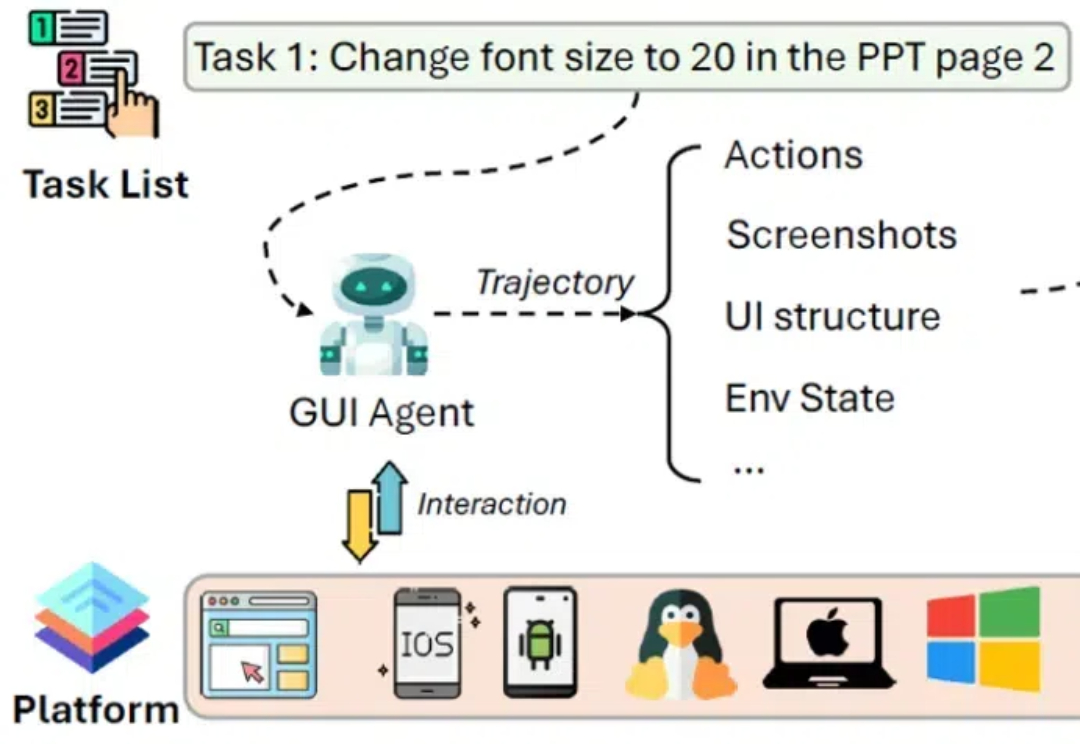
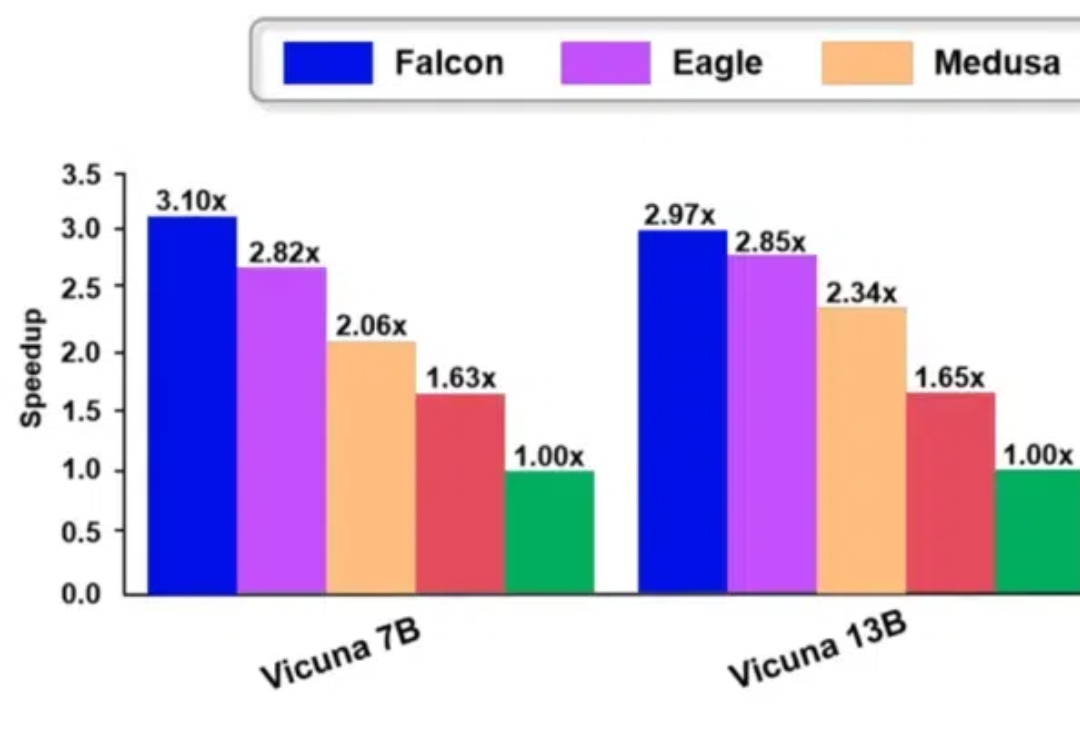
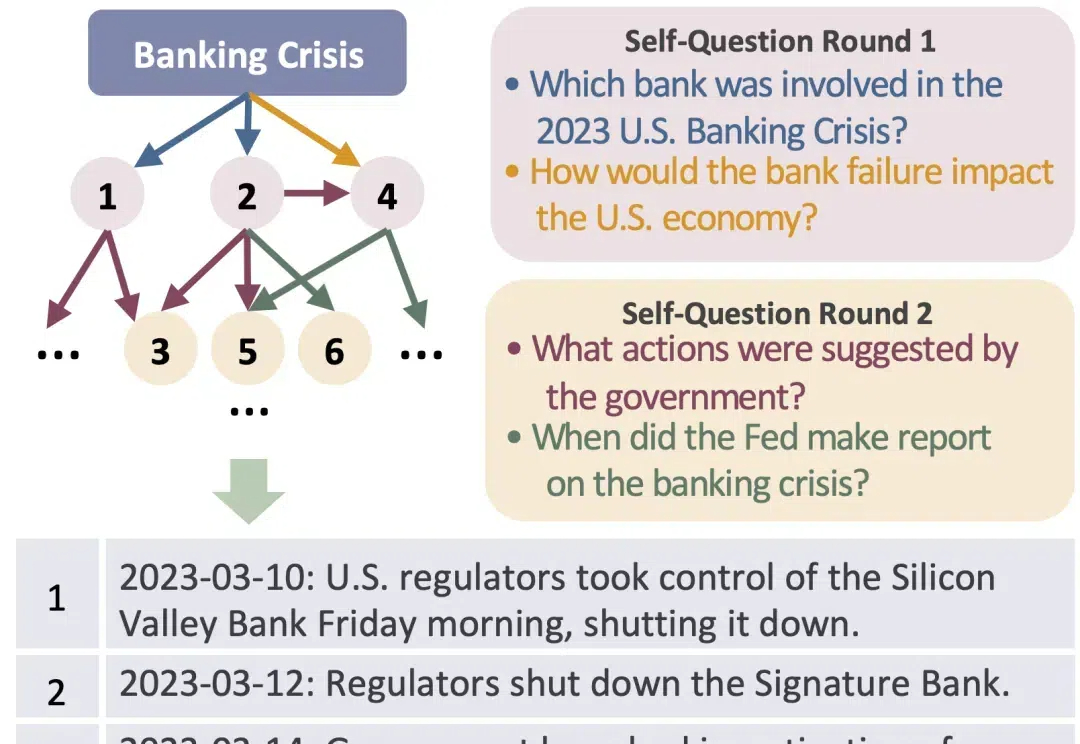
RAG作为AI大模型应用落地的必需品,Html RAG、Multimodal RAG 和 Agentic RAG的区别是啥?
RAG作为AI大模型应用落地的必需品,Html RAG、Multimodal RAG 和 Agentic RAG的区别是啥?检索-增强生成 (RAG) 是一个永不过时的话题,并在不断扩展以增强LLMs 的功能。对于那些不太熟悉RAG 的人来说:这种方法利用外部知识来增强模型的能力,从外部资源中检索您实际需要的信息。
来自主题: AI技术研报
7705 点击 2025-01-10 11:01