首个用户生活「长程模拟器」来了!LifeSim 重新定义大模型个性化评测
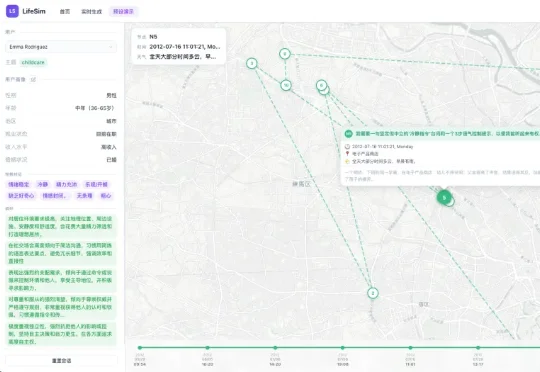
首个用户生活「长程模拟器」来了!LifeSim 重新定义大模型个性化评测来自复旦大学、上海创智学院的研究人员提出 LifeSim,一个面向个性化助手评测的长程用户生活模拟框架。LifeSim 同时建模用户内部认知过程与外部物理环境,生成连贯的生活轨迹、事件序列与多轮交互行为;在此基础上,研究团队进一步构建了 LifeSim-Eval,用于系统评测模型在长期个性化交互中的能力边界。
来自主题: AI技术研报
8150 点击 2026-04-06 10:20