ChatGPT,取代工作or生产力神器?清华校友联手发文:AI时代怎么选工作
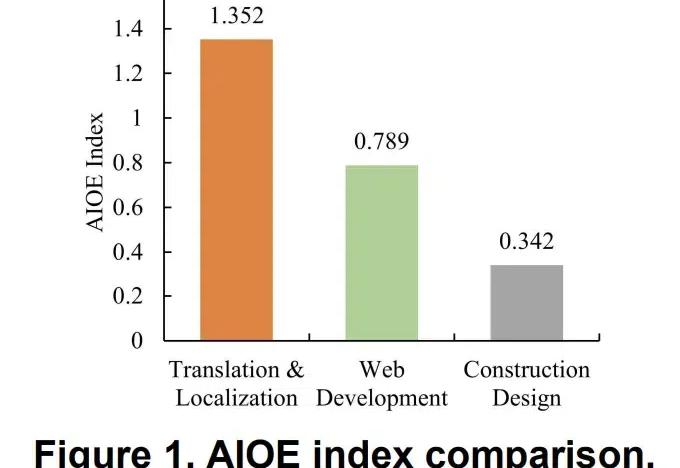
ChatGPT,取代工作or生产力神器?清华校友联手发文:AI时代怎么选工作清华校友团队最新成果发现:写作、咨询、编程等相关自由职业最终可能被AI取代,而且更关键的是,AI能力一旦超过某个「拐点」,对就业市场的冲击将一发不可收拾。
来自主题: AI技术研报
8409 点击 2025-01-12 17:04
 搜索
搜索
清华校友团队最新成果发现:写作、咨询、编程等相关自由职业最终可能被AI取代,而且更关键的是,AI能力一旦超过某个「拐点」,对就业市场的冲击将一发不可收拾。
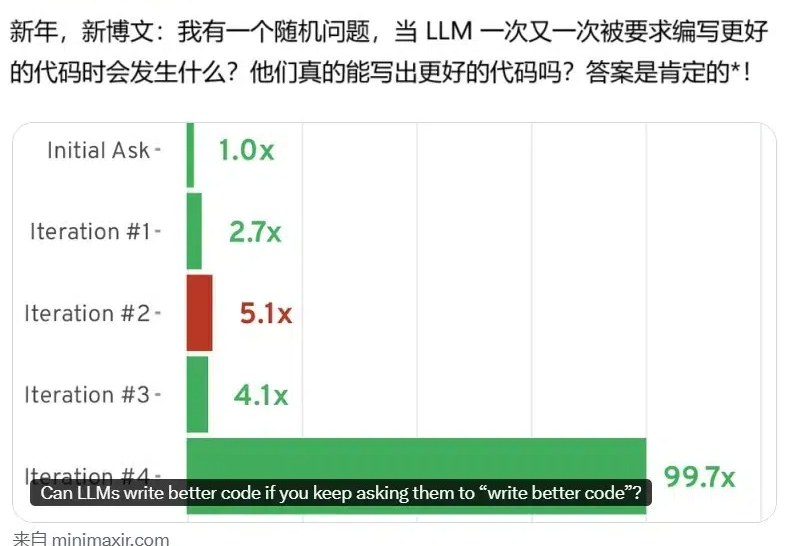
AI 的编程能力已经得到了证明,但还并不完美。近日,BuzzFeed 的资深数据科学家 Max Woolf 发现,如果通过提示词不断要求模型写更好的代码(write better code),AI 模型还真能写出更好的代码!

眼病诊疗,会迈上怎样的台阶? 用“手机看病”,这个听起来颇为科幻的场景,其实已经走进了现实。
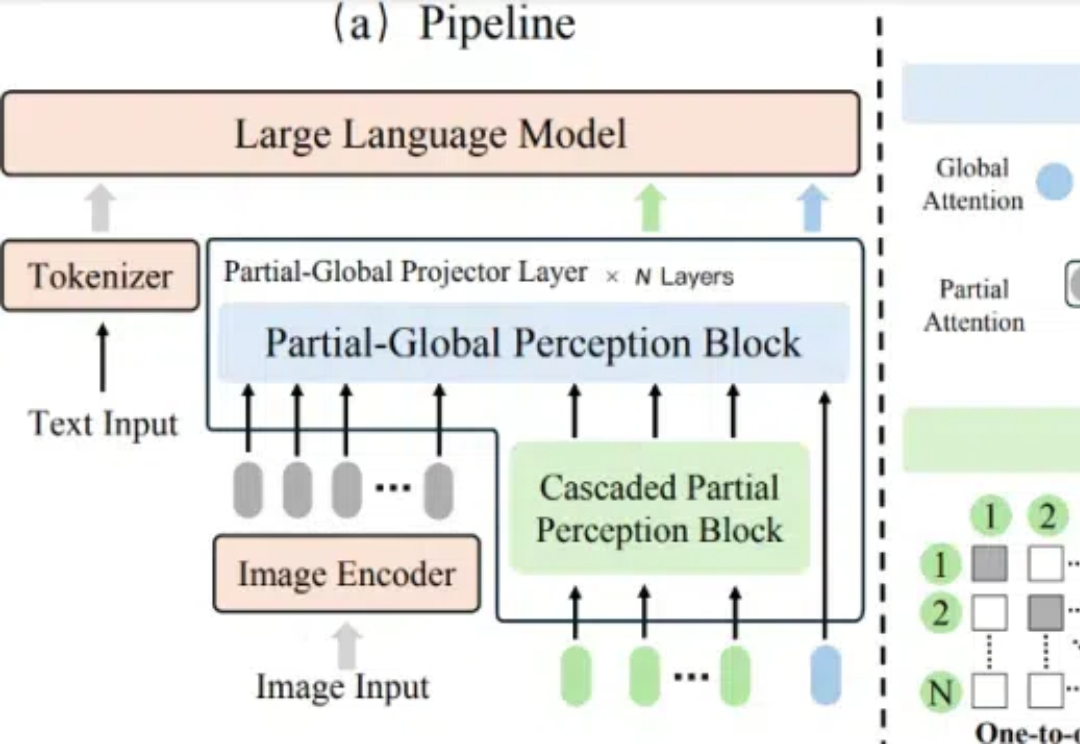
在多模态大语言模型(MLLMs)的发展中,视觉 - 语言连接器作为将视觉特征映射到 LLM 语言空间的关键组件,起到了桥梁作用。

大模型长序列的处理能力已越来越重要,像复杂长文本任务、多帧视频理解任务、以及 OpenAI 近期发布的 o1、o3 系列模型的高计算量模式,需要处理的输入 + 输出总 token 数从几万量级上升到了几百万量级。

搜索大变天?
OpenAI o1 给大模型规模扩展 vs 性能的曲线带来了一次上翘。它在大模型领域重现了当年 AlphaGo 强化学习的成功 —— 给越多算力,就输出越多智能,一直到超越人类水平。

论文能不能中?可以用AI提前预测~ 港大黄超教授团队提出多智能体自动化框架GraphAgent,能自动构建和解析知识图谱中的复杂语义网络,应对各类预测和生成任务。

1月8日,环球时报社、中国科协新技术开发中心和清华大学技术创新研究中心联合发布了50大“新质生产力产业实践示范案例”,华为云盘古大模型凭借在技术能力、应用实践等方面的突出表现,成功入选“人工智能”示范案例TOP5。

今天,银河通用机器人发布了端到端具身抓取基础大模型「GraspVLA」,全球第一个预训练完全基于仿真合成大数据的具身大模型,展现出了比OpenVLA、π0、RT-2、RDT等模型更全面强大的泛化性和真实场景实用潜力。