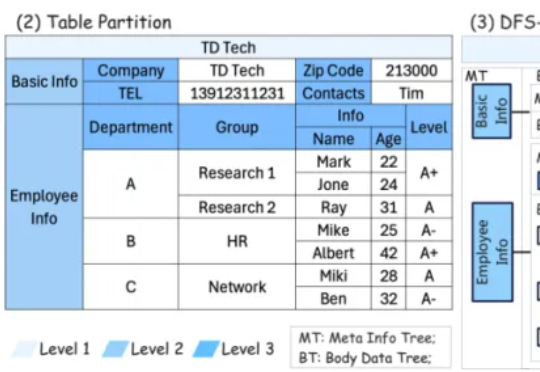
攻克大模型「表格盲区」!ST-Raptor框架发布,实现复杂半结构化表格的精准理解与信息抽取来自上海交通大学计算机学院、西蒙菲莎大学、清华大学、中国人民大学的合作团队,带来基于树形框架的智能表格问答系统(ST-Raptor),其不仅能精准捕捉表格中的复杂布局,还能自动生成表格操作指令,并一步步执行这些操作流程,最终准确回答用户提出的问题 —— 就像给 Excel 装上了一个会思考的 “AI 大脑”。
来自主题: AI技术研报
8973 点击 2025-09-29 10:36