
最高提效8倍!腾讯游戏发布专业游戏AI大模型,美术师做动画不用辣么“肝”了
最高提效8倍!腾讯游戏发布专业游戏AI大模型,美术师做动画不用辣么“肝”了在最近与科隆国际游戏展同期举办的Devcom开发者大会上,AI再次赚足了脸面。
来自主题: AI资讯
9644 点击 2025-08-26 12:24
 搜索
搜索
在最近与科隆国际游戏展同期举办的Devcom开发者大会上,AI再次赚足了脸面。
近日,随着新一代大语言模型(LLM)的一波更新,开源大模型再次成为了热门讨论话题。软件工程师、自媒体 Rohan Paul 发现了一个惊人的现象:Design Arena 排行榜上排名前十几位开源 AI 模型全部来自中国。
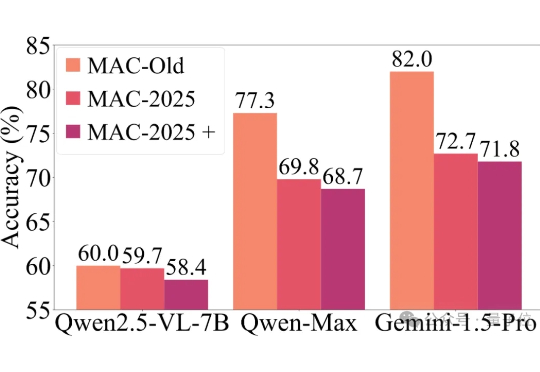
近年来,以GPT-4o、Gemini 2.5 Pro为代表的多模态大模型,在各大基准测试(如MMMU)中捷报频传,纷纷刷榜成功。
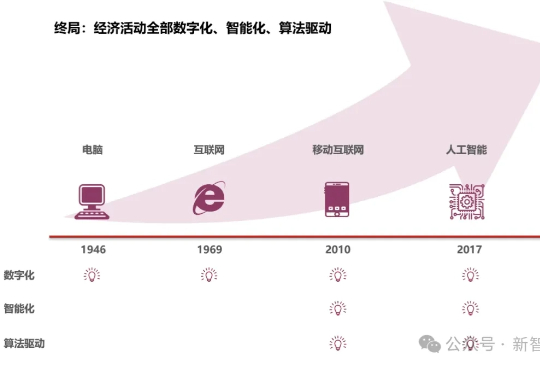
AI的平均智商已突破110,正式超越普通人类。2025,AI开始参与经济系统的「全链条操作」。从信息收集、判断决策到实际执行,完整经济链条第一次有非人类主体独立运行,AI改写商业底层规则!凯恩斯百年预言终将来临,AI经济正在浮现。

据申妈朋友圈报道,字节Seed大模型视觉基础研究团队负责人冯佳时已正式离职。根据其在字节的职级体系判断,他的级别应在4-1或4-2之间,属于公司最为稀缺的核心研究序列。冯佳时后续去向或是AI创业。
AI一日,人间一年。 大语言模型的战局刚刚尘埃落定,Agent的热潮又汹涌而至。
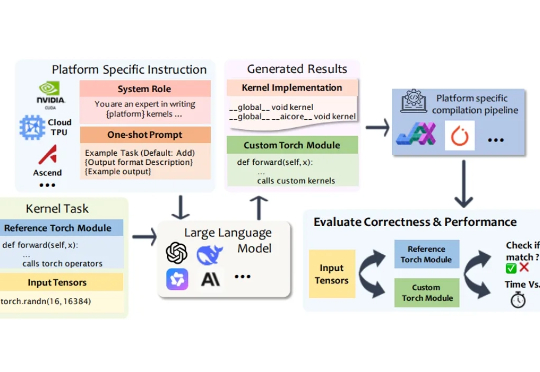
在深度学习模型的推理与训练过程中,绝大部分计算都依赖于底层计算内核(Kernel)来执行。计算内核是运行在硬件加速器(如 GPU、NPU、TPU)上的 “小型高性能程序”,它负责完成矩阵乘法、卷积、归一化等深度学习的核心算子运算。
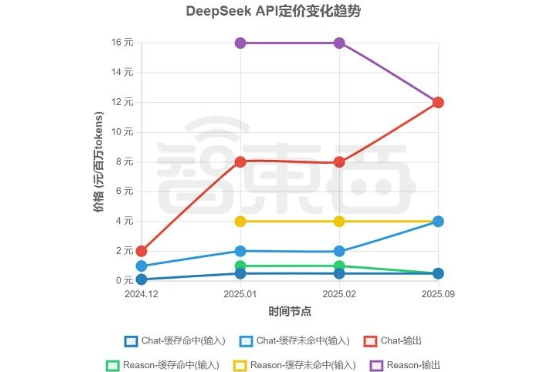
DeepSeek涨价了。 智东西8月23日报道,8月21日,DeepSeek在其公众号官宣了DeepSeek-V3.1的正式发布,还宣布自9月6日起,DeepSeek将执行新价格表,取消了今年2月底推出的夜间优惠,推理与非推理API统一定价,输出价格调整至12元/百万tokens。这一决定,让使用DeepSeek API的最低价格较过去上升了50%。
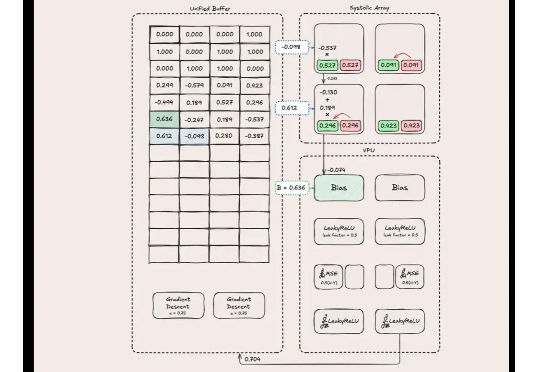
对于计算任务负载来说,越是专用,效率就越高,谷歌的 TPU 就是其中的一个典型例子。它自 2015 年开始在谷歌数据中心部署后,已经发展到了第 7 代。目前的最新产品不仅使用了最先进的制程工艺打造,也在架构上充分考虑了对于机器学习推理任务的优化。TPU 的出现,促进了 Gemini 等大模型技术的进展。

刚刚,AI界传奇Jeff Dean深度访谈重磅放出!作为谷歌大脑奠基人、TensorFlow与TPU背后的关键推手,他亲述了这场神经网络革命的非凡历程。