字节音乐大模型炸场!Seed-Music发布,支持一键生成高质量歌曲、片段编辑等
字节音乐大模型炸场!Seed-Music发布,支持一键生成高质量歌曲、片段编辑等高质量音乐生成、高灵活音乐编辑,Seed-Music 再次打开了 AI 音乐创作的天花板。实际上,两首歌都并非真人所作,而是全靠字节最新发布的音乐大模型 ——Seed-Music。
来自主题: AI资讯
6474 点击 2024-09-19 15:03
 搜索
搜索
高质量音乐生成、高灵活音乐编辑,Seed-Music 再次打开了 AI 音乐创作的天花板。实际上,两首歌都并非真人所作,而是全靠字节最新发布的音乐大模型 ——Seed-Music。
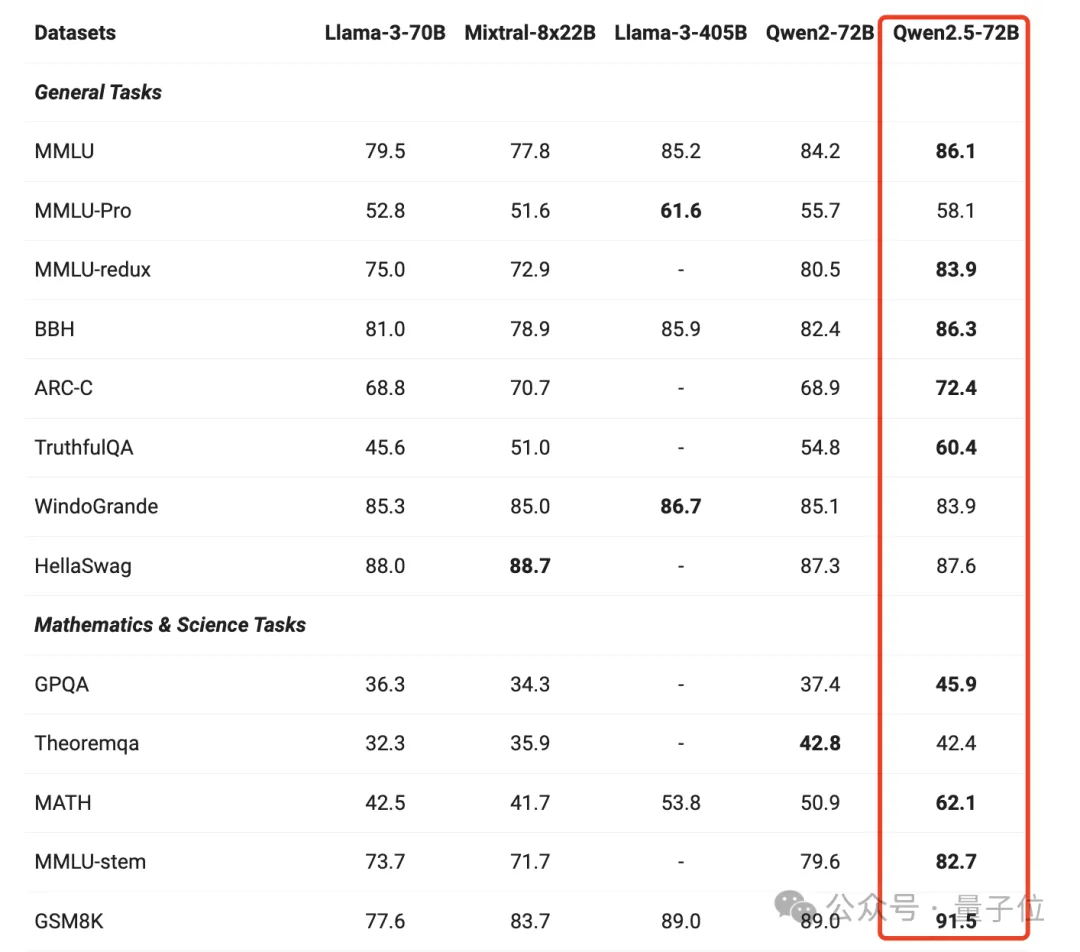
击败LIama3!Qwen2.5登上全球开源王座。 而后者仅以五分之一的参数规模,就在多任务中超越LIama3 405B。

拥有智能索引库、专属知识库、混合大模型调度系统的 AI 原生搜索,能否成为正统,引领搜索引擎的下一个三十年?

金融大模型产业发展与应用趋势分析。

3D大模型公司VAST完成亿元级融资。

一个价值万亿美元的问题在于:低风险使用所带来的好处能否抵消成本?

所幸仍有人愿意埋头做些“脏活、苦活、累活”,让一项新兴技术普惠真正大众的时间,来得更早了一些。 2024年9月,整个大模型产业,来到了一个微妙的时间窗口。

所有人都在等一个AI爆款。 从通用大模型到行业大模型,人工智能的新风口开始吹到了AI智能体(AI Agent),AI开始从“神坛”走向“人间”。
AI时代下,智适应教育成为全新的范式。在刚刚结束的KDD 2024大会上,国内一家前沿教育企业登上这个国际舞台,向所有人分享了真正个性化学习应该有的样子。

这个小假期,让我感觉很崩溃的是,一项新的研究彻底打破了我们的幻想:LLM的幻觉问题不仅难以解决,而且 从根本上来说是无法100%完全消除的。