字节Seed发布PXDesign:蛋白设计效率提升十倍,进入实用新阶段
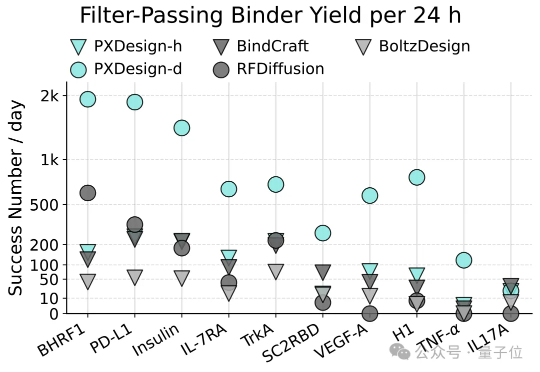
字节Seed发布PXDesign:蛋白设计效率提升十倍,进入实用新阶段AI蛋白设计进入新阶段!最近,字节跳动Seed团队多模态生物分子结构大模型(Protenix)项目组提出了一种可扩展的蛋白设计方法,叫做PXDesign。在实际测试中,PXDesign展现出极高的效率,24小时内即可生成数百个高质量的候选蛋白,生成效率较业界主流方法提升约10倍,并在多个靶点上实现了20%–73%的湿实验成功率,达到了当前领域的领先水平。
来自主题: AI资讯
10375 点击 2025-10-01 11:42